一个1对多的业务场景,一个属性分库,另一个属性上的查询怎么办?
很多架构师会面临这样的业务场景,今天就以帖子中心为例,聊聊这里面的架构设计。
帖子中心,是互联网业务中,一类典型的“1对多”业务,即:一个用户能发布多个帖子,一个帖子只有一个发布者。
任何脱离业务的架构设计都是耍流氓,先来看看帖子中心对应的业务需求,再来考虑它的分库设计,与架构设计。
帖子中心,是一个提供帖子发布,修改,删除,查看,搜索的服务。

帖子中心,有什么写操作?
- 发布(insert)帖子;
- 修改(update)帖子;
- 删除(delete)帖子;
帖子中心,有什么读操作?
- 通过tid查询(select)帖子实体,单行查询;
- 通过uid查询(select)用户发布过的帖子,列表查询;
- 帖子检索(search),例如通过时间、标题、内容搜索符合条件的帖子;
在数据量较大,并发量较大的时候,架构如何设计?
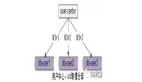
典型的,通常通过元数据与索引数据分离的架构设计方法。

架构中的几个关键点,如上图所示:
- tiezi-center:帖子服务;
- tiezi-db:提供元数据存储;
- tiezi-search:帖子搜索服务;
- tiezi-index:提供索引数据存储;
- MQ:tiezi-center与tiezi-search通讯媒介,一般不直接使用RPC调用,而是通过MQ对两个子系统解耦。
此时,读需求怎么满足?
tiezi-center和tiezi-search分别满足两类不同的读需求。

如上图所示:
- tid和uid上的查询需求,可以由tiezi-center从元数据读取并返回;
- 其他类检索需求,可以由tiezi-search从索引数据检索并返回;
写需求怎么办呢?

至于写需求,如上图所示:
- 增加,修改,删除的操作都会从tiezi-center发起;
- tiezi-center修改元数据;
- tiezi-center将信息修改通知发送给MQ;
- tiezi-search从MQ接受修改信息;
- tiezi-search修改索引数据;
tiezi-search,搜索架构不是本文的重点,不再展开,后文将重点描述帖子中心元数据水平切分设计。
帖子中心,数据库元数据如何设计?
帖子中心业务,很容易了解到,其核心元数据为:
t_tiezi(tid, uid, time, title, content, …);
其中:
- tid为帖子ID,主键;
- uid为用户ID,发帖人;
- time, title, content …等为帖子属性;
数据库设计上,在业务初期,单库就能满足元数据存储要求。

- tiezi-center:帖子中心服务,对调用者提供友好的RPC接口;
- tiezi-db:对帖子数据进行存储;
在相关字段上建立索引,就能满足相关业务需求。
- 帖子记录查询,通过tid查询,约占读请求量90%;
- 帖子列表查询,通过uid查询其发布的所有帖子,约占读请求量10%;
随着数据量越来越大,如何进行水平切分,对存储容量进行线性扩展呢?
方案一:帖子ID切分法
既然是帖子中心,并且帖子记录查询量占了总请求的90%,很容易想到通过tid字段取模来进行水平切分。

这个方法简单直接,优点:
- 100%写请求可以直接定位到库;
- 90%的读请求可以直接定位到库;
缺点也很明显:一个用户发布的所有帖子可能会落到不同的库上,10%的请求通过uid来查询会比较麻烦;

如上图,一个uid访问需要遍历所有库。
有没有一种切分方法,确保同一个用户发布的所有帖子都落在同一个库上,而在查询一个用户发布的所有帖子时,不需要去遍历所有的库呢?
方案二:Mapping映射法
使用uid来分库可以解决这个问题。
新的问题出现了:如果使用uid来分库,确保了一个用户的帖子数据落在同一个库上,那通过tid来查询,就不知道这个帖子落在哪个库上了,岂不是还需要遍历全库,需要怎么优化呢?
tid的查询是单行记录查询,只要在数据库(或者缓存)记录tid到uid的映射关系,就能解决这个问题。
新增一个索引库:
t_mapping(tid, uid);
- 这个库只有两列,可以承载很多数据;
- 即使数据量过大,索引库可以利用tid水平切分;
- 这类kv形式的索引结构,可以很好的利用cache优化查询性能;
- 一旦帖子发布,tid和uid的映射关系就不会发生变化,cache的命中率会非常高;
使用uid分库,并增加索引库记录tid到uid的映射关系之后,每当有uid上的查询,可以通过uid直接定位到库。

每当有tid上的查询,可以先查mapping表得到uid,再通过uid定位到库。

这个方法的优点是:
- 一个用户发布的所有帖子落在同一个库上;
- 10%的请求通过uid来查询列表,可以直接定位到库;
- 索引表cache命中率非常高,因为tid与uid的映射关系不会变;
缺点也很明显:
- 90%的tid请求,以及100%的修改请求,不能直接定位到库,需要先进行一次索引表的查询,当然这个查询非常快,通常在5ms内可以返回;
- 数据插入时需要操作元数据与索引表,可能引发潜在的一致性问题;
有没有一种方法,既能够通过uid定位到库,又不需要建立索引表来进行二次查询呢,使得uid和tid都能够直接一次命中的方案呢?
方案三:基因法
什么是分库基因?
通过uid分库,假设分为16个库,采用uid%16的方式来进行数据库路由,这里的uid%16,其本质是uid的最后4个bit决定这行数据落在哪个库上,这4个bit,就是分库基因。
什么是基因法分库?
在“1对多”的业务场景,使用“1”分库,在“多”的数据id生成时,id末端加入分库基因,就能同时满足“1”和“多”的分库查询需求。

如上图所示,uid=666的用户发布了一条帖子(666的二进制表示为:1010011010):
- 使用uid%16分库,决定这行数据要插入到哪个库中;
- 分库基因是uid的最后4个bit,即1010;
- 在生成tid时,先使用一种分布式ID生成算法生成前60bit(上图中绿色部分);
- 将分库基因加入到tid的最后4个bit(上图中粉色部分);
- 拼装成最终的64bit帖子tid(上图中蓝色部分);
这般,保证了同一个用户发布的所有帖子的tid,都落在同一个库上,tid的最后4个bit都相同,于是:
- 通过uid%16能够定位到库;
- 通过tid%16也能定位到库;
有人要问了,同一个uid发布的tid落在同一个库上,会不会出现数据不均衡?
只要uid是均衡的,每个用户发布的平均帖子数是均衡的,每个库的数据就是均衡的。
总结
将以“帖子中心”为典型的“1对多”类业务,在架构上,采用元数据与索引数据分离的架构设计方法:
- 帖子服务,元数据满足uid和tid的查询需求;
- 搜索服务,索引数据满足复杂搜索寻求;
对于元数据的存储,在数据量较大的情况下,有三种常见的切分方法:
- tid切分法,按照tid分库,同一个用户发布的帖子落在不同的库上,通过uid来查询要遍历所有库;
- Mapping映射法,按照uid分库,同一个用户发布的帖子落在同一个库上,需要通过索引表或者缓存来记录tid与uid的映射关系,通过tid来查询时,先查到uid,再通过uid定位库;
- 基因法,按照uid分库,在生成tid里加入uid上的分库基因,保证通过uid和tid都能直接定位到库;
知其然,知其所以然。
思路比结论更重要。