之前聊了《数据库双主一致性问题解决方案》,今天聊聊数据库主库与从库的一致性问题。

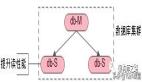
问:常见的数据库集群架构如何?
一主多从,主从同步,读写分离。

如上图:
- 一个主库提供写服务;
- 多个从库提供读服务,提升读性能;
- 主从之间同步数据;
问:为什么会出现不一致?
主从同步有时延,时延期间读从库,主从同步未完成,可能读到脏数据。
 图片
图片
任何数据冗余,必将引发一致性问题。
问:如何避免这种主从延时导致的不一致?
常见的方法有4种。
方案一:忽略。
任何脱离业务的架构设计都是耍流氓,绝大部分业务,例如:百度搜索,淘宝订单,QQ消息,58帖子都允许短时间不一致。
如果业务能够接受,别把系统架构搞得太复杂。
方案二:半同步复制
不一致是因为主从同步有一个时间差,是否能做到,等主从同步完成之后,主库上的写请求再返回呢?
这就是大家常说的半同步复制semi-sync。

- 1. 主库先执行写操作;
- 2. 等主从同步完成,写请求才返回;
- 3. 读从库,就能读到最新的数据;
这个方案的优点是,利用数据库原生功能,比较简单。不足是,主库的写请求时延会增加,吞吐量会降低。
方案三:强制读主。

如上图:
- 使用一个高可用主库提供数据库服务;
- 读和写都落到主库上;
- 采用缓存来提升系统读性能;
这是很常见的微服务架构,可以避免数据库主从一致性问题。
方案四:选择性读主。
强制读主过于粗暴,毕竟只有少量写请求,很短时间,可能读取到脏数据。
有没有可能实现,只有这一段时间,可能读到从库脏数据的读请求读主,平时读从呢?
可以利用一个缓存记录必须读主的数据。

如上图,当写请求发生时:
- 写主库;
- 将哪个库,哪个表,哪个主键三个信息拼装一个key设置到cache里,这条记录的超时时间,设置为“主从同步时延”;
画外音:key的格式为“db:table:PK”,假设主从延时为1s,这个key的cache超时时间也为1s。

如上图,当读请求发生时,这是要读哪个库,哪个表,哪个主键的数据呢,也将这三个信息拼装一个key,到cache里去查询,如果:
- cache里有这个key,说明1s内刚发生过写请求,数据库主从同步可能还没有完成,此时就应该去主库查询;
- cache里没有这个key,说明最近没有发生过写请求,此时就可以去从库查询;
以此,保证读到的一定不是不一致的脏数据。
总结
数据库主从不一致,四种常见优化方案:
- 忽略:业务可以接受,系统不优化;
- 半同步复制:复用原生能力,牺牲部分性能;
- 强制读主:高可用主库,用缓存提高读性能;
- 选择性读主:在cache里记录哪些记录发生过写请求,来路由读主还是读从;
知其然,知其所以然。
思路比结论更重要。