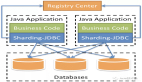
我们之前介绍一款轻量级的分库分表中间件sharding-jdbc,默认情况下该框架的分表算法都是采用内联表达式进行配置,对于某些比较灵活的需求无法实现,所以本文就以一个基于电话号码号头的案例介绍一下如何通过基于sharding-jdbc拓展点实现复杂分库分表算法。

一、详解自定义分表逻辑开发
1. 基于复杂发表算法的案例说明
我们的案例是为了采集不同地区的电话号码用户的信息,希望相同号头的电话号码会落到同一张分表上,例如我们现在有分表3张,有一个电话号码10658888,我们必须截取到1065和分表数进行取模运算得到分表名user_0:

2. 基于源码了解拓展点
我们直接定位到框架进行分库分表计算的代码段StandardRoutingEngine的routeTables,可以看到该方法会通过程序初始化加载好的shardingRule定位到当前分表策略:
查看getTableShardingStrategy方法可以看到,如果tableRule没有实现默认分表策略,则采用默认也就是我们配置的内敛策略defaultTableShardingStrategy ,反之返回我们自定义实现的分表策略:
此时我们可以推测tableShardingStrategy的配置就决定了我们是走内联表达式还是自定义类分表算法,通过源码的定位笔者发现tableShardingStrategy关于分表的配置来源于配置,在程序启动时tableShardingStrategy会根据yml的配置得到分表前缀如果是.table-strategy.standard.则说明当前程序采用的是自定义分表算法,就会基于这段配置定位到Java类生分表引擎:

对应的我们给出分表算法初始化的入口:
继续步进我们就可以直接定位到对应分表配置加载逻辑:
最终查看配置加载的swap就可以看到自定分表配置加载的逻辑可以看到,只要我们配置的是StandardShardingStrategyConfiguration前缀的配置,这段配置就会为我们生成自定义算法:
3. 配置与分表算法实现
基于上述源码,笔者得到对应配置前缀,我们开始进行自定义分库分表算法的配置步骤,首先自然是完成数据源的配置,如下所示,笔者自定义分表数据源名称为ds0,后续数据源信息配置的datasource后面都要拼上这个自定义的数据源名称ds0:
完成数据源基本配置后就到最重要分表核心配置了,对应选项含义分别是:
- actual-data-nodes:配置分库分表的库表区间,以笔者为例,配置为单库多表,对应的配置为ds0.user_$->{0..2},即ds0这个数据源下的user_0、user_1、user_2。
- precise-algorithm-class-name:指定分库分表的策略的实现类的全路径,以笔者为例包的全路径为com.sharkChili.algorithm.TableShardingAlgorithm。
- sharding-column:配置分片键,本文采用的是用户表的电话号码也就是phone字段。
- key-generator.column:该表的主键id为id。
- key-generator.type:id算法采用雪花算法。
如果我们希望打印分库分表执行SQL日志可以加上这条配置:
最后我们给出分表实现类,直接继承PreciseShardingAlgorithm并执行泛型为phone字典的类型String,通过截取电话号码头4位通过取模算法返回分表名称:
4. 自定义分表算法演示
最后我们给出插入的测试代码:
从日志可以看出,我们的插入数据定位到了分表0,与预期一致:
二、详解Sharding-JDBC几种分片策略
1. Sharding-JDBC分片策略概览
上述代码我们已经通过inline关键字指明基于表达式user_$->{id % 3}所实现的内联策略,通过该配置与之关联的关系类YamlShardingStrategyConfiguration我们可以看出,Sharding-JDBC总共一共了如下几种分片策略:
- standard:精确分片策略,即基于用户给定的单个分片键定位对应的库表。
- complex:复杂分片策略,即基于用户传入的多个字段定位对应的库表。
- hint:强制路由策略,比较少用,该策略用基于用户传参并结合路由策略实现类定位库表。
- inline:内联表达式,基于用户给定的分片键值和表达式获取对应的库表。
- none:无分片策略。
对应的我们给出YamlShardingStrategyConfiguration 的配置类印证这种说法:
2. 标准分片策略(范围分片)
我们先来说说标准分片策略,也就是我们上文所实现的自定义分片算法,这里我们介绍另一种基于范围分片的策略实现,如下所示,可以看到我们分片键为user表的id之后,指明range-algorithm-class-name即范围分片查询算法的实现类为TableRangeShardingAlgorithm:
对应我们也给出范围分片实现的算法实现类TableRangeShardingAlgorithm :
这里我们给出测试代码:
输出结果如下,可以看到定位到了0和3两个分表,与预期的逻辑一致:

需要补充的是范围分片和标准精准匹配的分片策略是兼容的,所以我们在标准分片的配置情况下可以同时实现两套算法针对不同维度的查询:
3. 复杂分片策略
涉及多字段条件的查询,sharding-jdbc同样提供了复杂分片策略配置,例如我们的分表查询算法的是基于id和age两个字段,那么我们就可以指明complex声明分片键为id和age,通过ComplexTableShardingAlgorithm实现分表逻辑:
这里为了简单演示复杂分片算法的实现和使用,笔者简单的取出多值查询中id和age各一个,然后定位到分表集合,对应逻辑如下,读者可以参考注释了解一下逻辑,对应的我们查询时只需传入id和age后就会走到该算法,这里就不多做结果演示了:
4. 强制路由策略
强制路由算是比较少用的分片策略,它的分表算法由用户自行实现且定位分表的逻辑与SQL语句没有任何关系,常用于系统维度的分表算法,所以配置时只需给出分表实现的策略类即可:
可以看到分表实现策略如下:
- 通过用户入参中获取逻辑分表
- 从入参出获取逻辑分表对应的value
基于上述两个值组装成分表:
hint算法是通过外部指定分片信息让分片策略决定路由最终指向,所以我们都是通过HintManager实例传入组装当前线程的逻辑表名和值从而定位到分表:
从输出结果就可以看出,我们通过传参实现参数驱动式的分片算法是成功的:

5. 行表达式分片算法
最后还有一种行表达式的分片策略算法,只需给定id并在配置给定分片算法即可,使用于简单的分表算法的实现:
三、小结
本文结合源码实现了解到sharding-jdbc自定义分表算法实现的拓展点,并基于该拓展点完成我们的的号头分表逻辑,希望对你有所帮助。