在数据爆炸的时代,分页查询已成为系统标配功能。但当面对亿级数据量时,传统的分页方式却可能成为压垮系统的最后一根稻草。本文将深入剖析Elasticsearch深度分页的成因,并提供常见的解决方案.
1.深度分页:你以为的翻页,其实是性能炸弹
分页机制剖析
当使用from+size进行分页时,Elasticsearch的处理流程暗藏隐患
处理流程
- 客户端请求第N页数据(from = 1000, size = 10)
- 协调节点向所有分片广播查询请求
- 每个分片在内存中计算排序,准备前1010条结果
- 合并所有分片返回的1010×分片数次数据
- 最终截取第1000-1010条数据返回客户端
性能灾难三宗罪
致命影响
- 内存黑洞:翻到第1000页时,单个分片需处理1000×size数据量
- 网络风暴:分片数×数据量的跨节点传输消耗
- 响应悬崖:页码超过max_result_window(默认1w)时直接报错
2.破局之道:Search After与Scroll API原理解析
Search After(游标分页核心原理)
技术本质
- 基于上一页最后一条记录的排序值进行分页
- 避免全局排序,仅保持单次查询的顺序一致性
- 时间复杂度稳定为O(size)
适用场景
- 移动端瀑布流浏览
- 后台连续分页查询
- 需要实时性的分页需求
Spring Boot实现
Scroll API(滚动查询)
核心原理
技术本质
- 创建查询的快照视图
- 通过保持搜索上下文实现批次获取
- 适合非实时的大数据量处理
适用场景
- 全量数据导出
- 离线数据分析
- 大数据迁移场景
Spring Boot实现
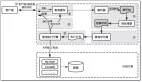
3.跳页难题解决方案
跳页问题本质剖析
技术挑战
- 无法直接定位到任意偏移量
- 传统分页方式性能不可接受
- 需要平衡准确性与性能
混合分页策略
跳页缓存层设计
4.性能优化全景方案
实测数据对比
分页方式 | 10页耗时 | 100页耗时 | 1000页耗时 | 内存消耗 |
From/Size | 120ms | 450ms | 超时失败 | 高 |
Search_After | 80ms | 85ms | 90ms | 低 |
Scroll | 100ms | 110ms | 120ms | 中 |
测试环境:3节点集群,单个索引10个分片,500万测试数据
5.最佳实践指南
前端设计原则
- 使用无限滚动替代传统分页
- 提供精准过滤条件
- 展示总条数范围而非精确值
后端防御策略
监控预警方案
当面对强制要求的精确跳页场景时,可考虑预计算+二级缓存方案。通过定时任务预先建立热点页的游标映射表,结合短时缓存实现快速跳转。您在实际项目中是如何解决这个难题的?