












作者 | hanzo
用说人话的方式讲解MCP。
目前各种MCP的文章和实际例子以及开源工具层出不穷,本文试图用最简单的方式解释下MCP解决什么问题和MCP怎么写的问题。

为啥要用MCP
MCP是一项专为LLM工具化操作设计的轻量化标准协议,其核心目标是构建LLM与异构软件系统间的通用指令交互框架。与传统的单一功能调用机制不同,MCP通过三层架构创新解决工具扩展性问题:
(1) 协议定位
作为中间协议层,MCP抽象出独立于具体LLM和业务系统的接口描述层,允许开发者在不同维度(功能权限、输入格式、执行环境)对工具接口进行灵活管控,避免传统方案中接口爆炸带来的维护难题。
(2) 技术架构
- 接口描述层:采用声明式DSL定义工具元数据,包括功能语义、入参Schema、权限策略和执行上下文
- 代理控制层:内置动态路由引擎和权限验证模块,支持热插拔式工具注册与版本管理
- 协议适配层:提供跨平台SDK,自动生成OpenAPI/Swagger等标准接口文档
(3) 核心优势
- 双向解耦:前端LLM无需感知具体工具实现,后端系统可独立迭代
- 权限纵深:细粒度控制工具可见性(开发者/用户/模型层级)
- 执行沙箱:支持Docker/WASM等多重运行时隔离方案
- 生态兼容:自带LangChain/LLamaIndex等主流框架的适配器
综合上述的专业表述,说人话就是,只要你的LLM有Prompt遵循能力,那么不管你是qwen,llama,DeepSeek还是claude ,都可以连接同样的MCP Server并且让你的LLM能够真正的调用工具,因此大大加速了LLM工具使用的开发速度。
为什么最近MCP爆发了?
最近大量MCP的爆发依赖于LLM本身两个能力的大幅度提升:1.结构化输出能力2.指令遵循能力。特别是claude3.7 sonnets之后的进展,使得工具的使用成功率大幅提升。对于LLM本身的能力进展来说,通过工具使用的方式积累真实世界的数据,并且进行后训练,也会成为LLM的垂直能力和LLM工作准确率进一步提升的关键。
MCP Server开发实战
有了基础概念之后,我们就可以直接开始一个MCP Server的开发了,目前MCP官方提供四种语言的开发SDK,包括Python,typescript,java和kotlin。我们以IEG最常用的typescript为例构建工程。
在开始前我们先明确一些概念,通常,我们编写的MCP是一个MCP Server,在Server中我们通常会定义一系列我们所需要的工具。使用各种LLM的客户端只要能连接上Server,就可以使用我们的MCP的各种工具调用能力了。
在UE开发中,UE废物一样的文档和天量的代码经常让人头大,那么能不能让LLM帮我来分析代码呢?结合Emacs常用的tree-sitter语法分析库和MCP,我们就可以用LLM来做这件事。
(本工程基于github:github.com/ayeletstu... 进行修改得来,由于原工程已经无法配置运行,我已经将修改后的代码传至 git.woa.com/IEG-RED-...)
首先,我们和普通配置NodeJs工程一样,在Package.json中添加相应依赖:
可以看到我们所需要的modelcontextprotocol sdk和tree-sitter等都可以直接从npm下载配置,我们按照常理执行npm install等步骤。接下来和通常的NodeJS程序一样,我们编写index.ts文件,先导入mcp相关的接口:
这里我们可以看到MCP的几个关键概念:
- Server:我们的MCP服务器,也就是处理一类任务的工具集合
- stdioServertransport:MCP默认用的通讯格式。
- RequestSchema:使用MCP时需要提供的参数,名字等等信息。
首先,我们需要定义一个Server class:
这里定义了我们的server的一些最常用的初始化流程和工具定义过程,因为我们是希望用MCP来分析代码,因此我们的CodeAnalyzer也属于我们的Server Class Member。
要定义工具,我们首先需要结合ListToolsRequestSchema来绑定我们的tools,参考下面的代码:
我们定义工具的名字,和工具所需要的输入,并将其绑定到server。这些信息会让MCP识别到我们需要调用到什么工具,并且在调用工具时,需要提供什么样的参数。
有了工具的名字和参数,MCP需要知道具体如何去执行我们想要的操作,比如分析C++类,搜索代码等等,这里就要用到callToolRequestSchema结构体:
很明显,callToolRequestSchema会将tools的名字和参数传给工具真正的执行者。在我们的Server内部定义的工具函数中,会调用tree-sitter cpp库 去进行真正的分析,然后将结果返回给我们的LLM进行总结。
来总结下, MCP的编写本身是非常简单的,我们需要实现的是定义工具的名字,参数(从LLM中自然语言的方式获取),以及用代码描述的真正执行工具的流程,并且将这些都绑定到我们的Server上,我们只需要关心我们在调用什么工具和我们需要什么数据就行了,至于给大模型的提示词,多轮对话暂存,格式化输出验证等需要考虑到问题,MCP的SDK都能帮我们搞定。
接下来我们用tsc编译我们的Nodejs程序,我们的Server就做好了。
使用MCP
读到这里细心的读者肯定会发现。我们的LLM在哪里?这就是MCP更重要的一个好处,它的Server是LLM无关的,只要客户端使用的LLM看得懂提示词,那么它就能使用同一个MCP Server。
接下来我们配置客户端来使用我们的MCP Server,目前很多软件,包括Claude desktop,dify等都支持了MCP,这里我们选择VSCode 的Cline插件作为客户端(因为他开源),安装和配置Cline的过程在此不再赘述,打开Cline的Setting,点击MCP Servers的按钮,我们会在下方看到一个Configure MCP Server的按钮,点击我们就可以打开我们的MCP设置Json:
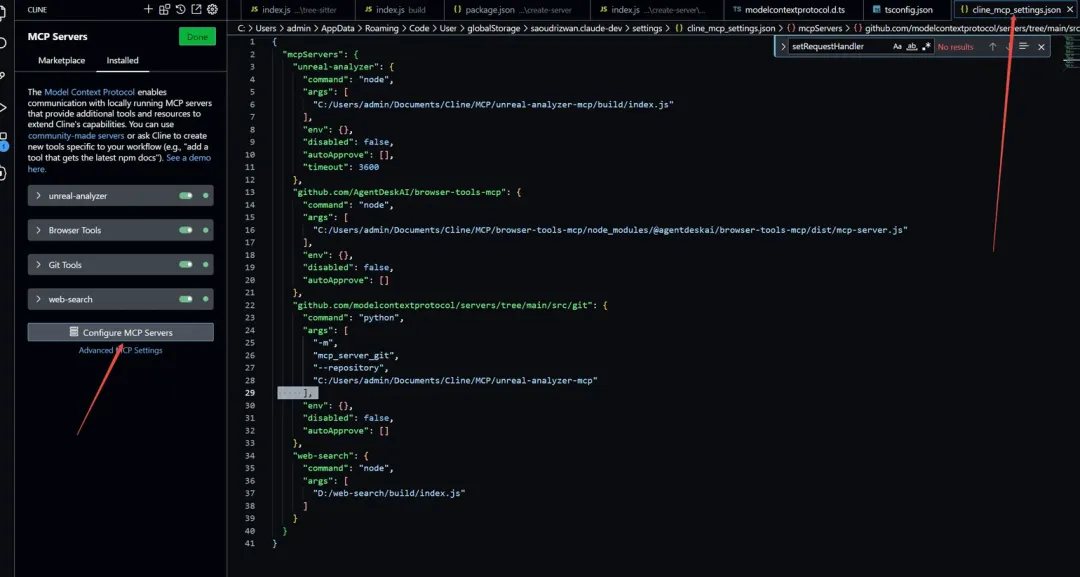
前文提到过,MCP支持多种语言开发,包括Python,Typescript等,因此可以看到我们的MCP配置中也支持多种入口,一个MCP Server的入口,可以是Python脚本,可以是bat批处理,也可以是nodejs程序的入口,对于我们的server来说,我们要配置的是一个nodejs的入口程序,如下面的代码:
我们将入口指向我们编译好的JavaScript文件,保存好之后,Cline就会自动去执行这个index.js,如果有运行错误,那么Cline的设置窗口中会报错,当出现下面的绿色按钮时,则证明我们的MCP Server连接成功了:
接下来,我们就可以用自然语言的方式快速分析UE代码了,我们在Cline的对话框中切换到Act Mode(只有Actmode可以调用MCP Server),然后按照我们日常和同事交流说话的口吻打字:先告诉他我们的UE代码在哪里:

直接说:我想分析下UMaterialExpressionPanner这个类,LLM会分析你的需求,自己去调用工具:

同时,LLM也会根据自己的思考去继续调用工具,比如我的这个问题,它会继续调用工具,去搜索代码:
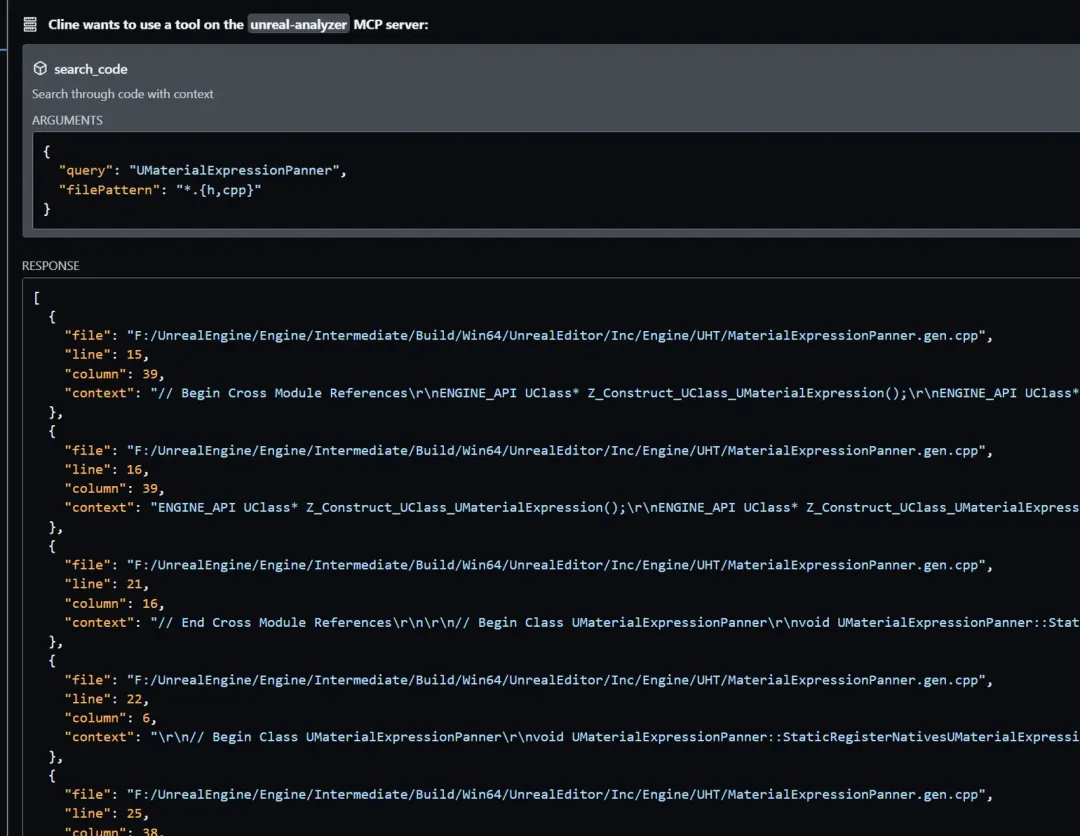
当他发现代码非常多的时候,它会考虑到:OK,我可能需要过滤一下代码,于是它会调用SearchWithContext的工具:

来个稍微复杂点的任务,让它帮我找找lumen里AO相关的类:
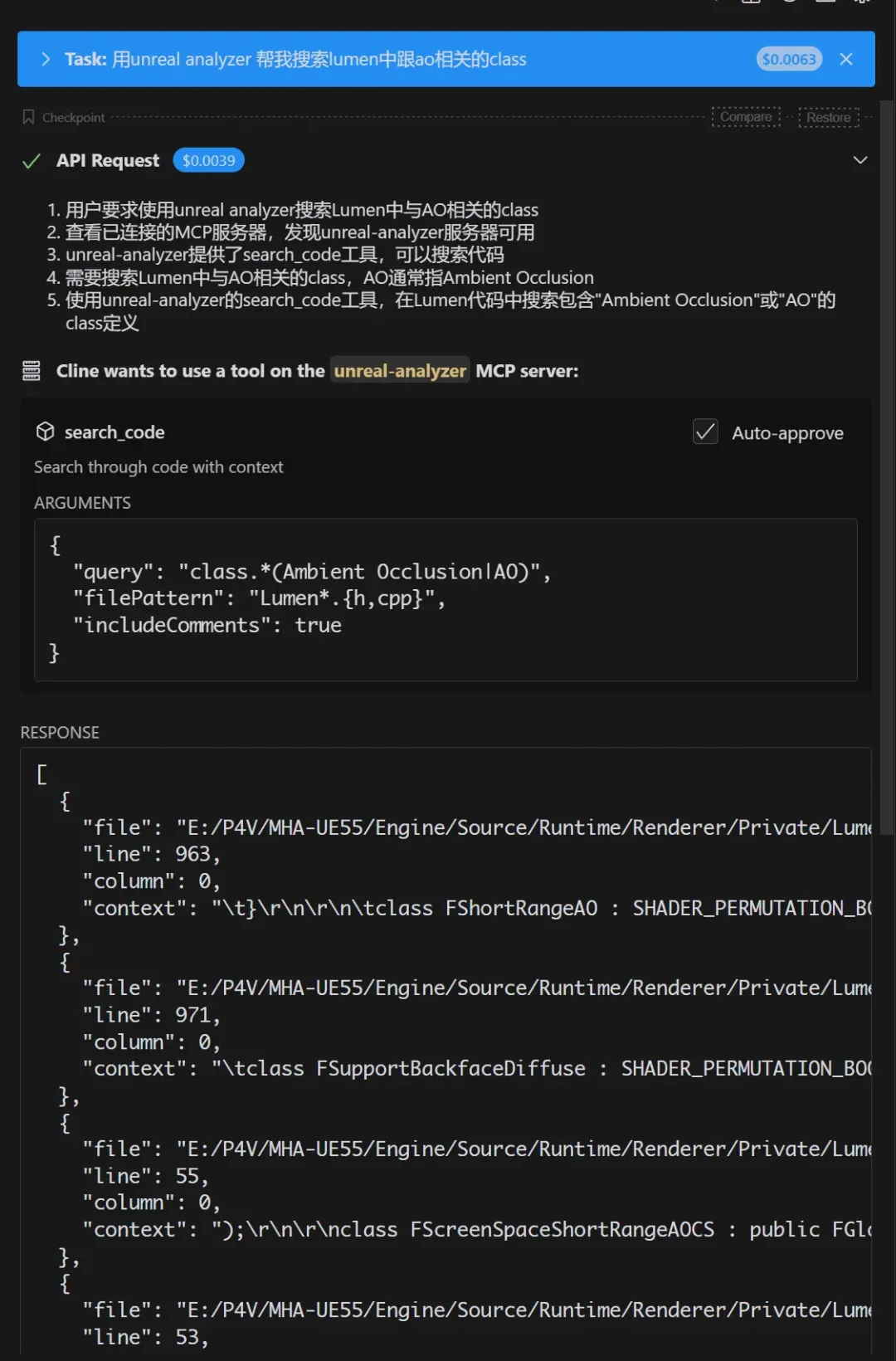

通过这个很简单的例子工程,我们可以总结出MCP的特点,MCP通过工程化的方法和统一的协议,给LLM装上了使用工具的手,这样我们的AI就可以真正的替我们干活。
真正的UnrealMCP实现
理解了MCP的工作逻辑和原理之后, 再开发垂直领域的MCP工具就会相对简单。接下来我们来分析下真正的能干活的UnrealMCP(github.com/kvick-gam...)是怎么工作的。同时也展示下Python SDK下的MCP工作流。
UnrealMCP由两部分组成,一部分是MCP Server的Python代码,一部分是UE5的插件,其中UE5的插件主要负责对接我们操作UE需要的一些C++逻辑。这部分的安装逻辑和通常的UE插件完全一样。
而MCP本身的部分,我们希望能够在Cline插件中调用,由于这个UnrealMCP只能在Claude中工作,而Claude在国内使用非常麻烦,因此在Cline中配置本MCP时,我们需要对仓库上说明的配置文件稍微进行些修改。 在运行安装python, 启动venv等工作之后,我们在配置Cline MCP的json时,需要按照如下代码配置:
这样就可以在Cline中使用UnrealMCP了。
使用上,UnrealMCP也是非常简单的,打开UE,启动UnrealMCP插件之后,我们告诉LLM我们的需求:在场景中创建一个迷宫关卡:

MCP会将相关信息包装成Python调用脚本,发给UnrealMCP Server:

我们就可以得到最终结果:

和之前的例子一样,开发UnrealMCP还是遵循定义工具名字,参数,定义行为的这几个步骤,在UnrealMCP中,它采用了:
- Python MCP 服务
- Python-C++ 桥接层
- C++ Unreal Engine 插件
的三层架构来实现(因为UE的EditorPython并不是很完善,所以需要通过C++插件来实现命令的解析和工作)。以最简单的CreateObject为例子: 首先,依然是注册工具和参数,当然,使用Python SDK,这个过程会更加直接简单,通过Python的注解语法来进行:
我们需要告诉UE我要创建的location和物体类型,接下来,用Python的socket通信封装一下LLM产生的数据,传给UE:
最后UE在C++插件中进行接受消息,去调用NewActor函数:
虽然整体流程复杂了些,但是可以看到,它依然遵循了MCP的设计范式,既通过Tools来扩展能力,告诉LLM,你可以去干什么事,然后用各种方法,将LLM分析自然语言后得出的指令转为工具调用,去做真正的工作。
MCP的局限性
MCP虽然非常简洁明了,大大方便了LLM Tool use的开发成本,但是从本质上来说,MCP只是解决了工具使用的可能性这一个主题,要想让AI真正干活,可以说MCP只是干活的那只手,我们同样需要大脑(规划Agent),记忆力(数据库,记事本)来共同辅助完成自动化的工作。
此外,对于真正的专业软件来说,每一个接口/功能对应MCP可能也是一个工程量不小的工作,MCP结合真正靠谱的Agent编程框架才有可能完成真正复杂的任务。
总结
本文通过两个案例,展示了MCP的整体开发逻辑和能力。通过MCP,大模型可以真正干活。但同时,MCP不应该被过度神话,它只是解决了工具调用这一系列的问题。要想让大模型彻底重塑日常的游戏开发工作流,还需要在流程,记忆力,以及模型本身的后训练上持续工作。


























