在大数据和高并发场景下,单机Redis的性能和容量逐渐捉襟见肘。如何实现数据的高可用、高扩展和高性能?Redis集群成为破局的关键。
1.Redis集群三大核心方案
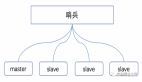
主从复制:简单冗余背后的「心跳危机」
- 全量复制与增量复制主从首次连接时触发全量复制:主节点通过BGSAVE生成RDB快照,同步期间新写入命令存入复制缓冲区。从节点清空旧数据加载RDB后,主节点推送缓冲区积压的增量命令完成同步。
- 致命缺陷:全量复制时主节点内存翻倍(生成RDB时fork子进程拷贝内存页表),若主节点内存达10GB,复制期间可能导致OOM崩溃。
- 级联复制缓解压力通过“主-从-从”架构分摊压力:指定高配从节点作为二级主节点,其他从节点向二级节点同步数据,避免主节点被多个从节点全量复制拖垮。
哨兵模式:高可用的「智能裁判」
- 主观下线与客观下线单个哨兵连续PING主节点超时(默认30秒)触发主观下线;当半数以上哨兵确认主节点故障,则升级为客观下线。
- 脑裂防护:通过quorum参数控制故障判定阈值(如3哨兵集群需2票确认),避免网络抖动误判。
- 领导者选举与故障转移哨兵节点通过Raft协议选举领导者,由领导者触发故障转移:
- 筛选健康从节点(数据同步偏移量最大者优先)
- 执行SLAVEOF NO ONE提升为新主节点
- 通知其他从节点切换主节点并更新客户端路由。
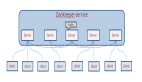
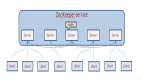
Redis Cluster:分布式架构的「终极答案」
数据分片:哈希槽的精密设计
- 16384槽位:采用CRC16算法计算键哈希值,取模16384确定槽位。槽位数量固定为16384(而非2的幂次)以降低元数据体积(仅需2KB存储槽分布)。
- 槽分配策略:支持手动指定(CLUSTER ADDSLOTS)或自动均衡,适用于异构硬件环境(如SSD节点分配更多槽)。
横向扩展:动态迁移的零停机艺术
- 新节点入群:redis-cli --cluster add-node将新节点加入集群
- 槽位重分配:redis-cli --cluster reshard交互式抽取旧节点槽位(如从3节点迁移4096槽至新节点)
- 原子迁移:逐个槽位迁移键值,期间客户端访问旧数据触发ASK重定向,新数据直接写入目标节点
- 元数据广播:通过Gossip协议同步新槽位分布至全集群。
迁移性能优化
- 并行迁移:通过--cluster-from和--cluster-to指定多组源/目标节点并行迁移不同槽位
- 带宽控制:redis-cli --cluster reshard时设置--cluster-pipeline参数限制批量传输大小。
故障自愈:主从切换的「无感体验」
- 主节点宕机时,其从节点触发选举(基于配置纪元递增),超过半数主节点投票后晋升为新主节点。客户端通过MOVED重定向自动切换连接,全程业务无感知。
2.集群搭建实战:从零到高可用
以Redis Cluster为例,6节点(3主3从)搭建步骤
配置节点
启动集群
验证集群状态
避坑指南:
- 端口开放:除服务端口(如7000)外,需开放集群总线端口(如17000)。
- 数据迁移:扩容时使用redis-cli --cluster reshard平滑迁移槽位,避免服务中断。
3.选型与优化:告别“拍脑袋”决策
方案对比
方案 | 可用性 | 扩展性 | 运维复杂度 | 适用场景 |
主从复制 | 中 | 低 | 简单 | 读多写少、容灾要求低 |
哨兵模式 | 高 | 中 | 中等 | 中小规模高可用 |
Redis Cluster | 极高 | 高 | 复杂 | 大数据量、高并发 |
性能优化技巧
- 热点数据:监控槽位负载,通过CLUSTER REBALANCE平衡数据分布。
- 内存控制:启用appendonly yes持久化,避免节点重启数据丢失。
- 网络优化:集群节点部署在同一机房,减少跨网络分区延迟。
4.Redis集群的典型应用场景
电商秒杀:集群分片扛住瞬时10万级QPS。
实时推荐:分布式缓存支撑用户画像实时计算。
社交feed流:海量数据分片存储,动态扩容应对用户增长。
5.小结
Redis集群是应对高并发、大数据的利器,但“没有银弹”——需根据业务特点选择方案。对于大多数企业,Redis Cluster是平衡性能与扩展性的最优解。如果你还在为单机Redis的性能焦虑,不妨从搭建一个3主3从的集群开始,迈向分布式缓存的新世界!