DeepSeek R1将模型训练推向基于强化学习的后训练新范式,让各行业也能快速构建行业高质量模型。后训练的核心主要在通过强化学习让模型涌现出自我验证、自我思考的长CoT(思维链)能力,让模型产生长CoT是后训练的推理任务,因此强化学习(RL)需要进行目标模型的训练和推理,而目标模型的推理和训练负载特征差异大,分离方案训练推理任务相互等待,资源利用率低。昇腾MindSpeed RL在后训练过程中采用训推共卡特性,让训练推理任务分时利用集群资源,降低训推切换时延和内存峰值,提升资源利用率和吞吐性能,是业界首个在大规模MoE模型RL训练上支持训推共卡。

强化学习后训练面临的挑战
强化学习的后训练是在预训练模型基础上,通过SFT微调和强化学习算法进一步优化模型行为,其核心思想是将模型的输出视为策略,利用奖励信号增强模型在特定领域的能力,只需少量高质量数据即可大幅增强模型“慢思考”推理能力,提升模型在数学、代码类等复杂逻辑推理中的表现。
强化学习RL后训练中存在Actor(即目标模型)的生成、Ref/Reward/Critic等辅助模型计算、Actor训练等。由于Actor模型训练推理计算任务、内存占用等负载特征差异大,需要采用不同并行策略才能实现较高系统吞吐。由于生成、推理、训练三个阶段需要串行执行,训练推理资源相互等待,存在大量模型级空泡,造成计算资源浪费,影响后训练的内存和吞吐性能。
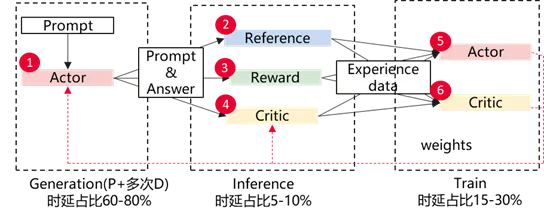
图1:基于强化学习的Actor后训生成、推理、训练三阶段示意
昇腾大规模MoE训推共卡强化学习
昇腾基于MindSpeed和vLLM开发训推共卡RL后训练方案,通过训推权重更新的通信优化算法、在线并行策略转换、训推共卡内存调度等特性,实现在同一集群上完成Actor模型的训练及推理高效协同,解决大规模MoE模型后训练在训推分离架构中权重更新时延高、硬件利用率低、并行策略转换OOM等问题。
支持训推权重更新的通信优化算法,时延降低50%
Actor模型训练推理最优并行策略不同,模型训练内存中存在优化器及梯度,内存占用大,需要采用更大的模型并行(TP、PP)才能完成训练。而推理中仅有模型权重为静态内存,仅需较小的模型并行(TP、PP)即可完成推理。模型权重更新切分的过程中存在大量数据同步的通信,通信时延高影响训推切换效率。昇腾训推权重更新的通信优化算法,降低训推切换中的权重同步时延50%。
支持在线并行策略转换,提升训推共卡系统资源利用40%
在MoE模型每一层的前向和反向计算中,各有两次All2All通信,共计四次All2All通信,称为Dispatch(F), Combine(F), Combine(B), Dispatch(B)。当模型专家数量较多,需要专家并行域(EP)来对专家进行EP并行切分,而采用vLLM等推理框架时不支持EP并行,因此训推切换时需要进行EP转TP。由于大规模MoE模型(如DeepSeek V3等)尺寸巨大(671B),仅权重就占据1.3TB内存(BF16),导致训推EP转TP过程存在较大OOM风险或面临资源不足,无法inplace转换。昇腾创新提出基于All2All的Direct EP2TP方案,在避免权重Resharding OOM的同时,实现高效权重转换。训推转换时进行在线EP转TP,大大提升vLLM推理引擎推理吞吐性能。在时延劣化小于5%条件下后训练系统所需卡数降低30%,系统资源利用率提升40%。
支持训推共卡内存调度,降低峰值内存10%,提升推理吞吐性能15%
训推共卡场景中,训练优化器状态、梯度占据大量内存,限制了推理阶段可用内存和系统吞吐。昇腾采用训推共卡内存调度,推理态将训练权重、优化器完全卸载至Host侧,增加推理态可用内存;推理态结束后则将训练优化器及梯度onload至NPU,完成模型训练,降低系统峰值内存10%,推理吞吐提升15%。
训推共卡强化学习特性使用方法
方法1:
用户在MindSpeed-RL目录下调用脚本MindSpeed-RL/cli/train_grpo.py

脚本路径:
https://gitee.com/ascend/MindSpeed-RL/blob/master/cli/train_grpo.py
方法2:
用户以模块导入的方式调用训推共卡特性
参考mindspeed_rl/workers/actor_hybrid_worker.py中initialize、_build_sharding_manager方法和mindspeed_rl/models/rollout/vllm_engine.py中offload_model_weights、sync_model_weights方法
脚本路径:
https://gitee.com/ascend/MindSpeed-RL/blob/master/mindspeed_rl/workers/actor_hybrid_worker.py
https://gitee.com/ascend/MindSpeed-RL/blob/master/mindspeed_rl/models/rollout/vllm_engine.py