出品 | 51CTO技术栈(微信号:blog51cto)
26日凌晨,OpenAI推出了GPT4o图像生成,可以说解决了此前Midjourney等扩散模型很难解决的问题,业内为之大为赞叹。

这是用手机拍摄的玻璃白板的广角图像,拍摄地点是一间俯瞰海湾大桥的房间。视野中可以看到一位女士正在写字,她身穿一件印有大型 OpenAI 标志的 T 恤。笔迹看起来很自然,但有点凌乱,我们可以看到摄影师的倒影。
现在,用户创建和自定义图像就像使用 GPT‑4o 聊天一样简单 - 只需描述需求,包括任何细节,例如纵横比、使用十六进制代码的精确颜色或透明背景。
 摄影师的自拍照,她转身和他击掌
摄影师的自拍照,她转身和他击掌
不过,OpenAI表示,由于此模型可以创建更详细的图片,因此图像渲染时间更长,通常长达一分钟。
有用的图像生成
当今的生成模型可以呈现超现实、令人惊叹的场景,但却无法处理人们用来分享和创建信息的主要图像。从徽标到图表,图像在添加指代共同语言和经验的符号后,可以传达精确的含义。
GPT‑4o 图像生成擅长准确渲染文本、精确遵循提示以及利用 4o 固有的知识库和聊天上下文(包括转换上传的图像或将其用作视觉灵感)。这些功能让您可以更轻松地创建您设想的图像,帮助您通过视觉效果更有效地进行交流,并将图像生成推进为一种精确而强大的实用工具。
增强功能:一图胜千言生成准确的文字,可代码编辑,强大的情景感知
据OpenAI官网介绍,根据在线图像和文本的联合分布训练模型,不仅学习图像与语言之间的关系,还学习图像与语言之间的关系。结合积极的后期训练,生成的模型具有令人惊讶的视觉流畅性,能够生成有用、一致且具有情境感知能力的图像。
文本渲染
一张图片胜过千言万语,但有时在正确的位置生成几个文字可以提升图像的含义。4o 将精确的符号与图像融合的能力将图像生成转变为视觉交流的工具。
多轮生成
由于图像生成现在是 GPT-4o 的原生功能,您可以通过自然对话来优化图像。GPT-4o 可以在聊天环境中基于图像和文本进行构建,从而确保始终保持一致性。例如,如果您正在设计视频游戏角色,那么在您进行优化和实验的过程中,该角色的外观在多次迭代中保持一致。
 原始图像
原始图像
 图给这只猫一顶侦探帽和一副单片眼镜
图给这只猫一顶侦探帽和一副单片眼镜

将其变成使用 4k 游戏引擎制作的 3A 视频游戏,并添加一些用户界面作为神秘 RPG 的覆盖,我们可以在顶部看到健康栏和小地图,在底部看到具有一致图像的咒语

更新为 16:9 比例的横向图像,在 UI 中添加更多咒语,并缩小视觉效果,以便我们以第三人称视角看到猫穿过蒸汽朋克曼哈顿,创造出美丽的对比度和灯光,就像在最好的三 A 游戏中一样,配以冷色调

当玩家打开菜单时创建界面,我们会看到猫的角色资料及其装备以及另一页显示活跃任务(并且它应该与我们在图像中描述的宇宙世界构建有关系)
遵循指令
GPT‑4o 的图像生成遵循详细的提示,注重细节。其他系统在处理约 5-8 个对象时会遇到困难,而 GPT‑4o 可以处理多达 10-20 个不同的对象。对象与其特征和关系的更紧密绑定可以实现更好的控制。
一张正方形图片,包含一个 4 行 4 列的网格,网格上有 16 个对象,背景为白色。从左到右,从上到下。列表如下:1. 一颗蓝色的星星2. 红色三角形3. 绿色正方形4. 粉色圆圈5. 橙色沙漏6. 紫色无限符号7. 黑白圆点领结8. 扎染“42”9. 一只戴着黑色棒球帽的橙色猫10. 一张带有宝箱的地图11. 一双活动眼珠12. 一个竖起大拇指的表情符号13. 一把剪刀14. 一只蓝白相间的长颈鹿15. 用草书写的“OpenAI”一词16. 一道彩虹色的闪电
 图片
图片
情境学习
GPT‑4o 可以分析和学习用户上传的图像,将其细节无缝集成到其上下文中以指导图像生成。
 图片
图片
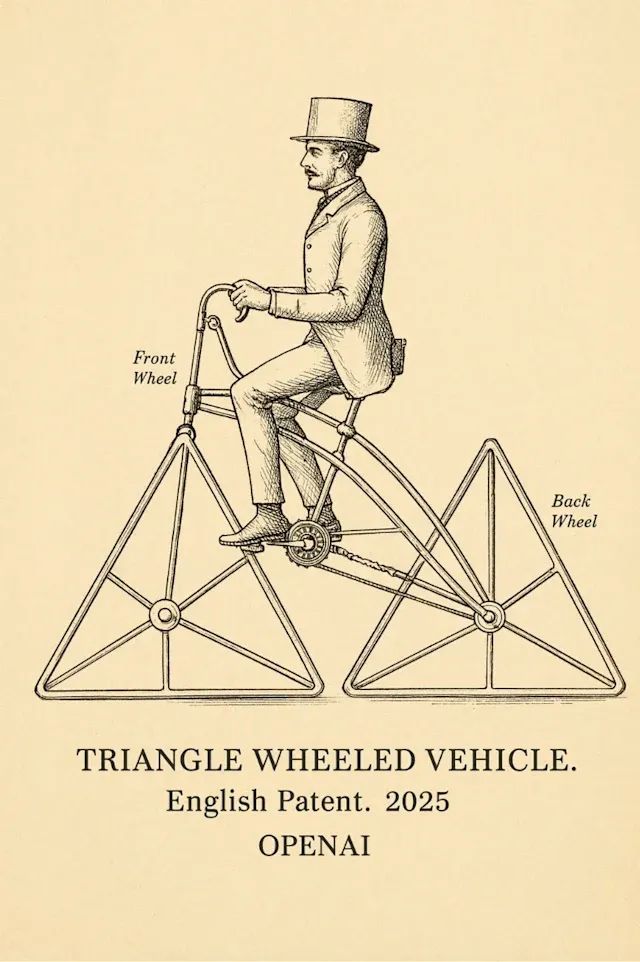
- 使用这些图像作为参考,绘制带有三角形车轮的车辆的设计图。
- 标记前轮、后轮,并在图表上写上(小写)
- 三角轮车辆。英文专利。2025. OPENAI。
现在把它放到一张在纽约市拍摄的照片中。
 图片
图片
世界知识原生图像生成使 4o 能够将其知识链接到文本和图像之间,从而产生一个感觉更智能、更高效的模型。
示例:可以通过代码来修改图像。
 图片
图片

照片写实主义和风格
通过对反映各种图像风格的图像进行训练,模型可以令人信服地创建或转换图像。

一种新型的图片生成方式
一位hackernews用户表示:关于这种新型图像生成方式,它通过代token而不是扩散来实现,重要的是它实际上是在像素空间中进行推理。例如:让它画一个带有空白井字棋格的记事本,然后告诉它先走一步,接着你走一步,如此循环。
你还可以进行一些非常令人印象深刻的、保留信息的转换,比如改变绘画风格,或者像“将白天变为夜晚”,或者“给他戴上一顶帽子”之类的操作。
“我感觉这些模型在分辨率方面相当受限,但在这个领域进一步的研究将让我们能够做出一些真正疯狂的事情,比如让模型分步骤完全用图像创建一个应用程序,本质上是用文字设计整个应用程序,包括文字内容等,然后生成代码来重现它。这也意味着一个模型可以接替一个优秀的扩散模型,即使最初的生成效果不佳,它也可以在外部图像上继续“推理”。”
最后,一旦这些模型的速度提升,你可以想象一个真正的生成式用户界面,模型根据发送给LLM的事件生成你正在使用的应用程序的下一帧(LLM可以像平时一样使用工具、思考等)。然而,我也相信扩散模型可以以更快的方式完成其中的一些任务。
甚至有网友晒出了一张被倒满的酒杯的生成图像来证明OpenAI攻克了很多业界不能突破的难题。
 图片
图片
今日即可访问和可用性
从今天开始,4o 图像生成将作为 ChatGPT 中的默认图像生成器向 Plus、Pro、Team 和 Free 用户推出,Enterprise 和 Edu 即将推出。它也可以在 Sora 中使用。对于那些对 DALL·E 情有独钟的人来说,仍然可以通过专用的 DALL·E GPT 访问它。
没错,免费用户也可以用,小编也尝鲜了一把。
同时,开发人员很快就能通过 API 使用 GPT-4o 生成图像,并将在未来几周内推出访问权限。
OpenAI在图片生成领域不是最早的,前有StableDifussion,后有Midjourney,但大模型的世界就是这么变幻莫测,OpenAI在图片领域这次可以说是成功逆袭了。