2025 年 3 月,Apache Kafka 迎来了具有划时代意义的 4.0 版本。这一版本不仅是技术架构的全面革新,更是功能场景的深度拓展。
码哥第一时间对 4.0 版本分析,为大家深度解读 Kafka 4.0 的核心特性,以下是码哥认为比较重要的特性:
- KRaft 全面替代 ZooKeeper
- 新一代消费者重平衡协议
- 点对点消息模型与共享组
- 移除旧协议 API 版本,提升系统性能
KRaft 全面替代 ZooKeeper
Apache Kafka 4.0 是一个重要的里程碑,标志着第一个完全无需 Apache ZooKeeper® 运行的主要版本。
通过默认运行在 KRaft 模式下,Kafka 简化了部署和管理,消除了维护单独 ZooKeeper 集群的复杂性。
这一变化显著降低了运营开销,增强了可扩展性,并简化了管理任务。
旧架构痛点回顾
在 Kafka 3.x 及更早版本中,ZooKeeper(ZK)是元数据管理的核心组件,负责 Broker 注册、Topic 分区分配、控制器选举等关键任务,如图所示。
 图片
图片
然而,这种设计存在显著问题:
- 运维复杂度高:需独立维护 ZK 集群,占用额外资源且增加故障点。
- 性能瓶颈明显:元数据操作依赖 ZK 的原子广播协议(ZAB),大规模集群(如万级分区)下元数据同步延迟可达秒级。
- 扩展性受限:ZK 的写性能随节点数增加而下降,限制 Kafka 集群规模。
KRaft 模式的技术实现
Apache Kafka Raft(KRaft)是在 KIP-500 中引入的共识协议,用于移除 Apache Kafka 对 ZooKeeper 进行元数据管理的依赖。这通过将元数据管理的责任集中在 Kafka 本身,而不是在两个不同的系统(ZooKeeper 和 Kafka)之间分割,从而大大简化了 Kafka 的架构。
KRaft 模式利用 Kafka 中的新法定多数控制器服务,取代了之前的控制器,并使用基于事件的 Raft 共识协议的变体。
 图片
图片
Kafka 4.0 默认启用KRaft 模式(Kafka Raft),完全摒弃 ZK 依赖。其核心原理如下:
- 元数据自管理:基于 Raft 共识算法,将元数据存储于内置的
__cluster_metadata主题中,由 Controller 节点(通过选举产生)统一管理。 - 日志复制机制:所有 Broker 作为 Raft 协议的 Follower,实时复制 Controller 的元数据日志,确保强一致性。
- 快照与恢复:定期生成元数据快照,避免日志无限增长,故障恢复时间从 ZK 时代的分钟级优化至秒级。
 图片
图片
我们可以看出 KRaft 替换 ZK,并不是元数据存储重新造轮子,而核心是集群协调机制的演进。
整个通信协调机制本质上是事件驱动模型,也就是 Metadata as an Event Log,Leader 通过 KRaft 生产权威的事件,Follower 和 Broker 通过监听 KRaft 来获得这些事件,并且顺序处理事件,达到集群状态和期望的最终一致。
新一代消费者重平衡协议
传统消费者组采用Eager Rebalance 协议,存在两大瓶颈:
- 全局同步屏障(Stop-the-World):任何成员变更(如扩容、故障)都会触发全组暂停,导致分钟级延迟。
- 扩展性差:消费者数量受限于分区数,万级消费者组重平衡耗时高达数分钟。
Kafka 4.0 引入增量式重平衡协议(KIP-848),核心改进包括:
- 协调逻辑转移:由 Broker 端的
GroupCoordinator统一调度,消费者仅需上报状态,无需全局同步。 - 增量分配:仅调整受影响的分区,未变更的分区可继续消费。
- 容错优化:局部故障仅触发局部重平衡,避免全组停机。
性能对比与实测数据
指标 | 旧协议(Eager) | 新协议(Incremental) |
重平衡延迟(万级组) | 60 秒 | <1 秒 |
资源消耗(CPU) | 高 | 降低 70% |
扩展上限 | 千级消费者 | 十万级消费者 |
Kafka 4.0 引入了一种强大的新消费者组协议,旨在显著提高重新平衡性能。
这种优化显著减少了停机时间和延迟,增强了消费者组的可靠性和响应性,尤其是在大规模部署中。
点对点消息模型与共享组
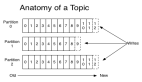
传统上,Kafka 主要采用发布-订阅模式,消费者组模式下,分区需与消费者一一绑定,如下图所示。
 图片
图片
无法实现多消费者协同处理同一分区消息,消费者数量不能超过分区数量——最多为一对一。
如下图所示,Consumer 5 无法处理 Topic 消息。
 图片
图片
而在某些特定场景下,如点对点的消息传递、任务分配等,传统的队列语义更具优势。
Kafka 4.0 通过引入“队列”功能,共享组(Share Group),允许多消费者同时处理同一分区消息,实现点对点消费模式。
 图片
图片
特性 | 传统消费者组 | 共享组 |
并行消费 | 分区数=消费者数 | 消费者数>分区数 |
消息确认 | 偏移量提交 | 逐条 ACK/NACK |
投递语义 | At-Least-Once | Exactly-Once(可选) |
主要特点:
- 支持传统队列场景:适用于需要保证消息严格顺序且仅由一个消费者处理的场景。
- 提升资源利用率:共享组机制使得多个消费者能够动态地共享分区资源,提高了系统资源的利用率和整体吞吐量。
- 简化架构设计:开发者无需在 Kafka 与其他专门的队列系统之间进行复杂的集成和数据迁移。
共享组(Share Group)机制
Kafka 4.0 通过共享组实现队列语义,关键技术包括:
- 多消费者协同消费:同一分区的消息可由多个消费者并行处理,突破分区数限制。
- 记录级锁机制:每条消息被消费时加锁(TTL 控制),防止重复处理。
- ACK/NACK 语义:支持逐条确认(Exactly-Once)或重试(At-Least-Once)。
移除旧协议 API 版本,提升系统性能
Kafka 一直以来都致力于兼容各个版本的协议 API,但随着时间的推移,维护大量旧版本的协议 API 带来了许多不必要的复杂性和成本。
在 Kafka 4.0 中,旧版本的协议 API 被彻底移除,系统基准协议直接提升至 Kafka 2.1 版本。
改进点:
- 简化代码:去除了历史包袱,简化了代码结构,统一
KafkaProducer与KafkaConsumer接口,减少冗余配置项,减少了测试难度。 - 提高性能:去除了对旧协议 API 的支持,使得系统性能得到了显著提升。废弃 Kafka 2.1 之前的所有 API(如
MessageFormatterv0)
值得注意的是,在 Kafka 4.0 中,Kafka 客户端和 Kafka Streams 需要 Java 11,而 Kafka Brokers,Connect 和工具现在需要 Java 17。
其他改进
Kafka 4.0 的其他新变化:
- 动态配置优化:
- 自动线程调整:
num.io.threads根据 CPU 核数动态分配,提升资源利用率。 - 时间窗口偏移量:支持从特定时间点(如 24 小时前)开始消费,替代固定偏移量。
- 安全性增强:OAuth 2.0 集成,支持基于 Token 的鉴权,替代 SASL/PLAIN;审计日志:记录所有元数据操作,满足金融级合规要求。
总结
Kafka 4.0 通过彻底摆脱 ZooKeeper,全面采用 KRaft 模式,不仅简化了部署和维护工作,还显著提升了系统的性能和稳定性。
同时,新一代消费者重平衡协议和队列功能的引入,为开发者提供了更为灵活和高效的消息处理模式。
这些架构革新使得 Kafka 4.0 成为了一个更加独立、高效和易用的分布式消息系统,为未来的发展奠定了坚实的基础。