一、缓存监控的背景
- 游戏业务中存在大量的高频请求尤其是对热门游戏而言,而应对高并发场景缓存是一个常见且有效的手段。
- 游戏业务中大量的采用远程缓存(Redis)和本地缓存(Caffeine)组合方式来应对大流量的场景。
- 在整个缓存使用的实践过程中,基于真实线上案例和日常缓存运维痛点沉淀了一些缓存监控治理的有效案例供分享。
二、远程缓存的监控介绍
2.1 监控的方案
2.1.1 监控目的
- 从宏观来讲监控本质目的是为了及时发现定位并解决问题,在成本可控的前提下监控维度尽可能丰富。
- 聚焦到 Redis 的维度,除了 Server 本身的监控指标(如请求量、连接数外),还需要监控更多偏业务的指标。
- Redis 目前最常见的问题包括:热点 Key 问题,大 Key 问题,超负载的大请求量问题。
- 聚焦上述的问题,在基于 Redis 的原生监控指标基础上,补充更多的包含业务属性的监控。
2.1.2 监控方案
- 目前从监控的维度进行分析,希望能做到既能针对某个 key 的热点监控,又能针对某一类相同前缀的 key 做聚合趋势监控。前者目的是发现热点 key,后者目的是从趋势维度监控缓存的实际访问量。
- Redis 的具体 key的监控由 Redis 自研团队集成到 redis server 侧实现监控,分类上归属为 Redis Server 侧的监控,这部分不在本篇分享中具体展开。
- Redis 的某类相同前缀的 key 的聚合监控由业务侧通过Aspect 拦截器拦截并上报埋点实现,其中 key 的设计需要遵循便于聚合的原则,分类上归属为 Redis 的业务侧的监控。
2.1.3 监控大盘

【Redis Server系统监控指标】
说明:
- 上图监控 Redis Server 的原生指标,具体可以参考 Redis 官方文档
http://doc.redisfans.com/server/info.html。 - 上述指标用来评估 Redis Server 本身的负载情况,并基于此考虑是否需要横向和纵向扩容。

【Redis 业务维度前缀监控指标】
说明:
- 上图监控的业务维度按照某类 key 的前缀进行聚合的指标,评估各类的 Redis 的 key 的读写指标。
- 上述指标用来评估业务对 Redis 缓存使用的合理性,如发现某个前缀 key 的写入量太大(缓存应该是读多写少场景)就需要思考缓存设计的合理性。
2.2 监控的实现
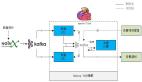
- 业务维度按照某类 key 的前缀进行聚合的功能,关键的实现逻辑包括:一类业务需要统一前缀 key 并在末尾拼接变量;通过切面拦截 redis 的读写并上报埋点。
- 统一前缀 key 是指:如果业务A是按照用户维度进行缓存 Key 的设计,那么 Key 的形态应该是 Prefix:UserId,Prefix 是业务场景的前缀,UserId 是用户维度的动态值。
- 切面拦截是指:针对指定的Redis操作(包括常见的 Set 等),进行拦截并匹配前缀进行埋点上报。
2.2.1 前缀 key 设计
Redis Key 的设计
左右滑动查看完整代码
说明:
- 在常量定义 RedisKeyConstants 中按照不同的业务区分了不同的业务场景的前缀 Key。
- 在 RedisUtils#buildRedisKey 中将业务的前缀和动态变化的参数进行拼接,中间通过分隔符进行连接。
- 分割符的引入是为了后续切面拦截时候进行逆向切割获取前缀使用。
2.2.2 监控实现
说明:
- 通过 Aspect 的切面功能对 Redis 的指定操作进行拦截,如上图中的 Set 操作等,可以按需扩展到其他操作(包括 get 命令等)。
- 针对前缀 key 的提取支持两个维度,默认场景和自定义场景,其中处理优先级为 自定义场景 > 默认场景
- 默认场景是指如 Redis 的 Key 为 A:B:C:UserId,从后往前寻找后向第一个分割符进行分割,A:B:C:UserId 分割后的根据前缀 A:B:C 进行聚合后数据埋点上报。
- 自定义场景如 Redis的 Key 为 A:B:UserId,通过配置自定义的前缀 A:B 来匹配,A:B:C:UserId 根据自定义的前缀分割后根据前缀 A:B 进行聚合后数据埋点上报。
- 考虑自定义场景的灵活性,相关的自定义前缀通过配置中心实时生效。
2.3 监控的案例
左右滑动查看完整代码
说明:
- 如监控实现部分所述,通过 Redis Key 的前缀聚合监控,能够发现某一类业务场景的 Redis 的写请求数,进而发现 Redis 的无效使用场景。
- 上述案例是典型的Redis的缓存使用场景:1.访问 Redis 缓存;2.若命中则直接返回结果;3、如未命中则查询持久化存储获取数据并写入 Redis 缓存。
- 从业务监控的大盘发现前缀 popup:user:plan 存在大量的 set 操作命令,按照缓存读多写少的原则,该场景标明该缓存的设计是无效的。
- 通过业务分析后,发现在游戏的业务场景中 用户维度+游戏维度 不存在5分钟重复访问缓存的场景,确认缓存的无效。
- 确认缓存无效后,删除相关的缓存逻辑,降低了 Redis Server 的负载后并进一步提升了接口的响应时间。
三、本地缓存的监控介绍
3.1 监控的方案
3.1.1 监控目的
- 从宏观来讲监控本质目的是为了及时发现定位并解决问题,在成本可控的前提下监控维度尽可能丰富。
- 聚焦到 Caffeine 的维度,监控指标包括缓存的请求次数、命中率,未命中率等指标。
- Caffeine 目前最常见的问题是:缓存设置不合理导致缓存穿透引发的系统问题。
3.1.2 监控方案
- 目前从监控的维度进行分析,按照机器维度+缓存实例进行监控指标采集,其中监控指标的采集基于 Caffeine 的 recordStats 功能开启。
- 基于 caffeine 的原生能力定制的 vivo-caffeine 集成了单机器维度+单缓存实例的指标数据的采集和上报功能。
- vivo-caffeine 上报的数据会按照单机器+单缓存实例维度进行大盘展示,支持全量指标的查询功能。
- vivo-caffeine 的上报的数据和公司级的告警功能相结合,例如针对缓存未命中率进行监控就能很快发现缓存穿透的问题。
3.1.3 监控大盘


【Caffeine 系统监控指标】
说明:
- vivo-caffeine 按照单机器 + 缓存实例维度进行监控数据的上报并进行展示。
- 所有的系统指标都支持查询并以图片的形式进行展示。
3.2 监控的实现
左右滑动查看完整代码
说明:
- Caffeine 的按缓存实例进行指标采集的前提是需要全局维护缓存实例和对应的 instanceName 之间的关联关系。
- Caffeine 在缓存创建的时候会设置实例的名称,通过 applyName 方法设置实例名称。
左右滑动查看完整代码
说明:
- 监控指标的采集基于 Caffeine 原生的统计功能 CacheStats。
- 所有采集的指标封装成一个统计对象 StatsData 进行上报。
左右滑动查看完整代码
说明:
- 每个应用单独的部署的服务作为一个采集点,进行指标的采集和上报。
- 采集过程是获取当前部署的应用下的所有缓存实例并进行指标的采集封装。
- 整体上报采用 Http 协议进行上报并最终展示到监控平台。
3.3 监控的案例

说明:
- 某次线上问题发生时发现突然多出了大量的 Redis 的请求,但是无法具体定位请求的 Redis 的前缀 key,设想如果接入了 Redis 的业务监控,问题来源就能很快定位。
- 在后续的问题排查中发现某个 Caffeine 的本地缓存因为大小设置过小导致大量的本地请求缓存穿透导致 Redis 的请求量突增,最终导致 Redis 的服务接近崩溃。
- 针对本地缓存穿透的场景,如果采用 Caffeine 的本地缓存监控方案,能够从缓存的命中率指标和缓存的未命中率指标突增突降中发现问题根源。
四、结束语
- 本篇内容是基于线上真实案例分享游戏业务侧在缓存监控治理方面的有效实践,监控治理本身是一个未雨绸缪的过程。在没有线上问题发生时看似不重要,但一旦发生无法快速定位问题又会导致问题的放大,因此完善的缓存监控整理其实是非常有必要的。
- Redis 的前缀 key 的监控思路是游戏业务服务端在优化Redis 的使用效率的过程中发现的一个较好的实践,逐步延伸后发现这是一个很好的监控手段,能够通过突增的趋势快速定位问题。
- 基于 Caffeine 的原生能力定制的监控指标采集是游戏业务服务端在探索 Caffeine 可视化过程中进行的一个探索落地,将整个缓存实例的运行态进行完整呈现,为业务稳定性贡献力量。
- 相信业内同仁会有更多更好的实践,相互分享共同进步,共勉。