














译者 | 朱先忠
审校 | 重楼
简介
最近,我们团队推出了LettuceDetect框架,这是一款用于检索增强生成(RAG)开发管道的轻量级幻觉检测器。它是一种基于ModernBERT模型构建的基于编码器的模型,根据MIT许可证发布,带有现成的Python包和预训练模型。
- 是什么:LettuceDetect是一个标记级检测器,可标记LLM回答中不受支持的片段。
- 如何使用:在RAGTruth(18k个样本)幻觉语料库上进行训练,利用ModernBERT模型实现长达4k个标记的上下文长度。
- 开发原因:它解决了(1)先前仅编码器模型中的上下文窗口限制;以及(2)基于LLM的检测器的高计算成本。
- 此框架的亮点主要体现在:
A.在RAGTruth幻觉语料库上击败了之前基于编码器的模型(例如Luna)。
B.尺寸仅为其一小部分,却超越了经过微调的Llama-2-13B(引文2),并且推理效率极高。
C.完全开源,遵循MIT许可证。
LettuceDetect框架通过发现LLM输出中的“过时的”部分来保持你的RAG框架一直最新。
快速链接
- GitHub:github.com/KRLabsOrg/LettuceDetect
- PyPI:pypi.org/project/lettucedetect
- arXiv论文:2502.17125
- Hugging Face模型:
A.基础模型
B.大型模型
- Streamlit演示程序:访问我们的Hugging Face空间或者是按照GitHub说明在本地运行。
为什么选择LettuceDetect?
时至今日,大型语言模型(LLM)在NLP任务中取得了长足进步,例如GPT-4(引文4)、Llama-3模型(引文5)或Mistral(引文6)(还有更多)。尽管LLM取得了成功,但幻觉仍然是在高风险场景(例如医疗保健或法律领域)中部署LLM的主要障碍(引文7和8)。
检索增强生成(RAG)技术尝试通过将LLM的响应建立在检索到的文档中来减轻幻觉,从而提供模型可以参考的外部知识(引文9)。但是,尽管RAG是减少幻觉的有效方法,但LLM在这些设置下仍然会受到幻觉的影响(引文1)。幻觉是指输出中的信息毫无意义、事实不正确或与检索到的上下文不一致(引文8)。Ji等人(引文10)将幻觉分为以下几类:
- 内在幻觉:源于模型先前存在的内部知识。
- 外在幻觉:当答案与所提供的上下文或参考资料相冲突时发生。
虽然RAG方法可以减轻内在幻觉,但它们并不能免受外在幻觉的影响。Sun等人(引文11)研究结果表明,模型倾向于优先考虑其内在知识而不是外部环境。由于LLM仍然容易产生幻觉,因此它们在医学或法律等关键领域的应用仍然可能存在缺陷。
幻觉检测的当前解决方案
当前的幻觉检测解决方案可以根据所采用的方法分为不同的类别:
- 基于提示的检测器:这些方法(例如RAGAS、Trulens、ARES)通常利用零样本或少量样本提示来检测幻觉。它们通常依赖于大型LLM(如GPT-4)并采用SelfCheckGPT(引文12)、LMvs.LM(引文13)或Chainpoll(引文14)等策略。虽然它们通常很有效,但由于重复调用LLM,计算成本可能很高。
- 微调LLM检测器:大型模型(例如Llama-2、Llama-3)可以进行微调以检测幻觉(引文1和15)。这可以产生高精度(如RAGTruth作者使用Llama-2-13B或RAG-HAT对Llama-3-8B所做的工作所示),但训练和部署需要大量资源。由于其规模较大且速度较慢,推理成本也往往较高。
- 基于编码器的检测器:Luna(引文2)等模型依赖于BERT样式的编码器(通常限制为512个标记)进行标记级分类。这些方法通常比在推理时运行完整的LLM更有效,但受到短上下文窗口和针对较小输入优化的注意机制的限制。
适用于长上下文的ModernBERT
ModernBERT(引文3)是BERT的直接替代品,它是一种先进的仅编码器的转换器架构,在原始BERT模型上融入了几项现代设计改进,例如它使用旋转位置嵌入(RoPe)来处理最多8,192个标记的序列,使用取消填充优化来消除填充标记上浪费的计算,使用GeGLU激活层来增强表现力,并使用交替注意力来实现更高效的注意力计算。
LettuceDetect利用ModernBERT的扩展上下文窗口构建用于幻觉检测的标记级分类器。这种方法避开了旧版基于BERT的模型的许多限制(例如,短上下文边界),并避免了大型基于LLM的检测器的推理开销。我们的实验表明,LettuceDetect的性能优于其他基于编码器的系统,同时仍能与经过微调的LLM检测器相媲美,而计算成本仅为后者的一小部分。
数据
RAGTruth是第一个大型开源(MIT许可证)基准,专门用于评估检索增强生成(RAG)设置中的幻觉检测。它包含18,000个带注释的样本,涵盖多个任务:
- 问答(QA):从MS MARCO数据集中抽样,其中每个问题最多检索三个文档,并提示LLM给出答案。
- 数据到文本生成:基于Yelp开放数据集,其中LLM为抽样企业生成评论。
- 新闻摘要:使用来自CNN/DailyMail的随机文档,促使LLM提供摘要。
其中,RAGTruth中的每个样本包括:
- 一个问题和一个提示;
- 一个或多个参考段落或上下文文档;
- LLM生成的响应;
- 跨度级别的人工注释,表明答案的任何部分是否没有事实依据或与参考段落相矛盾。
下面是来自RAGTruth的说明性样本,展示了幻觉的一个实例:
提出问题:
如何解释四分位数?
参考资料:
第2段:
第二四分位数(Q2)更常被称为中位数,它将数据分成两半(50%)。
中位数将数据分为下半部分和上半部分。
第三四分位数(Q3)也称为上四分位数,将数据的最低75%(或最高25%)分开。
(……)
回复如下:
第一个四分位数(Q1)将数据中最低的25%分成两部分,而第二个四分位数(Q2)将数据分成两个相等的部分,中位数是下半部分的中间值。最后,第三个四分位数(Q3)将数据中最高的75%分成两部分。
(……)
注解
跨度:“最高75%”
类型:明显冲突
原因:
原文:“最低75%(或最高25%)”
生成文本:“最高75%”
此样本展示了一个RAGTruth注释,涉及答案中与参考段落相冲突的特定跨度,提供了幻觉的类型(例如,明显冲突)和人类可读的理由。我们的方法仅使用二进制注释,而不使用幻觉注释的类型。
方法
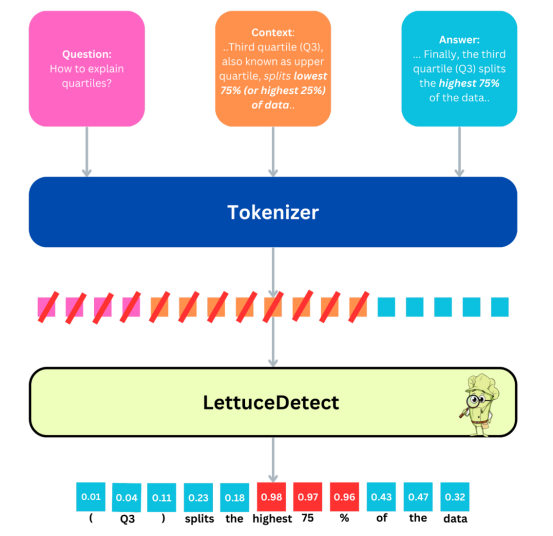
作者自制图片
这里给出的是LettuceDetect架构的一种高级描述。这里,给出了一个样本问题、上下文和答案三元组。首先,对文本进行标记,然后LettuceDetect执行标记级分类。问题和上下文中的标记都被屏蔽(图中用红线表示),以便将它们排除在损失函数之外。答案中的每个标记都会收到一个概率,表明它是幻觉的还是被支持的。对于跨度级检测,我们将幻觉概率高于0.5的连续标记合并为单个预测跨度。
我们在RAGTruth数据集上训练ModernBERT-base和ModernBERT-large变体作为标记分类模型。模型的输入是Context、Question和Answer段的串联,带有专门的标记([CLS])(用于上下文)和([SEP])(作为分隔符)。为了便于计算,我们将序列长度限制为4,096个标记,但ModernBERT理论上最多可以处理8,192个标记。
标记化和数据处理
- 标记化:我们使用转换器库中的AutoTokenizer来处理子词标记化,并适当地插入[CLS]和[SEP]。
- 标签:
A.上下文/问题标记被屏蔽(即在PyTorch中分配-100的标签),因此它们不会导致损失。
B.每个答案标记都会收到一个标签0(支持)或1(幻觉)。
模型架构
我们的模型基于Hugging Face的AutoModelForTokenClassification构建,使用ModernBERT作为编码器,并在其上设置分类头。与之前一些基于编码器的方法(例如,在NLI任务上进行预训练的方法)不同,我们的方法仅使用ModernBERT,没有额外的预训练阶段。
训练配置
- 优化器:AdamW,学习率为1*10^-5,权重衰减为0.01。
- 硬件:单个NVIDIA A100 GPU。
- 世代(Epochs):总共6个训练世代。
- 批处理:
A.批次大小为8;
B.使用PyTorch DataLoader加载数据(启用数据混洗功能);
C.通过DataCollatorForTokenClassification进行动态填充,以有效处理可变长度序列。
在训练期间,我们会监控验证拆分中的符号级F1分数,并使用safetensors格式保存检查点。训练完成后,我们会将表现最佳的模型上传到Hugging Face供公众访问。
在推理时,模型会输出答案中每个标记的幻觉概率。我们聚合超过0.5阈值的连续标记以生成跨度级预测,准确指示答案的哪些部分可能产生幻觉。上图说明了此工作流程。
接下来,我们对模型的性能进行更详细的评估。
测试结果
我们在RAGTruth测试集上对所有任务类型(问答、数据转文本和摘要)的模型进行了评估。对于每个示例,RAGTruth都包含手动注释的跨度,以指示幻觉内容。
示例级结果
我们首先评估样本级别的问题:生成的答案是否包含任何幻觉?我们的大型模型(lettucedetect-large-v1)的总体F1得分达到79.22%,超过了:
- GPT-4(63.4%);
- Luna(65.4%)(之前最先进的基于编码器的模型);
- RAGTruth论文中提出了经过微调的Llama-2-13B(78.7%)。
它仅次于RAG-HAT论文(引文15)中经过微调的Llama-3-8B(83.9%),但LettuceDetect明显更小,运行速度更快。同时,我们的基础模型(lettucedetect-base-v1)在使用较少参数的情况下仍保持了极高的竞争力。
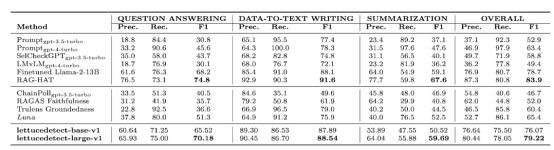
作者本人提供图片
上表是一张比较表,说明了LettuceDetect与基于提示的方法(例如GPT-4)和基于编码器的替代解决方案(例如Luna)的对比情况。总体而言,lettucedetect-large-v1和lettucedect-base-v1是性能非常出色的模型,同时在推理设置中也非常有效。
跨度级结果
除了检测答案是否包含幻觉之外,我们还检查了LettuceDetect识别不支持内容的确切跨度的能力。在这里,LettuceDetect在报告跨度级别性能的模型中取得了最先进的结果,大大优于RAGTruth论文(引文1)和其他基线中经过微调的Llama-2-13B模型。

作者本人提供图片
大多数方法(例如RAG-HAT(引文15))都没有报告跨度级指标,因此我们在这里不与它们进行比较。
推理效率
lettucedetect-base-v1和lettucedetect-large-v1所需的参数都比典型的基于LLM的检测器(例如GPT-4或Llama-3-8B)少,并且可以在单个NVIDIA A100 GPU上每秒处理30-60个样本。这使得它们适用于工业工作负载、实时面向用户的系统和资源受限的环境。
总体而言,这些结果表明LettuceDetect具有良好的平衡性:与基于LLM的大型评判系统相比,它以极小的规模和成本实现了接近最先进的准确度,同时提供了精确的标记级幻觉检测。
开发实战
安装软件包:
然后,你可以按如下方式使用该包:
结论
我们在本文中详细介绍了我们团队研发的LettuceDetect,这是一个轻量级且高效的RAG系统幻觉检测框架。通过利用ModernBERT的扩展上下文功能,我们的模型在RAGTruth基准上实现了强劲的性能,同时保持了较高的推理效率。这项工作为未来的研究方向奠定了基础,例如扩展到其他数据集、支持多种语言以及探索更先进的架构。即使在这个阶段,LettuceDetect也证明了使用精简的、专门构建的基于编码器的模型可以实现有效的幻觉检测。
引文
【1】Niu等人,2024,RAGTruth: A Dataset for Hallucination Detection in Retrieval-Augmented Generation(RAGTruth:检索增强生成中的幻觉检测数据集)。
【2】Luna: A Simple and Effective Encoder-Based Model for Hallucination Detection in Retrieval-Augmented Generation(Luna:一种简单有效的基于编码器的检索增强生成幻觉检测模型)。
【3】ModernBERT: A Modern BERT Model for Long-Context Processing(ModernBERT:用于长上下文处理的现代BERT模型)。
【4】GPT-4 report(GPT-4报告)。
【5】Llama-3 report(Llama-3报告)。
【6】Mistral 7B。
【7】Kaddour等人,2023,Challenges and Applications of Large Language Models(大型语言模型的挑战与应用)。
【8】Huang等人,2025,A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions(大型语言模型中的幻觉调查:原理、分类、挑战和未决问题)。
【9】Gao等人,2024,Retrieval-Augmented Generation for Large Language Models: A Survey(大型语言模型的检索增强生成:一项调查)。
【10】Ji等人,2023,Survey of Hallucination in Natural Language Generation(自然语言生成中的幻觉研究)。
【11】Sun等人,2025,ReDeEP: Detecting Hallucination in Retrieval-Augmented Generation via Mechanistic Interpretability(ReDeEP:通过机械可解释性检测检索增强生成中的幻觉)。
【12】Manakul等人,2023,SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models(SelfCheckGPT:用于生成大型语言模型的零资源黑盒幻觉检测)。
【13】Cohen等人,2023,LM vs LM: Detecting Factual Errors via Cross Examination(LM vs LM:通过交叉询问检测事实错误)。
【14】Friel等人,2023,Chainpoll: A high efficacy method for LLM hallucination detection(Chainpoll:一种高效的LLM幻觉检测方法)。
【15】Song等人,2024,RAG-HAT: A Hallucination-Aware Tuning Pipeline for {LLM} in Retrieval-Augmented Generation(RAG-HAT:检索增强生成中用于LLM的幻觉感知调整管道)。
【16】Devlin等人,2019,BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding(BERT:用于语言理解的深度双向Transformer预训练)。
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:LettuceDetect: A Hallucination Detection Framework for RAG Applications,作者:Adam Kovacs
























