写在前面 & 笔者的个人理解
OpenAI o1 和 DeepSeek R1 在数学和科学等复杂领域达到了或甚至超越了人类专家的水平,强化学习(RL)和推理在其中发挥了关键作用。在自动驾驶领域,最近的端到端模型极大地提高了规划性能,但由于常识和推理能力有限,仍然难以应对长尾问题。
一些研究将视觉-语言模型(VLMs)集成到自动驾驶中,但它们通常依赖于预训练模型,并在驾驶数据上进行简单的监督微调(SFT),没有进一步探索专门为规划设计的训练策略或优化方法。本文提出了 AlphaDrive,一个针对自动驾驶中 VLMs 的 RL 和推理框架。AlphaDrive 引入了四个基于 GRPO 的 RL 奖励,专门用于规划,并采用结合 SFT 与 RL 的两阶段规划推理训练策略。结果表明,与仅使用 SFT 或不进行推理相比,AlphaDrive 显著提升了规划性能和训练效率。此外,我们还兴奋地发现,在 RL 训练之后,AlphaDrive 展现出了一些新兴的多模态规划能力,这对提高驾驶安全性和效率至关重要。据我们所知,AlphaDrive 是首个将基于 GRPO 的 RL 与规划推理集成到自动驾驶中的框架。代码将被发布以促进未来的研究。
- 论文链接:https://arxiv.org/abs/2503.07608
- 代码链接:https://github.com/hustvl/AlphaDrive

引言
近年来,自动驾驶技术取得了快速进展,端到端自动驾驶成为最具代表性的模型之一。这些模型以传感器数据为输入,利用可学习的神经网络规划车辆未来轨迹。得益于大规模驾驶演示数据,端到端模型通过扩展训练数据和增加模型参数持续改进规划能力。然而,由于其黑箱特性与常识推理能力的缺失,端到端模型在处理复杂和长尾驾驶场景时仍面临重大挑战。例如,当前方车辆携带交通锥行驶时,端到端模型可能无法理解前车与交通锥的关系,误判道路施工不可通行,从而做出错误的制动决策。因此,仅依赖端到端模型实现高级别自动驾驶仍存在显著局限性。
随着GPT的成功,大型语言模型(LLMs)展现出卓越的理解与推理能力,并逐步从单模态文本理解扩展到多模态视觉-语言处理。视觉-语言模型(VLMs)的常识与推理能力为缓解端到端模型的缺陷提供了潜在解决方案。
近期,OpenAI o1通过集成推理技术,在编程等领域达到甚至超越人类专家水平。DeepSeek R1则利用强化学习(RL),不仅展现出“涌现能力”并取得顶尖性能,且训练成本显著低于其他模型。这些进展凸显了推理技术与强化学习在大型模型开发中的巨大潜力。
现有将VLMs应用于自动驾驶的研究可分为两类:
- 驾驶场景理解:利用VLMs解析场景语义;
- 规划决策:部分研究将VLMs作为端到端系统,直接根据输入图像生成轨迹。然而,与专为轨迹规划设计的端到端模型不同,VLMs的输出空间为离散语言符号,难以直接生成精确数值预测,可能导致性能不足或安全隐患。
部分研究尝试通过自然语言描述高层动作(如“减速右转”)规避上述问题,但仍缺乏对训练方法的深入探索。多数工作仅依赖监督微调(SFT),忽视了不同训练策略对规划性能与训练效率的影响。
本文探讨以下核心问题:如何将强化学习与推理技术(在通用大模型中取得显著成功的方法)应用于自动驾驶规划,以提升VLMs的性能并降低训练成本?
通过初步实验,我们发现直接应用现有RL与推理技术效果欠佳,主要归因于以下三方面:
- 奖励设计不匹配:通用任务的RL奖励(如视觉计数任务的正确性判断)难以适应规划需求。自动驾驶中,不同驾驶行为的重要性差异显著(如制动与加速),需设计权重差异化的奖励机制。
- 多解性挑战:规划问题通常存在多个合理解(如直行道路可选择匀速或加速),需避免强制对齐单一真值标签。
- 推理数据匮乏:自动驾驶缺乏现成的规划推理数据集,人工标注成本高昂,直接应用现有推理技术困难。
针对上述挑战,本文提出AlphaDrive——首个将基于GRPO的强化学习与规划推理集成到自动驾驶的框架。具体贡献如下:
- GRPO强化学习策略:采用Group Relative Policy Optimization(GRPO),相比PPO和DPO,其组间相对优化策略更适配规划的多解性,实验表明GRPO训练的模型展现出涌现的多模态规划能力。
- 四维奖励设计:
- 规划准确性奖励:基于F1分数评估横向(方向)与纵向(速度)决策一致性;
- 动作加权奖励:根据安全关键性为不同动作分配权重(如制动权重高于匀速);
- 规划多样性奖励:鼓励生成多样化可行解,防止模式坍缩;
- 格式规范奖励:强制输出结构化格式(如
<answer>标签),提升训练稳定性。
- 两阶段训练范式:
阶段一(SFT知识蒸馏):利用大模型(如GPT-4o)生成高质量规划推理数据,通过SFT实现推理过程蒸馏;
阶段二(RL探索):在SFT基础上进行RL微调,缓解早期训练的不稳定性和幻觉问题。
实验表明,与仅使用SFT或无推理的模型相比,AlphaDrive在规划准确率上提升25.52%,且在仅20%训练数据下性能超越SFT模型35.31%。此外,RL训练后模型涌现出多模态规划能力(如复杂场景生成多个合理决策),为提升驾驶安全与效率提供了新方向。据我们所知,AlphaDrive是首个将GRPO-based RL与规划推理结合的自动驾驶框架,代码将开源以推动后续研究。
相关工作回顾
视觉-语言模型自GPT发布以来,大型模型的能力已从单模态扩展到多模态。大型视觉-语言模型(VLMs)在视觉理解与推理任务中展现出卓越性能。早期研究尝试将视觉模型与大型语言模型(LLMs)结合:Flamingo通过视觉编码器处理视觉信号,并在LLM解码器中引入注意力层以实现跨模态交互;BLIP提出Q-Former架构和跨模态对比学习任务,以桥接视觉编码器与LLMs;LLaVA采用简单的MLP作为视觉与语言模块的连接器,仅用有限数据即实现强大的视觉理解能力。QwenVL系列进一步优化了视觉模块,支持高分辨率和动态分辨率图像输入,并在多语言任务和空间感知中表现优异。
强化学习与推理自回归学习是LLMs的主流预训练策略,而强化学习(RL)与推理技术进一步增强了模型能力。例如,GPT采用基于人类反馈的强化学习(RLHF),将人类意图和偏好融入训练过程;直接偏好优化(DPO)通过优化偏好反馈提升模型性能。Group Relative Policy Optimization(GRPO)引入组间相对优化策略,通过多组输出的相对优劣提升训练稳定性和效果。
DeepSeek R1基于GRPO训练时经历了“顿悟时刻”(Aha Moment),模型在无显式引导下自主增加问题思考并重新评估初始方案,展示了RL在推动模型从模仿转向涌现智能中的潜力。本实验中,我们同样观察到,经过GRPO-based RL训练后,AlphaDrive展现出多模态规划能力,可生成多组合理驾驶方案,为提升驾驶安全与效率提供了可能。在推理领域,Chain-of-thought通过分步分解复杂问题显著提升解决能力。OpenAI o1基于该方法,结合推理时扩展(如蒙特卡洛树搜索MCTS和集束搜索Beam Search),在科学和编程等需复杂推理的领域取得突破,表明除扩展模型参数与数据外,提升推理时计算量亦是重要方向。
自动驾驶规划规划是自动驾驶的核心任务。早期基于规则的算法通用性与效率受限。近期,端到端模型通过统一神经网络直接从传感器数据输出轨迹或控制信号,利用大规模驾驶演示数据驱动训练,显著提升规划性能。然而,端到端模型因缺乏常识与推理能力,仍难以应对长尾场景。
VLM在自动驾驶中的应用VLM的常识与推理能力可有效弥补端到端模型的不足。在机器人领域,视觉-语言-动作(VLA)模型通过理解指令执行复杂动作,VLM生成规划指令后由动作模型转换为控制信号。
自动驾驶领域亦有相关探索:DriveGPT4以视频为输入,直接预测控制信号;ELM利用跨领域视频数据提升VLM在驾驶任务中的性能;OmniDrive提出稀疏3D令牌表征场景,输入VLM进行理解与规划。
部分研究结合VLM与端到端模型:DriveVLM首次将VLM用于低频轨迹预测,端到端模型生成高频轨迹;Senna提出VLM负责高层规划、端到端模型执行低层轨迹预测的框架。此外,多数据集与基准推动了VLM在自动驾驶中的应用。然而,现有工作多依赖预训练模型与简单SFT,缺乏针对规划的训练策略探索,需进一步将RL与推理技术引入自动驾驶领域。
详解AlphaDrive

概述
AlphaDrive 是专为自动驾驶规划设计的视觉-语言模型(VLM)。与以往仅依赖监督微调(SFT)的方法不同,我们探索了强化学习(RL)与推理技术的结合,以更好地适配驾驶规划的独特特性:
- 不同驾驶行为的重要性差异(如制动比匀速行驶更关键);
- 多解性(如直行道路可选择加速或保持速度);
- 规划推理数据的匮乏。
为此,我们提出四个基于GRPO的RL奖励函数,并设计结合SFT与RL的两阶段规划推理训练策略。实验表明,与仅使用SFT或无推理的模型相比,AlphaDrive在规划性能与训练效率上均显著提升。以下详细阐述各模块的设计。
面向规划的强化学习
强化学习算法
当前主流RL算法包括PPO、DPO和GRPO。给定查询,GRPO从旧策略中采样一组输出,并通过最大化以下目标优化新策略:
其中,,和为超参数,优势通过组内奖励归一化计算。
选择GRPO的原因:
- DeepSeek R1[14]验证了GRPO在通用领域的有效性,其训练稳定性与效率优于PPO和DPO;
- GRPO的组间相对优化策略天然适配规划的多解性。实验进一步表明,GRPO训练的模型展现出更强的规划能力。
规划奖励建模
规划准确性奖励数学或编程领域可通过最终答案是否正确直观判定奖励,但规划需同时考虑横向(方向)与纵向(速度)决策。我们采用F1分数分别评估两者的准确性。初期直接匹配真实标签导致训练不稳定,最终采用F1分数以避免模型学习“输出所有可能动作”的捷径策略。
动作加权奖励不同动作对安全的重要性不同(如制动权重高于匀速)。为此,我们为动作分配权重,将其作为奖励的加权分量。
规划多样性奖励规划本质为多模态任务。为避免模型收敛到单一解,我们鼓励生成多样化可行解:当输出差异较大时提高奖励,反之降低奖励。
规划格式奖励要求输出严格遵循<answer>标签格式(如<answer> decelerate, left_turn</answer>),未遵循则奖励为0。
奖励计算流程详见算法1。最终,规划质量奖励(准确性×权重×多样性)与格式奖励共同用于GRPO损失计算。

推理:大模型知识蒸馏
自动驾驶缺乏现成的规划推理数据,人工标注成本高昂。为此,我们利用大模型(如GPT-4o)从少量驾驶片段生成高质量推理数据:
- 输入:真实驾驶动作、车辆状态与导航信息;
- 输出:简洁的决策过程(如“前方绿灯,但行人待穿行,故减速”)。
经人工筛选后,通过SFT将推理过程蒸馏至AlphaDrive,显著提升其推理能力。
训练:SFT预热与RL探索
RL依赖稀疏奖励信号,而SFT基于稠密监督更适配知识蒸馏。此外,仅使用RL易导致训练初期不稳定。因此,我们采用两阶段训练:
- 阶段一(SFT预热):使用少量数据蒸馏大模型推理过程;
- 阶段二(RL探索):在全量数据上微调,提升模型鲁棒性与多模态规划能力。
实验结果分析
实验设置
数据集我们采用MetaAD作为训练与评估基准。该数据集包含12万段真实驾驶片段(每段3秒),覆盖多传感器数据与感知标注,并保持各类驾驶环境与规划动作的平衡分布。其中11万段用于训练,1万段用于验证。此外,我们从训练集中采样3万段数据生成规划推理过程。
训练细节以Qwen2VL-2B为基模型,输入包括前视图像与包含当前车速、导航信息的提示词(如“直行100米后右转”)。训练使用16块NVIDIA A800 GPU。
评估指标
- 元动作规划准确性:计算横向(直行/左转/右转)与纵向(保持/加速/减速/停止)动作的F1分数,并综合为整体规划准确率;
- 推理质量:通过BLEU-4、CIDEr、METEOR评估生成推理过程与标注的相似度。
主要结果
表1显示,AlphaDrive在MetaAD上的规划准确率达77.12%,较次优模型Qwen2VL-7B提升25.5%。关键动作(如转向与加减速)的F1分数显著提高,推理质量亦优于其他模型,验证了两阶段训练策略的有效性。

表2的消融实验表明:
- 基础准确性奖励(ID1)因格式不匹配导致性能偏低;
- 格式奖励(ID2)小幅提升稳定性;
- 动作加权奖励(ID3-4)显著优化关键决策;
- 多样性奖励(ID5-6)进一步防止模式坍缩。

表3对比不同训练策略:
- SFT+RL在复杂动作(如减速)上的F1分数提升15%以上,推理能力优于纯SFT或RL模型;
- RL训练在数据量有限时(如20K样本)表现更优,仅需20%数据即可超越SFT模型35.31%(表4)。

消融实验
奖励函数设计
- 规划准确性奖励(F1分数)避免模型学习“输出所有动作”的捷径策略;
- 动作加权奖励提升安全关键动作(如制动)的权重;
- 多样性奖励通过惩罚重复输出,鼓励生成多组可行解;
- 格式奖励确保输出结构化,提升训练稳定性。
训练策略
- SFT预热缓解RL早期训练的不稳定性;
- RL探索通过GRPO优化多解性与安全性,实验显示模型在复杂场景中涌现出多模态规划能力(图3)。

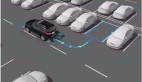
多模态规划能力涌现
如图3所示,AlphaDrive在复杂场景(如前方车辆缓慢行驶)中可生成多个合理决策(如减速左转超车或停车等待),而SFT模型仅输出单一动作。此能力可与下游动作模型结合,动态选择最优方案,提升驾驶安全性与效率。
结论与局限性
结论本研究提出了AlphaDrive——一种面向自动驾驶规划的视觉-语言模型(VLM)。与以往仅依赖监督微调(SFT)的方法不同,我们探索了强化学习(RL)与推理技术在规划任务中的结合。具体而言,AlphaDrive引入了基于GRPO的规划导向RL策略,并设计了两阶段规划推理训练范式。据我们所知,AlphaDrive是首个将RL与推理技术应用于自动驾驶规划的框架,显著提升了性能与训练效率。
局限性当前版本仍存在以下不足:
- 复杂行为标注数据不足:由于缺乏丰富的标注数据,AlphaDrive尚无法输出车道变换或绕行等复杂驾驶行为;
- 伪标签质量依赖:规划推理数据来自大模型基于真实驾驶动作生成的伪标签,其感知准确性可能影响数据质量,需进一步闭环验证以提升性能上限。
未来工作将聚焦于通过数据增强与系统验证优化模型能力,推动自动驾驶规划技术的实际应用。