当下,前后端分离是互联网应用程序开发的主流做法,如何设计合理且高效的前后端交互 Web API 是前端和后台开发人员日常开发工作的一大难点和痛点。回想我们在日常开发过程中经常会碰到的几个场景:
- 后台开发人员调整了返回值的类型和数量而没有通知到前端;
- 后台开发人员修改了某一个字段的名称没有通知到前端;
- 前端开发人员需要通过多个接口的拼接才能获取页面暂时所需要的所有字段;
- 前端开发人员无论想要多获取还是少获取目标字段都需要与后台开发人员进行协商;
- …
相信你对上面这个场景非常熟悉,因为我们每天都可能在反复经历着类似的场景。那么,如何解决这些问题呢?这就是今天我们要介绍的内容,我们将引入 GraphQL 这套全新的技术体系,它为我们解决上述问题提供了方案。
GraphQL 的基本概念
相比 REST,GraphQL 可以说是一项比较新的技术体系,2012 年诞生在 Facebook 内部,并于 2015 年正式开源。顾名思义,GraphQL 是一种基于图(Graph)的查询语言(Query Language,QL),从根本上改变了前后端交互 API 的定义和实现方式。
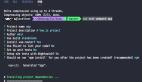
要想使用 GraphQL,我们首先需要关注它发送请求的方式。这里我们可以举一个例子。假设系统中存在一个获取用户信息的场景,那么一个典型的请求示例如下所示:
可以看到基于 GraphQL 的请求方式与使用传统的 RESTful API 有很大的不同。除了在请求体中指定了目标 User 对象的参数 id 值之外,我们还额外指定了“name”和“address”这两个参数,也就是告诉服务器端这次请求所希望获取的数据字段。
显然,这种请求方式完美地解决了前端无法预判响应的数据格式问题,因为前端在请求的同时已经知道从服务端返回的数据字段就是请求中指定的字段,因此前端就不需要再对响应结果进行专门的判断和处理。
针对传统交互方式中存在的多次请求问题,GraphQL 可以把多次请求合并成一次。例如,我们可以发送这样一个请求。
在该请求中,我们一方面指定了想要获取的 User 对象中的“name”和“address”字段,同时也指定了需要获取用户对应的家庭字段“family”以及它的子字段“count”。这样,通过一次请求,我们就可以同时获取用户信息和家庭信息,而不需要发送两次请求。
讲到这里,你可能已经注意到,通过 GraphQL 发起请求实际上只需要指定一个 HTTP 端点地址即可,因为我们可以基于同一个端点通过传入不同的参数而获取不同的结果,也就不需要专门设计一批 HTTP 端点来分别处理不同的请求了。
现在,我们已经了解了 GraphQL 的功能特性。那么,如何实施 GraphQL 呢?
GraphQL 的实施方法
首先明确,我们并不推荐在任何场景下都使用 GraphQL。对于那些 API 定义与资源概念匹配度较高、也不需要实现类似用户信息内部嵌套家庭成员信息的复杂查询场景,传统的 RESTful API 仍然是首选,各个 HTTP 端点之间相互独立,职责非常明确。但对有些场景而言,GraphQL 则更有优势。包括:
- 业务复杂度高
- 需求变化快
- 弱文档化管理
对于大多数系统而言,GraphQL 的推行需要前后端进行紧密的配合,在这个配合过程中,前端的痛点往往是大于服务端的。所以,一般场景下前端对于引入 GraphQL 的诉求要大于服务端。另一方面,如果采用和 RESTful API 一样的开发模式,那么实现 GraphQL 的工作量主要是在服务端。服务端同学需要基于 GraphQL 规范重新设计并实现 API,通常都建议单独构建一个数据层来对外暴露 GraphQL API。
 图 1 在后端服务中构建数据层示意图
图 1 在后端服务中构建数据层示意图
在实施 GraphQL 的策略上,我们也可以总结几条最佳实践。首先,如果你已经实现了一部分 RESTful 服务,那么可以让 GraphQL 与这部分 RESTful API 并存发展。尤其是对于那些单一的 RESTful 服务,可以把 GraphQL 直接连接到已有的 RESTful 服务上。通过这种策略,RESTful 服务中已经实现的业务逻辑层、数据访问层组件都可以得到复用,我们要做的只是开放一个新的 GraphQL 访问入口而已。而且,作为一项新技术的引入过程,GraphQL 和 RESTful 服务在一段时间内并存发展也符合平滑过渡的客观需求。
 图 2 RESTful 和 GraphQL 并存发展示意图
图 2 RESTful 和 GraphQL 并存发展示意图
如果你正在采用微服务架构,那么引入 GraphQL 的策略就是在所有后端微服务之前架设一层由 GraphQL 构建的数据层,并对后端服务提供的数据进行自由的组装之后开放给前端。这种实施策略类似于微服务架构中的 API 网关,一方面对前端请求进行适配和路由,一方面完成前后端之间的解耦。
GraphQL Java 框架
我们知道,GraphQL 是一种理念和规范,它并不直接提供开发工具和框架。而 GraphQL Java 是基于 Java 开发的一个 GraphQL 实现库,在实际的应用开发中,开发人员可以创建自己的 Controller 层组件来与 GraphQL 完成整合。当然,我们也可以对 GraphQL Java 进行一定的封装和扩展。因此,我们需要首先掌握 GraphQL Java 中所包含的核心编程组件。GraphQL Java 中内置了一组核心的技术组件。
 图 3 GraphQL Java 中的核心组件
图 3 GraphQL Java 中的核心组件
首先,我们需要引入一个核心组件,即 Schema。所谓 Schema,简单讲就是一种前后端交互的协议和规范,或者可以把它类比成 RESTful API 中的接口定义文档。在 Schema 中,开发人员需要指定两部分内容。一方面,我们需要明确定义前后端交互的数据结构,包括具体的字段名称、类型、是否为空等属性。另一方面,GraphQL 规定每一个 Schema 中可以存在一个根 Query 和根 Mutation,分别用于执行查询和更新操作。我们来看一个典型的 Schema 定义。
在上述 Schema 中,我们看到了根 Query 和根 Mutation,也看到了 ID、String 等基本数据类型和 User 这个自定义复杂数据结构,以及用来表明是否为空的!和数组的[]。
第二个要介绍的组件是 DataFetcher。从命名上看,DataFetcher 组件的作用就是在执行查询时获取字段对应的数据。DataFetcher 是一个接口,只定义了一个方法,如下所示:
开发人员可以从 DataFetchingEnvironment 中获取传入的参数,并根据该参数来执行具体的数据查询操作。至于数据查询操作的具体实现过程,DataFetcher 并不关心。
创建 DataFetcher 只是开始,我们还要将它们应用在 GraphQL 服务器上,这就需要借助 RuntimeWiring 组件。通过 Runtime Wiring(运行时组装)机制,我们可以把 DataFetcher 整合在 GraphQL 的运行环境中。创建 RuntimeWiring 的典型代码如下所示:
可以看到,这里通过 RuntimeWiring 的 type 方法将各个 DataFetcher 与对应的数据结构关联起来。
最后,基于 Schema 和 RuntimeWiring,我们就可以创建 GraphQL 对象,如下所示:
基于这个 GraphQL 对象,我们就可以使用它来完成具体的查询操作,最终面向业务层的代码如下所示:
可以看到,使用 GraphQL Java 进行开发的难度并不大,流程也比较固化。这对我们开发人员来说无疑减轻了很多学习的压力和负担。
总结
在日常开发过程中,基于 HTTP 协议的 RESTful API 是我们目前主流的前后端开发模式,但并不一定是最合理的开发模式。今天我们所介绍的 GraphQL 具备的功能特性能够在一定程度上解决传统开发模式中所存在的一些问题。GraphQL 更加具有灵活性和扩展性,并能显著减少前后端交互所需要的沟通和开发成本。在日常开发过程中,建议你根据自身业务发展的需求和变化,在合适的场景中引入 GraphQL 相关技术体系。