数据仓库,英文全称Data Warehouse,简称DW或DWH。
数据仓库和数据库的名字非常接近,但两者是完全不同的东西。
我们先从数据仓库的历史开始说起吧。
数据仓库的诞生
数据仓库并不是一个新概念。事实上,它诞生至今,已经有几十年的历史。
上世纪70年代,关系数据库(也就是传统数据库的主要类型)刚刚崛起的时候,美国康奈尔大学博士比尔·恩门(Bill Innmon,也有译为比尔·因蒙)就开始定义和讨论数据仓库这一术语。
1988年,IBM研究人员巴里·德夫林(Barry Devlin)和鲍尔·穆尔菲(Paul Murphy),联合发表了文章《商业和信息系统的架构》,其中引入了“商业数据仓库”一词。他们还开发了一种叫做“业务数据仓库”的系统。
几年后,1990年,美国科学家拉尔夫·金博尔(Ralph Kimball)创立了Red Brick Systems公司,推出专门用于数据仓库的数据库管理系统Red Brick Warehouse。
1991年,又是前面那个比尔·恩门,创立了Prism Solutions公司,推出用于开发数据仓库的软件Prism Warehouse Manager。
同年,比尔·恩门正式出版了数据仓库的经典著作——《构建数据库仓库》,标志着数据仓库概念的正式确立。
后来,比尔·恩门也被世人誉为“数据仓库之父”。
 比尔·恩门
比尔·恩门
数据仓库的定义和特征
那么,到底什么是数据仓库呢?
比尔·恩门在《构建数据库仓库》书中给出了一个定义——
数据仓库,是一个面向主题的(Subject Oriented)、集成的(Integrated)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,用于支持管理决策(Decision Making Support)。
这个定义非常抽象、烧脑,但准确概括了数据仓库的几个关键特征,值得剖析一下。
- 支持管理决策
先说“支持管理决策”,这是数据仓库的作用,也是创造它的主要目的。
简单来说,传统数据库主要是员工使用,支撑某项具体的工作。例如收银系统等。
而数据仓库,主要是管理层使用,用于掌握宏观情况,以便做出更合理的决策。
以前小枣君给大家介绍数据库入门的时候,提到过OLTP和OLAP。
OLTP是联机事务处理(Online Transaction Processing)数据库,出现较早,也是早期关系型数据库的主要用途,用于支持日常业务操作,如订单处理、库存管理和银行交易等。它们通常处理大量简单的读写操作,需要系统能够快速响应,且非常可靠。
OLAP是联机分析处理(Online Analytical Processing)数据库,出现较晚,用于支持复杂的分析查询,如数据挖掘、趋势分析和财务报告等。它们通常处理大量复杂的只读查询,对算力要求高,也需要支持很大的数据吞吐量。
数据仓库,很显然就是OLAP型。或者也可以说,数据仓库是OLAP数据库场景的延伸和发展。OLAP类应用,催生了数据仓库。
概括来说,数据仓库是一个战略级的工具。它通常用于商业智能(Business Intelligence,简称BI,咨询机构Gartner造出来的流行词)和决策支持,可以帮助企业从大量数据中获得有价值的信息,增加洞察能力。
终极目的,当然是增加收入、提升效率、降低成本。
- 面向主题
传统数据库,围绕具体的工作(应用)来组织数据,用于一个明确的事务。例如进销存数据库、考勤数据库、财务数据库等。
而数据仓库,是按照主题来组织数据的。所谓主题,是一个特定的业务领域,或者一个明确的分析目标,例如销售分析主题、员工敬业度主题,学生在校表现主题等等。主题的范围更大,level(层级)更高。
简单来说,数据仓库的数据,是多个传统数据库的集合和“拉通”。它把不同数据库表单的信息挑选整合在一起,提供了一个更全面的数据呈现。
主题性的设计,显然更适合支持管理者做决策和分析。
- 集成
集成,是指数据仓库可以整合来自多个不同数据源(企业内部数据库、供应商数据库、渠道商数据库等)的数据。
多方面的数据源,也是为了提供一个更全面的视角,以便服务于分析和决策。
这些数据,可以包括结构化数据、半结构化数据和非结构化数据等。但数据仓库,主要还是结构化数据为主。
- 相对稳定
相对稳定,指的是数据一旦被加载到数据仓库中,通常不会更新或修改,确保了数据的稳定性和用于长期分析的可靠性。
换言之,数据仓库所涉及的操作,主要是数据查询,而不是修改。
除了数据之外,数据仓库的架构一般也不会频繁变化。
- 反映历史变化
传统数据库,一般都是数据更新。写入新数据,替换旧数据。
数据仓库不一样。它保存了大量的历史数据,有利于企业从时间的维度,分析业务的发展趋势。
面向主题、集成、相对稳定、反映历史变化,这就是数据仓库的四大特征。
我们还是以超市为例,总结一下数据仓库和传统数据库的区别。
假如你有一个大超市。
超市有基于传统数据库的很多个收银台,记录了每天的每一笔交易(卖出了什么商品,金额是多少)。超市还有库存系统,记录了商品的信息(一共有多少个库存)。还有会员系统、购物卡系统,等等。
所有这些数据,分散在不同的系统里,杂乱无章。
你把所有系统的数据(销售数据、顾客信息、供应商记录等),统一做了整理(比如去掉无效数据、统一“日期”格式),按主题分类(比如“销售分析”、“客户画像”),集中存到一个庞大的数据系统里。这就是数据仓库。
然后,你开发了一些工具,可以分析这些数据,回答你的一些疑问:
“过去5年哪些商品在春节卖得最好?”
“上海和北京的顾客购物习惯有什么差异?”
“如何预测明年的商品库存需求?”
……
也可以以大屏的形式,观看这些数据(掌控全局、运筹帷幄的老板既视感):
 图片
图片
当然了,这些数据也可以开放给各个部门的主管,帮助部门改善业绩。
这个数据仓库,是不是辅助了你的决策,创造了价值?
数据仓库的架构和工作流
接下来,我们看看数据仓库的整体架构,以及如何搭建。
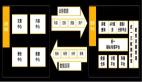
每个公司的数据仓库架构都不太一样。但基本上都包括以下几层:
 数据仓库的整体架构
数据仓库的整体架构
原始数据层(ODS,Operation Data Store):也叫数据引入层、操作数据层、数据准备层或贴源层,用于采集和存储原始数据。
数据公共层(CDM,Common Data Model):数据仓库的主要部分。有时候又分为基础层/明细层(DWD,DW Detail)、汇总层/服务层(DWS,DW Service)、公共维度层(DIM)。DWD对源数据进行清洗以便将其加载到数据仓库中。DWS将经过清洗和转换后的数据并轻度汇总。DIW用于保存维度信息,用于建模。
数据应用层(ADS,Application Data Service):主要功能是保存结果数据,为外部系统提供查询接口,用于满足特定的商业智能、数据挖掘和报表应用。
数据仓库的架构和它的工作流有密切的关系。
一般来说,数据仓库的工作流分为以下几步:
1、数据抽取
前面说了,数据仓库有很多的数据源。所以,第一步,是从不同的数据源系统中抽取数据。
数据抽取是定期进行的,比如每天或每周,以确保数据是最新的。
2、数据清洗和转换
抽取出的数据,通常需要经过清洗和转换,以提高数据质量和一致性。
清洗包括修正错误、去除重复项、处理缺失值等。转换则是将数据转化为统一的格式,以便在数据仓库中进行有效存储和查询。
3、数据建模
数据仓库采用特定的数据模型,对数据进行组织和存储,设计数据表。选择合适的模型,可以简化数据查询和分析过程,提高查询性能。
数据仓库建模中,比较有代表性的两类方法论是Ralph Kimball的建模方法论和Bill Inmon建模方法论(没错,就是前面提到的那两个大佬)。
Ralph Kimball的维度建模方法论,是一种常用的数据仓库建模方法,它强调使用星型模型、雪花模型、星座模型来设计数据仓库。
 图片
图片
Bill Inmon则认为企业数据仓库应为原子数据的集成仓库,应用第三范式和ER模型而非维度建模的事实表、维度表来建模。
这里要提到一个元数据的概念。
元数据是描述数据的数据。它用以描述数据仓库内数据的结构、位置和建立方法,便于数据仓库的管理和使用。
4、数据存储
数据仓库通常采用大容量、高性能的存储系统,以满足大量数据的存储和查询需求。数据仓库的存储结构通常针对查询性能进行了优化,如列式存储、索引等。
5、数据加载
抽取(Extract)、转换(Transform)和加载(Load),就是著名的ETL三板斧。
ETL后的数据,会被加载到数据仓库中。
根据需要,还可能会进一步加工,例如聚合、摘要和索引创建,以优化查询性能。
另外,数据加载可以分为全量加载和增量加载两种方式,也是根据需求选择。
6、数据访问与分析
数据仓库完成数据存储后,就可以开始用了。
数据仓库支持各种数据分析和报表工具,如商业智能(BI)、SQL查询、OLAP、数据挖掘等。用户可以通过这些工具,对数据进行深入分析,找到其中的规律和趋势。
值得一提的是,数据仓库不仅支持宏观趋势分析,也支持微观细节探究,能够满足各个层级的需求。
7、数据安全和访问控制
在数据仓库的使用过程中,当然还要注意数据安全和访问控制。确保数据的安全性和合规性,防止数据泄露和滥用。
 图片
图片
数据集市(Data Mart)
数据集市可以认为是数据仓库的子集,是专用于特定业务部门或功能的数据系统。它的数据是从数据仓库中提取并进一步加工得到的。
例如,一个销售数据集市,可以提供详细的销售报告和分析,辅助销售部门进行决策。
 图片
图片
数据集市的优点包括:
1.规模小:由于只包含与特定主题相关的数据,因此数据集市的规模相对较小,易于构建和维护。
2.数据深:数据集市可以满足特定部门或用户的需求,提供更加详细和深入的数据支持。
3.响应快:因为它的数据量相对较小且针对特定需求进行了优化,所以能够提供更快的查询响应时间。
4.建设周期短:由于规模较小且面向特定需求,数据集市的建设周期通常较短,可以快速实现并投入使用。(数据仓库的建设周期一般需要数个月甚至一年以上。)
5.灵活性高:数据集市的数据模型和结构可以根据特定需求进行调整,具有较高的灵活性。
6.成本低:数据集市的实现成本相对较低,因为其数据量和复杂度较数据仓库低。
数据仓库的发展趋势
数据仓库诞生了几十年,技术也一直在发展。为了实现处理能力的升级,经历了多个发展阶段。
早期的时候,基本上就是基于传统数据库产品(例如Oracle),构建的数据仓库。数据仓库最早也是离线的,数据源通过离线方式导入到离线数据仓库中。
后来,进入21世纪,有了大数据技术(Hadoop、Spark等)。就开始将这些技术引入到数据仓库,通过MapReduce、Hive、SparkSQL等离线计算引擎进行数据处理,处理效率有了明显提升。
再后来,分别发展出了Lambda架构(离线+实时结合)和Kappa架构(批流一体)。
 图片
图片
再再后来,到了近几年,就是基于MPP数据库和数据湖的实时数仓架构。
这些架构支持高性能并行处理,支持复杂查询。在处理能力和效率上已经今非昔比,能够帮助企业更及时、更准确地进行决策。
从部署方面来看,数据仓库也有变化。以前是本地单机部署,后来是分布式部署,再后来,云计算崛起,就是云部署。
这两年,AI很火。所以,很多企业开始研究AI与数据系统的深度结合。
说白了,就是看AI怎么让数据仓库能够更智能地处理和分析数据,提高数据的准确性和可靠性。反过来,AI也是“吃”数据的,还要研究如何让数据仓库这样的数据平台,更好地服务于AI的训练和推理。
这里面的发展前景,还是非常广阔的。