













在 分布式链路追踪,一文帮你掌握它! 这篇文章中,我们详细地分析了分布式链路追踪的原理,这篇文章,我们将分析一款开源的分布式链路追踪框架:Apache SkyWalking。

一、SkyWalking 原理
1. 架构
SkyWalking 由中国开源社区发起,并于2019年捐赠给 Apache 软件基金会,成为其顶级项目之一。SkyWalking 的整体架构由四个主要组件组成:探针(Agent)、收集层(Collector)、数据存储层(Storage)、和 UI 层。各组件之间通过网络通信,协同工作,实现数据的收集、传输、存储、分析与展示。整体架构如下图:
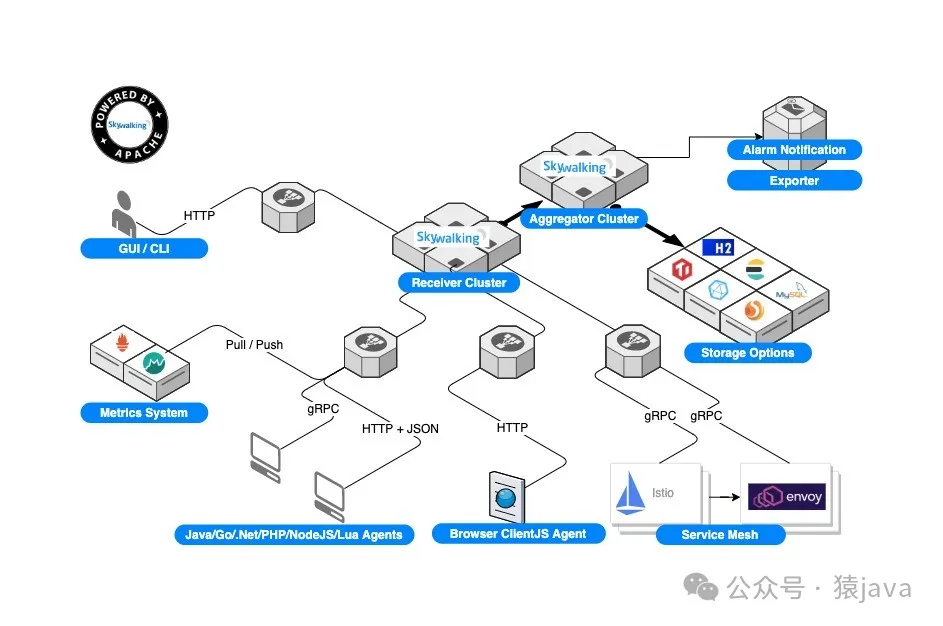
SkyWalking 架构图
- 探针(Agent):部署在被监控的服务实例上,负责收集应用的性能数据和调用链信息。
- 收集层(Collector):接收探针发送的数据,对数据进行处理、聚合和转发。
- 数据存储层(Storage):存储经过处理的性能指标和追踪数据,支持多种存储后端,如 Elasticsearch、H2、MySQL、TiDB 等。
- UI 层:提供用户界面,通过图形化的方式展示监控数据和分析结果,供用户查看和分析。
2. 数据收集
SkyWalking 通过探针在被监控的应用中植入代码,拦截应用的请求与响应过程,收集相关的性能指标和调用链信息。探针主要有以下几种类型:
- Agent:针对不同语言和框架的探针,如 Java Agent、.NET Agent、Python Agent、Node.js Agent 等。
- APM 插件:支持常见框架和技术,如 Spring、Dubbo、gRPC、HTTP 等,自动注入探针代码,捕获关键的性能数据和调用关系。
- 扩展机制:允许用户通过自定义插件扩展探针功能,满足特定的监控需求。
数据收集的核心指标包括:
- 指标数据:如响应时间、吞吐量、失败率、CPU 使用率、内存使用率等。
- 调用链数据:记录请求在分布式系统中的流转路径,包括各个服务的调用关系、耗时等信息。
3. 数据处理与存储
收集到的数据通过网络传输到 SkyWalking 的收集层(Collector)。Collector 负责接收、解析和处理这些数据,包括去重、聚合、过滤等操作,然后将其存储到后端的存储系统中。
SkyWalking 的数据处理机制具有高度的扩展性和灵活性,支持多种存储后端,使得用户可以根据自身需求选择最合适的存储方案。常见的存储后端包括:
- Elasticsearch:适合大规模、高并发的数据存储和快速查询。
- H2:轻量级嵌入式数据库,适用于小规模或测试环境。
- MySQL / TiDB:关系型数据库,适合需要事务支持和复杂查询的场景。
除了存储,Collector 还负责对数据进行索引和分片,优化查询性能。此外,Collector 可以接入消息队列,如 Kafka,实现数据的异步传输和高可用性。
4. 数据展示与分析
SkyWalking 的 UI 组件提供了丰富的数据可视化功能,帮助用户直观地理解系统的运行状况和性能瓶颈。其主要功能包括:
- 服务拓扑:展示各个服务实例之间的调用关系,帮助用户了解系统的整体架构和关键依赖。
- 调用链分析:基于 Tracing 数据,展示单个请求的详细调用路径,以及各个环节的耗时和性能指标。
- 指标分析:提供实时和历史的性能指标图表,如响应时间趋势、吞吐量变化、资源使用情况等。
- 告警管理:根据预设的规则,对异常情况进行实时告警,帮助运维快速响应和处理故障。
- 日志聚合:整合分布式系统中的日志信息,辅助故障排查和性能优化。
二、使用方式
1. 部署方式
SkyWalking 支持多种部署方式,可以根据具体的业务需求和系统架构选择最适合的方案。
- 单节点部署:适用于小规模测试和开发环境,所有组件(Collector、Storage、UI)部署在同一节点上。
- 分布式部署:适用于生产环境,支持将不同组件部署在不同节点上,提升性能和可用性。
- 容器化部署:支持通过 Docker 和 Kubernetes 等容器编排工具部署,方便与云原生环境集成。
- 混合云部署:支持跨多个数据中心和云环境的部署,满足复杂的企业级需求。
2. 使用 Docker 部署
SkyWalking 提供了官方的 Docker 镜像,简化了部署流程。以下是通过 Docker Compose 快速部署 SkyWalking 的步骤:
(1) 安装 Docker 和 Docker Compose
首先确保系统已安装 Docker 和 Docker Compose。可以通过以下命令检查版本:
docker --version
docker-compose --version(2) 下载 Docker Compose 文件
从 SkyWalking 官方仓库下载 docker-compose.yml 文件,或者根据需求自行编写。
(3) 启动 SkyWalking 服务
在 docker-compose.yml 文件目录下运行:
docker-compose up -d(4) 访问 SkyWalking UI
默认情况下,SkyWalking UI 绑定在 8080 端口,可以通过浏览器访问 http://localhost:8080 查看监控数据。
2. 集成方法
SkyWalking 提供多种集成方法,适用于不同的编程语言和框架,这里以 Java 语言为例,介绍如何集成方式。
对于 Java 应用,SkyWalking 提供了 Java Agent,可以通过以下步骤进行集成:
(1) 下载 Agent
从 SkyWalking 官方网站下载最新版本的 Java Agent。
(2) 配置应用启动参数
将 Agent 包含在应用的启动参数中,例如:
java -javaagent:/path/to/skywalking-agent.jar -Dskywalking.agent.service_name=your-service-name -Dskywalking.agent.collector_backend_service=localhost:11800 -jar your-app.jar其中,service_name 是应用的服务名,collector_backend_service 是 SkyWalking Collector 的地址。
(3) 启动应用
启动应用后,Agent 会自动拦截应用的请求,采集性能数据并发送到 Collector。
3. 配置与优化
合理的配置和优化可以提升 SkyWalking 的性能和使用体验。以下是一些常见的配置和优化建议:
(1) 采样率设置
设置合适的采样率,平衡数据的全面性和系统的性能开销。采样率过高会增加网络和存储的压力,过低则可能遗漏关键的性能数据。
collector:
logging:
sampling_rate: 1.0 # 范围 0.0 - 1.0(2) 存储后端选择
根据系统的规模和查询需求选择合适的存储后端。Elasticsearch 适用于大规模数据和复杂查询,H2 适合小规模和测试环境,MySQL/TiDB 适合需要事务支持的场景。
(3) 分片与索引优化
针对存储后端进行分片和索引优化,提高数据的写入和查询效率。例如,对于 Elasticsearch,可以根据数据量和查询模式调整分片数量和副本配置。
(4) 资源分配与监控
为 SkyWalking 的各个组件(Collector、Storage、UI)分配足够的资源(CPU、内存、磁盘),并通过监控工具实时监控其运行状况,避免因资源不足导致的性能瓶颈。
(5) 高可用部署
在生产环境中,建议部署多个 Collector 实例,通过负载均衡器进行流量分发,确保系统的高可用性和容错性。
(6) 安全配置
对 SkyWalking 的通信和访问进行安全配置,如启用 SSL/TLS 加密、设置访问控制和权限管理,保护监控数据的安全性。
4. 常用功能介绍
SkyWalking 提供了丰富的功能,覆盖了分布式系统的各个方面。以下是一些常用功能的详细介绍:
- 服务拓扑: 服务拓扑展示了系统中所有服务之间的调用关系,包括服务实例、依赖关系和通信流量。用户可以通过拓扑图快速了解系统的整体架构,识别关键服务和潜在的性能瓶颈。
- 分布式追踪:SkyWalking 通过分布式追踪技术,记录请求在各个服务之间的流转路径,包括每个服务的响应时间、处理逻辑和资源消耗。用户可以查看单个请求的详细调用链,定位性能问题和故障根源。
- 指标分析:提供全面的性能指标监控和分析功能,如响应时间、吞吐量、失败率、资源使用情况(CPU、内存、磁盘等)。用户可以通过图表和报表直观地了解系统的运行状况和历史趋势。
- 告警管理:支持基于阈值、异常检测和自定义规则的实时告警功能。当系统出现异常情况时,SkyWalking 会及时发送告警通知,帮助运维团队快速响应和处理问题。告警通知可以通过多种渠道发送,如邮件、Slack、钉钉等。
- 日志聚合:通过与日志系统(如 ELK、Fluentd 等)集成,实现日志的集中采集、存储和分析。用户可以在 SkyWalking 中关联日志数据和追踪数据,提升故障排查的效率。
- 拓扑分析:提供服务间通信的拓扑分析功能,帮助用户识别系统中的热点服务、关键依赖和潜在的单点故障。
- 性能诊断:通过对请求性能的深入分析,识别系统的性能瓶颈,提供优化建议。例如,定位高响应时间的接口、资源消耗过大的服务等。
- 系统健康检查:提供系统运行状态的健康检查,监控各个组件的运行状况,如内存使用率、CPU 负载、磁盘空间等,确保系统的稳定性和可靠性。
三、优缺点
1. 优点
- 开源且活跃的社区支持:SkyWalking 是 Apache 基金会的顶级项目,拥有活跃的社区和丰富的文档资源。用户可以通过社区获取技术支持、交流经验,并参与项目的发展。
- 多语言支持:SkyWalking 支持 Java、.NET、Node.js、Python 等多种编程语言,适用于多语言混合的微服务架构。
- 丰富的插件机制:提供了丰富的探针和插件,支持多种框架和技术,如 Spring、Dubbo、gRPC、HTTP、数据库等,方便用户快速集成和扩展功能。
- 强大的数据分析与可视化:提供全面的服务拓扑、分布式追踪、指标分析等可视化功能,帮助用户直观地了解系统的运行状况和性能瓶颈。
- 高扩展性与灵活性:SkyWalking 具有高度的扩展性,支持多种存储后端和部署方式,满足不同规模和需求的系统监控。
- 高可用与容错机制:支持分布式部署和负载均衡,确保系统的高可用性和容错能力,适用于生产级别的应用场景。
- 丰富的告警与通知机制:提供多种告警配置选项和通知渠道,帮助用户及时发现和响应系统异常,提高运维效率。
- 集成多种监控数据:除了分布式追踪,SkyWalking 还集成了指标监控和日志聚合,提供全面的系统可观测性。
2. 缺点
- 配置复杂:对于初次接触 SkyWalking 的用户来说,系统的部署和配置可能较为复杂,尤其是在分布式和高可用性部署的场景下,需要较多的配置和调优。
- 资源消耗较高:在大规模和高并发的系统中,SkyWalking 的 Collector 和 Storage 组件可能会消耗较多的资源(CPU、内存、磁盘),需要合理规划和分配资源。
- 学习曲线较陡:由于功能丰富,SkyWalking 的使用和操作需要一定的学习成本,尤其是对于数据分析和告警配置等高级功能。
- 存储后端限制:虽然 SkyWalking 支持多种存储后端,但不同的存储系统在性能、扩展性和功能上存在差异,用户需要根据实际需求选择合适的存储方案。部分存储后端在大规模数据的写入和查询时表现可能不如预期。
- 生态系统集成:虽然 SkyWalking 支持与常见的监控工具(如 Prometheus、Grafana)集成,但在某些特定场景下,可能需要额外的开发和定制工作。
- 社区支持相对较新:相较于一些成熟的 APM 工具(如 Jaeger、Zipkin),SkyWalking 的社区规模和活跃度相对较小,部分高级功能的支持和文档可能不足。
- 高级功能复杂:某些高级功能(如自定义告警规则、复杂的拓扑分析)需要深入理解 SkyWalking 的内部机制和配置,对于缺乏相关经验的用户来说,可能较难上手。
四、总结
本文,我们分析了链路追踪框架 SkyWalking的工作原理以及如何使用它,SkyWalking 是一款开源的分布式追踪和应用性能监控工具,如果工作中我们想对分布式系统进行性能分析和监控,那么 SkyWalking 是一个不错的选择。




























