昨天和大家聊了库存异常的两种情况:
- “先查后减”,容易出现异常;
- “先查后设”,幂等性优化,解决重试问题;
- “先查后设,有条件的设”,CAS优化,解决并发问题;
有留言说:可以用redis优化。redis方案是可以的,今天简单展开说说。
redis一般如何操作库存?
一般在redis客户端执行:
$num = GET key$num = $num - $countSET key $num这样操作存在什么问题?
在并发量大的时候,会遇到和上一篇文章中提到的并发一致性问题。
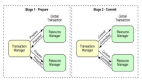
是如何利用redis事务操作优化?
本质也是乐观锁。
redis的WATCH和EXEC可以提供类似事务的机制:
- WATCH观察key是否被改动;
- 如果提交时key被改动,EXEC将返回null,表示事务失败;
保证一致性的库存扣减可以优化为:
WATCH key$num = GET key$num = $num - $countMULTISET key $numEXEC在WATCH之后,EXEC执行之前,如果key的值发生变化,则EXEC会失败。
redis的WATCH为何能够保证事务性?
本质上,和上一篇文章中提到的乐观锁CAS机制是一样的,详见:
大部分情况下,redis不同的客户端会访问不同的key,所以WATCH碰撞的概率会比较小,在秒杀的业务场景,使用WATCH,也会有一定的冲突,需要针对秒杀业务做单独的优化。
为什么redis更能应对超高并发的库存管理?
根本原因,还是redis内存访问与mysql数据落盘的性能差异。
redis库存管理有什么需要注意的?
数据具备“易失性”,如果重启,数据可能丢失,所以redis大部分时候是用来存储允许cache miss的数据。如果实在要用redis来存储业务上不能够丢失的数据,需要重点设计一致性与可用性。
当然,redis也可以固化数据,但如果把redis当做DB用,为什么不直接使用mysql呢?
稍作总结
- 可以使用redis的事务性扣减库存,其核心原理也是CAS机制;
- redis高性能的核心是内存存储,一般用来存储允许cache miss的数据;
- 如果使用redis存储不允许丢失的数据,需要注意一致性与可用性,这一点上,对比mysql没有额外优势;
具体怎么用,还得结合业务折衷。
任何脱离业务的架构设计都是耍流氓!
知其然,知其所以然。
思路比结论更重要。