近日,在Gartner 发布的《2024 年 Gartner 云数据库管理系统魔力象限报告》中,亚马逊云科技以卓越的产品能力和前瞻性愿景,连续第十年被评为领导者。Gartner 指出,亚马逊云科技是全球最广泛采用的云服务提供商,提供广泛的云DBMS服务,并且其数据库服务可满足交易、操作、分析和流式应用等多种工作负载的需求。
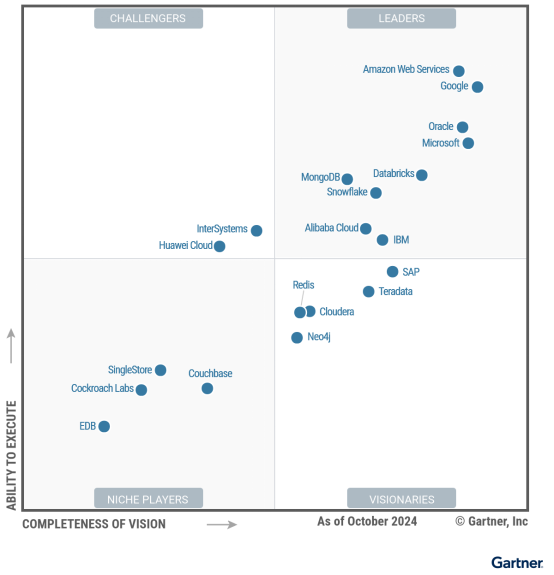
2024 年 Gartner 云数据库管理系统魔力象限
在云数据库领域竞争日益激烈之际,亚马逊云科技究竟凭借何种能力,得以连续十年稳居领导者之位?其背后的关键,在于亚马逊云科技对用户需求的精准把握,以及对自我设限的持续突破。
对于用户需求,亚马逊云科技首席执行官 Matt Garman 表示,如果摒弃各种限制,数据库客户认为理想的数据库解决方案需要具备高可用性、多区域运行、极低的读写延迟、强一致性、没有操作负担和兼容 SQL 语义的能力。
这些需求并非“或”的关系,而是“和”的关系。单独一个需求容易满足,但如此之多的需求能够同时满足吗?答案是可以。
2024 年 12 月,亚马逊云科技在 2024 re:Invent 全球大会上发布了一款重磅的数据库服务新品——Amazon Aurora DSQL。这是一款集多种理想型功能于一身的“全能理想型”无服务器分布式 SQL 数据库,能够满足上述所有的功能需求。
若要揭秘亚马逊云科技为何能“领航十年”,为何能打破限制推出 Amazon Aurora DSQL,则要从2014年说起。
打破“A 或 B”,打造“A 和 B”: 从 Amazon Aurora 到 Amazon Aurora DSQL
2014 年,亚马逊云科技在 re:Invent 大会上推出了 Amazon Aurora。Amazon Aurora 一经问世,便迅速成为企业上云的首选。究其原因,是因为在当时的市场中,既能满足高性能需求,又不会带来高昂成本的数据库可谓凤毛麟角。而 Amazon Aurora 恰恰做到了性能与价格的兼顾,自然迅速赢得了企业的青睐。

十年前,Amazon Aurora 在 2014 年 re:Invent 上发布
Amazon Aurora 是兼容 MySQL 和 PostgreSQL 的云原生关系型数据库,其核心突破在于将传统数据库的存储与计算分离,通过分布式架构实现高性能与高可用性。并且Amazon Aurora 的吞吐量达到传统 MySQL 的 5 倍,成本却仅为同级别商业数据库解决方案的 1/10。
Amazon Aurora 的问世一举打破了 “鱼与熊掌不可兼得” 的传统认知局限。突破传统认知的背后,是亚马逊云科技转变了“在 A 和 B 之间做选择” 的固有思维定式,转而深入探索 “如何同时达成 A 和 B” 的创新路径。
“当你尝试构建某些东西或者决策时,常常会在 A 和 B 之间做选择吗?这种选择恰恰限制了思路,亚马逊云科技将其称为‘或的暴政’,因为这种选择制造了虚假的边界,让你马上开始思考自己必须选出A 或 B。但亚马逊云科技是推动团队思考如何同时达成 A 和 B。”Matt Garman 在 2024 re:Invent 全球大会揭秘了亚马逊云科技成功的秘诀之一。
满足性能与价格的兼得后,Amazon Aurora 仍没有停止创新的步伐。自Amazon Aurora 发布以来,亚马逊云科技在此基础上推出了众多创新功能,如无服务器版本的推出让用户无需管理基础设施地使用,推出Amazon Aurora Limitless Database以实现跨单台服务器读写吞吐量限制进行扩展和自动分布式分片,与其他数据库和数据仓库服务间的Zero-ETL以加速数据流动,与Amazon Bedrock集成以助力客户更好地构建生成式AI应用。
亚马逊云科技不仅为Amazon Aurora 打造了“A 和 B”的功能,更是实现了“A 和B 和 C 和 D”的技术迭代与创新。在持续探索与创新过程中,Amazon Aurora DSQL 诞生了。
突破传统数据库束缚的Amazon Aurora DSQL
前文提到,Amazon Aurora DSQL 是一款“全能理想型”无服务器分布式 SQL 数据库,能够同时实现低延迟、多区域的强一致性、几乎无限扩展的高可用性,以及零运营负担。

2024 re:Invent 大会上,亚马逊云科技发布Amazon Aurora DSQL
同时达成这些能力并不容易。但对于亚马逊云科技来说,只有突破传统数据库的束缚才能实现更好的创新,就像打破“或的暴政”一样。因此,Amazon Aurora DSQL突破的第一个传统束缚是将事务处理与存储解耦。
对于传统数据库来说,在单一位置或单一区域实现应用程序和数据库的往返信息传递非常容易,也能够满足低延迟的需求;可一旦跨区域执行,信息受到光速的限制,不仅往返传递速度会大大降低,也难以达到多区域的强一致性要求。
为了解决这一难题,Amazon Aurora DSQL 应用了一种全新的交易处理方式——解耦事务处理与存储。这种方式使Amazon Aurora DSQL 在事务提交时会进行一次性检查,同时并行处理所有区域的所有写入操作,从而提供具有强一致性和快速写入的多区域数据库服务。
实现低延迟和强一致性后,还需确保事务按照发生的顺序提交。为了消除不同区域的时间偏差,Amazon Aurora DSQL 采用了 Amazon Time Sync 服务,该服务在每个 Amazon Elastic Compute Cloud(EC2) 实例上部署硬件参考时钟,使实例与卫星连接的原子钟同步,以此实现全球范围内微秒级的精确时间同步。
这两种能力结合使得Amazon Aurora DSQL 在确保低延迟的同时实现强一致性,即“所有在一个区域写入的事务都将实时同步至其他区域”。
除此之外,Amazon Aurora DSQL 的另一突破是采用分布式架构,分离查询处理层、提交层和存储层,实现了“几乎无限的扩展能力”。
传统数据库由于集中式架构和数据强一致性要求,在数据规模或应用需求快速扩大时,难以高效地进行横向扩展,且存在数据一致性难以保证、扩展过程复杂等问题。
而Amazon Aurora DSQL 采用了分布式架构,允许查询处理层、提交层和存储层分离独立扩展,以适应不同的读写比例、数据规模和查询复杂性。这种设计不仅消除了传统数据库的扩展瓶颈,支持水平扩展,还能够根据实际负载动态调整资源分配。
Amazon Aurora DSQL 的无服务器特性也进一步简化了扩展过程,用户无需手动管理服务器配置或进行数据库分片,即可实现从较小规模到大规模的无缝过渡。再加上主-主(Active-Active)架构和多区域支持,Amazon Aurora DSQL 便能以高可用性和强一致性满足各种工作负载需求,为用户提供灵活、高效且无需妥协的数据库解决方案。
从结果来看,Amazon Aurora DSQL 不仅提供了卓越的一致性,还将读写速度提升了 4 倍,实现了 99.999% 的多区域可用性,具备几乎无限的可扩展性,且完全消除了管理基础设施的负担。
云数据库领域变革:AI 驱动的创新力量
如果说不断突破传统束缚是亚马逊云科技持续领跑的基础,那么对行业趋势的前瞻把握则是保持竞争力的关键。进入 AI 时代,各个垂直领域都在寻找与 AI 的融合之道,云数据库领域也不例外。
《2024 年 Gartner 云数据库管理系统魔力象限报告》指出,“云数据库管理系统(DBMS)市场依旧充满活力,并且正在进行重大变革,特别是在生成式人工智能(AI)的应用,以及数据库管理系统与其他数据管理组件的交互方式上。”
因此,亚马逊云科技认为,越来越多的用户将不再孤立地使用单一的数据分析和处理工具,而是结合分析、ML 和生成式 AI 从而获取洞察并为用户提供新体验。为此,亚马逊云科技在2024 re:Invent 全球大会上推出了新一代 Amazon SageMaker 作为统一的“工作室”,为用户提供单一的数据和 AI 开发环境,助力用户更好地在 AI 时代持续创新发力。
具体来说, Amazon SageMaker Unified Studio 融合了 Amazon Bedrock、Amazon EMR、Amazon Redshift、Amazon Glue 以及现有 Amazon SageMaker Studio 中备受用户青睐的一系列独立“工作室”、查询编辑器和可视化工具等功能。它为用户打造了一个一站式的数据和 AI 开发环境,让用户能够轻松地访问和使用这些强大的工具,从而高效地完成数据发现与准备、查询编写、数据处理以及机器学习模型的构建。
结语
云数据库领域的十年霸榜之路,亚马逊云科技始终在证明:真正的行业领导者不仅要具备解决“既要、又要、还要”复杂需求的技术实力,更要拥有突破传统思维定式的创新勇气。未来,亚马逊云科技将持续寻找突破成本、性能、易用性和功能极限的创新路径,为用户带来更全面和强大的产品使用体验。