













很久没写开篇了,针对大数据采集分析和导出等功能,我们必须在内存和性能上做好折中,这其中笔者最爱的就是流式查询,而本文将基于多个角度针对流式查询这技能进行深入的分析和演示,希望对你有帮助。

一、详解流式查询
1. 关于IOPS和数据吞吐量
为了保证后文讲解的流畅,我们这里对几个比较重要的性能指标进行简单的科普,对于服务器系统层面,IOPS(Input/Output Per Second)磁盘每秒的读写次数,一般以每秒输入输出量为单位进行衡量。而吞吐量更多的是反应的是每秒处理的IO请求,两者关系我们可以通过如下两个场景了解一下差异:
- 假设我们读取1000个1kb的数据,耗时10s,那么这个服务器的数据吞吐量100KB/s,IOPS就是100,这种场景更追求IOPS。
- 假设我们只有1个请求去读取10M的文件,耗时0.2s,那么这个服务器的数据吞吐量就是50MB/s,IOPS为5,这个服务器就更偏向于吞吐量。
2. MySQL常见的几种查询
日常针对大表数据采集导出的功能,我们一般会采用一下几种方案:
- 一次性全量导出
- 使用分页查询
- 使用游标查询
- 流式查询
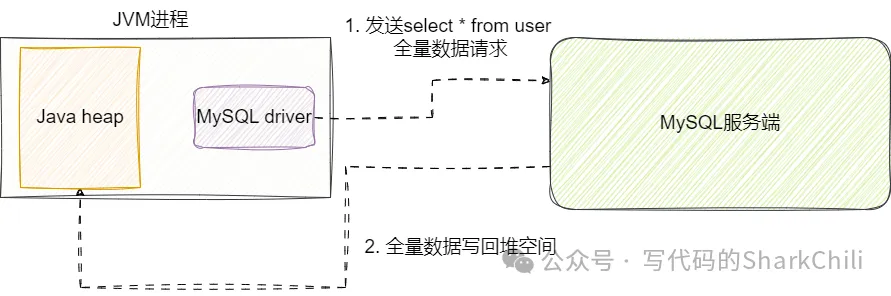
(1) 全量导出
我们先来说说全量查询,这种方案本质原理就是一次性将结果集从MySQL服务端写到客户端程序上,针对大表数据检索,如果我们的程序没有足够的堆内存空间,存在内存溢出的风险:
(2) 分页查询
为了解决OOM问题,我们会考虑通过分页查询的方式,通过分批处理完成批量数据检索导出的工作,这种方式虽然很好的节约了堆内存空间,但这种方案在代码实现层面就已经非常复杂了,开发者必须考虑:
- 分页计算(这一步就涉及数据扫描,开销大)
- 基于分页评估每次分页大小
- 基于页数进行循环查询
- 查询SQL需要针对深分页问题进行优化
这种方案相较于前者虽然节省了堆内存空间且可以一定程度上避免频繁的Full GC,对于开发者整体素质要求较高,并且这种方案在性能表现上也不是很出色:
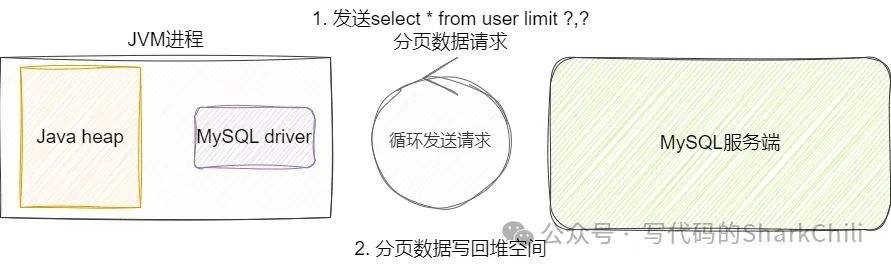
(3) 游标查询
所以为了避免在开发层面进行手动分页实现的复杂度,我们就想到通过游标法进行查询,游标也就是cursor,这种查询方式要求客户端一次性指明fetchSize,然后服务端每次都基于给定的fetchSize将数据写给客户端,直到客户端将所有数据都处理完成。
需要了解的是游标查询这种方案考虑到客户端未知的处理效率,为保证服务端能够一次性将fetch的数据写回到客户端,MySQL服务端会为了这个查询建立一个临时空间来缓存数据,在极端情况下因为这些问题:
- IOPS飙升
- 磁盘空间飙升(因为临时空间无法在缓存中容纳,写入到文件中)
- fetch设置过大,SQL查询经常处于阻塞等待IO数据的情况
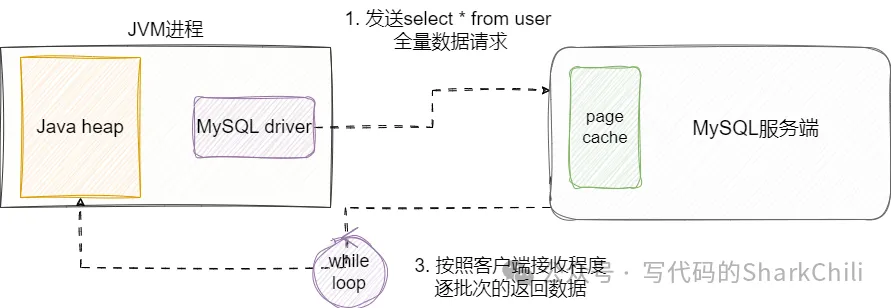
(4) 流式查询
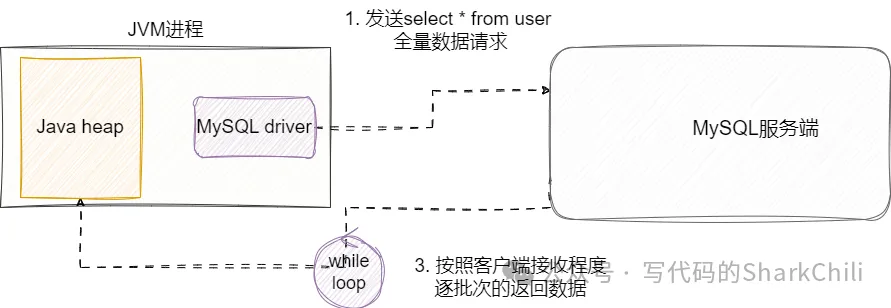
最后我们就来说说本文的重点——流式查询,当客户端向服务端发送SQL请求后,流式查询会得到一个迭代器,客户端不断通过ResultSet.next()获取下一条数据,服务端会按照客户端接受速率并基于迭代器的偏移量逐步写入到网络buffer中让客户端读取,这种方式很好的解决游标查询逐批次缓存的问题。 但需要注意的是这种方案和上述游标查询一样,会因为数据量的问题,使得连接长时间被当前线程持有:
二、流式查询使用示例
接下来笔者就以常见的ORM框架Mybatis演示一下如何使用流式查询,假设我们需要查询一张user表,对应的我们基于Options注解给出当前这个查询信息告知查询resultSetType 为只读,并且指明fetchSize 为MIN_VALUE。同时,看到笔者在方法上给出了一个ResultHandler,这个处理用于处理流式查询响应结果后的回调处理:
需要补充说明的是上述三个配置都必须明确按照要求进行配置,原因是在mybatis在执行SQL查询时,StatementImpl会通过createStreamingResultSet判断这三个参数是否符合要求,只有明确符合要求返回true,后续的结果集才能被创建为ResultsetRowsStreaming:
对应的我们也给出最后的使用示例,这里笔者用lambda精简了一下ResultHandler的声明,每当我们收到流式响应数据后,直接获取user并自增一下原子类:
三、性能压测
简单介绍了一下流式查询的基础配置和使用之后,我们不妨针对上述方案进行性能和内存使用情况压测,首先笔者已经准备了100w条数据并将堆内存设置为512M:
我们先给出一个基于全量查询的导出写入到本地txt文件:
最终100w数据导出跑了大约20s:
我们通过jstat指令查看堆内存使用情况,触发了6次full gc,整体回收花费了6s,性能表现非常差劲:
然后就是分页查询,可以看到笔者这里并没有针对深分页问题进行优化,明确页数和分批数后直接进行分批查询导出了:
可以看到这段代码内存使用情况比较稳定,但是耗时大约29s:
最后我们给出流式查询的代码拉取数据并写入本地文件的示例:
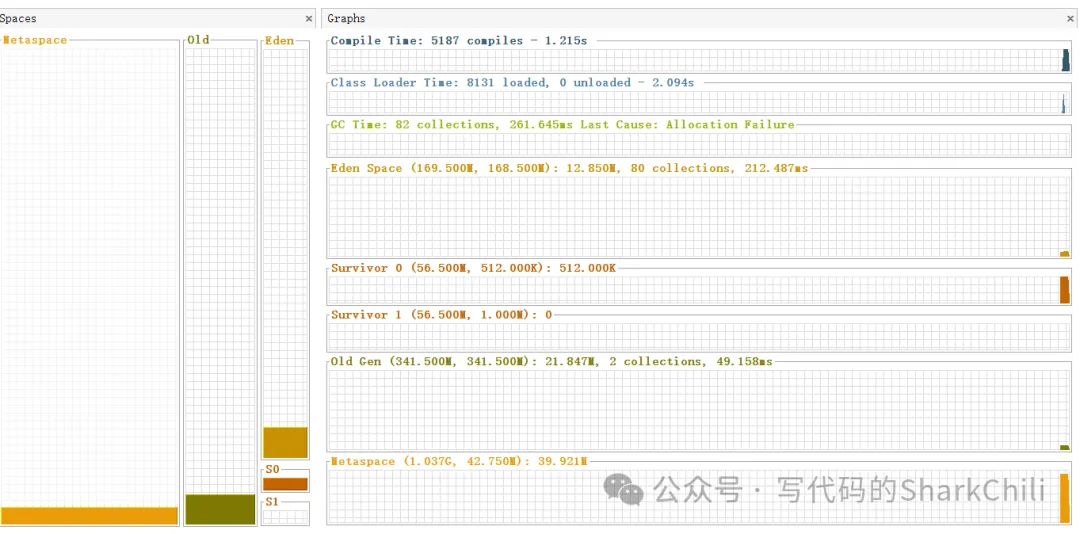
最终整体耗时14s,使用jstat查看gc情况也是非常稳定:
使用jvisualvm也可以看到堆内存使用情况非常稳定,流式查询在内存使用和查询效率上做了很好的平衡:
四、流式查询使用注意事项
流式查询在使用过程中当前客户端连接会持有本次查询的ResultSet,如果没有没有将这个ResultSet关闭将会影响其他查询使用。
在数据量较大的情况下,流式查询会长时间持有当前数据库连接,所以还是可能存在网络拥塞的风险。
























