在日常工作中,服务器安全是企业运营的关键。我们专业的安全团队会用工具对所有服务器进行扫描,找出潜在的安全问题,并生成详细的报告,里面不仅有漏洞信息,还有修复建议。如下图所示,这样不仅能及时解决问题,还能帮助企业建立更安全的防护体系,保障业务正常运行。
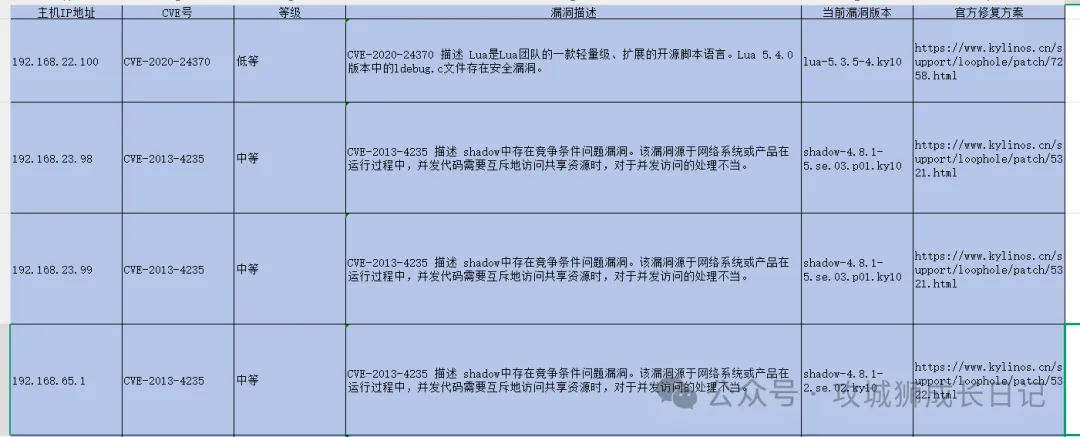
那问题来了,虽然表格中提供了每个漏洞的修复建议链接,但还是需要我们逐一访问官方页面来详细了解具体的修复方案。当漏洞数量较少时,这项工作还算轻松;但如果数量较多,那这个任务的工作量确实会变得相当大。
像这种重复的工作肯定是交给脚本去执行的。我们现来分析一下,我们最终想要实现的效果,如下图所示:

一、实现思路
我们将利用Python中的pandas库来处理原始数据,以CVE编号作为主要标识符,并把具有相同CVE编号的所有主机信息整理在一起。
对于修复步骤,您可以通过访问官方提供的修复链接,根据页面上的关键词找到需要更新的具体软件包。之后,可以根据这些信息构建出使用yum命令进行更新的具体指令。
二、代码实现
1. 获取更新软件包
我们首先分析一下如果从官方修复方案的中提取需要修复软件包,以CVE-2020-24370这个漏洞为例,打开官方修复方案的链接,页面如下图所示:
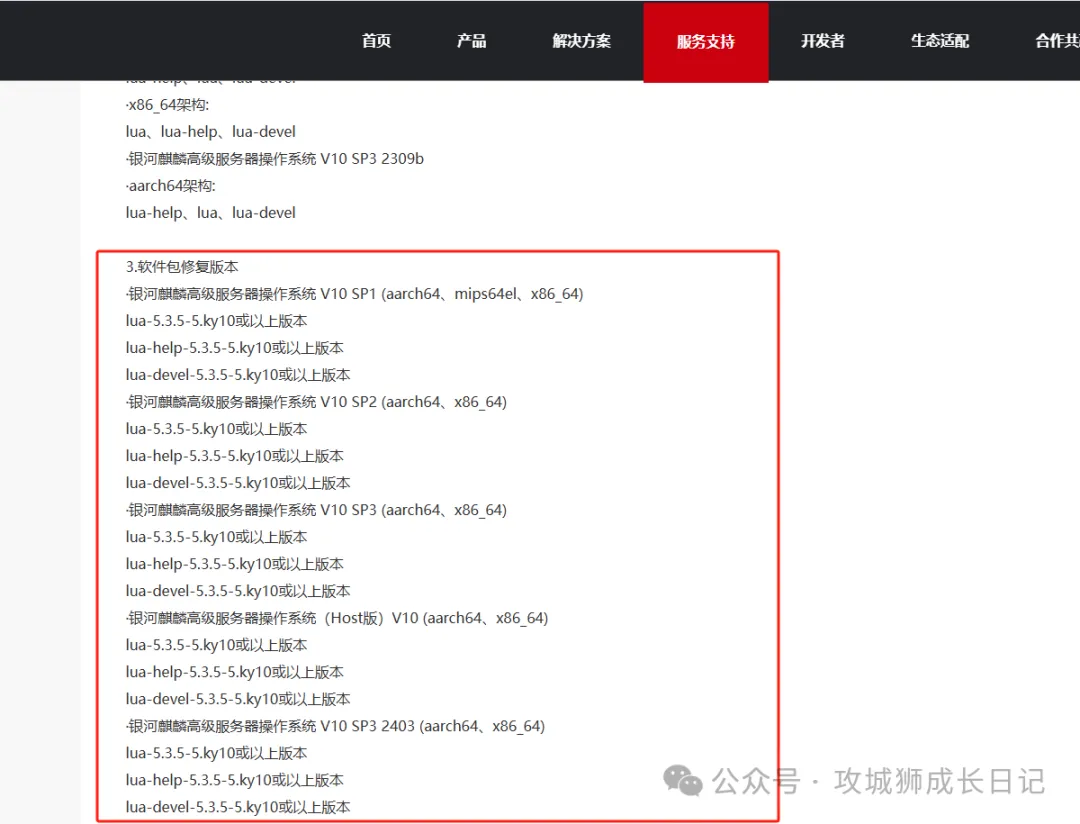
从上图可以看出,修复的软件包有一个共同的特点:它们都遵循“包名-版本号_ky10”这样的命名格式。基于这一点,我们可以使用正则表达式来匹配这些软件包。
下面是一个示例函数,它可以从指定的网页中提取出更新的软件包信息。这个函数的工作流程是这样的:首先接收一个URL作为参数,然后利用Python的第三方库requests获取该网页的内容,最后通过正则表达式筛选出我们需要的软件包列表。
2. 生成更新软件包
根据我们上面介绍的方法,您可以轻松获取到需要更新的软件包名称。接下来,我们将使用下面的函数把这些名称组合成一条完整的更新命令。具体步骤如下:
3. 重新组合数据
为了将原始数据转换为我们需要的格式,我们可以利用Python中的强大工具——Pandas库来进行数据聚合处理。下面是具体的函数内容:
4. 调用函数生成数据
通过调用 process_vulnerability_data,输入两个参数:原始数据表以及输出表的名称。
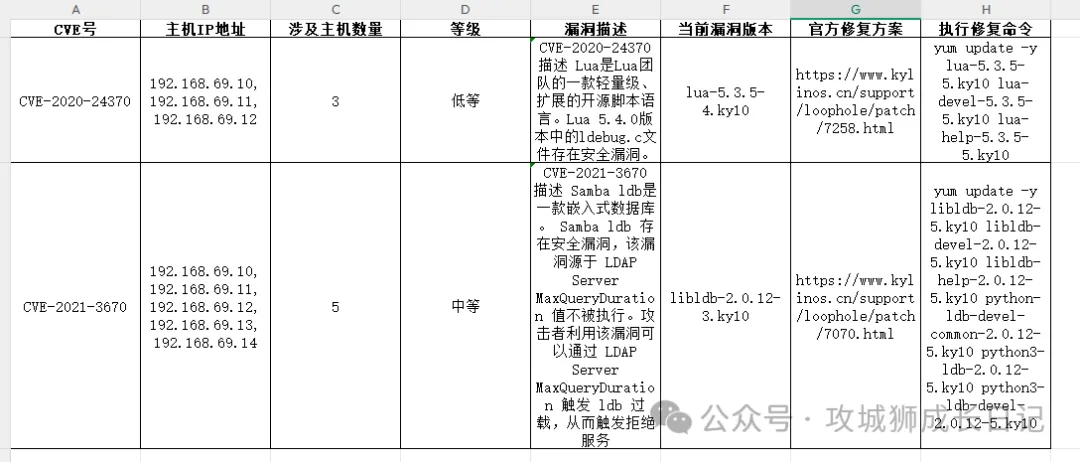
执行上述命令后,就可以得到我们想要的效果表。如下图所示:
三、小结
对于那些重复性的任务,我们可以考虑一下是否可以通过自动化工具或脚本来完成。这样做不仅能提高我们的工作效率,还能让我们有更多时间去休息或是专注于其他重要的事情上呢!