只要一块6年前的2080Ti,就能做大模型数据蒸馏?
来自上交大EPIC实验室等机构的一项最新研究,提出了一种新的数据集蒸馏方法——NFCM。
与前SOTA相比,新方法的显存占用只有1/300,并且速度提升了20倍,相关论文获得了CVPR满分。
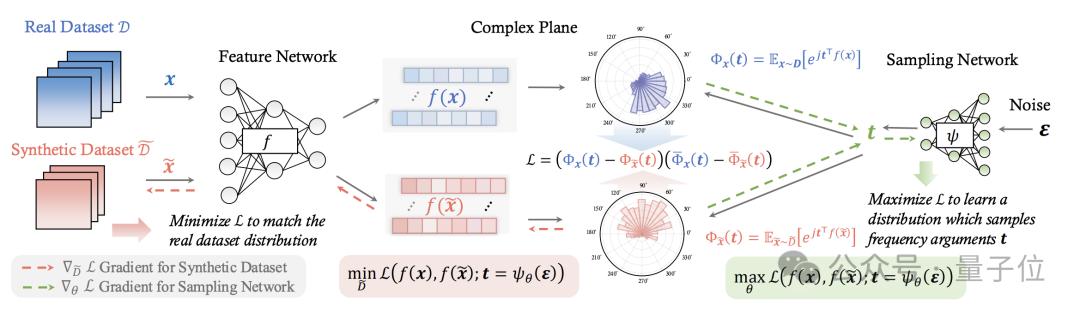
NCFM引入了一个辅助的神经网络,将数据集蒸馏重新表述为一个极小化极大(minmax)优化问题。
在多个基准数据集上,NCFM都取得了显著的性能提升,并展现出可扩展性。
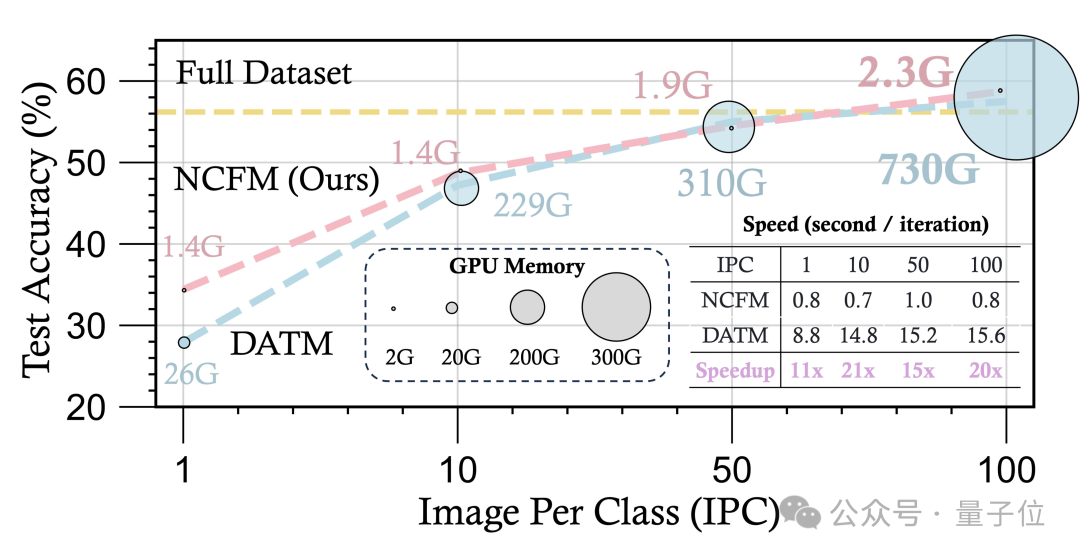
在CIFAR数据集上,NCFM只需2GB左右的GPU内存就能实现无损的数据集蒸馏,用2080Ti即可实现。
并且,NCFM在连续学习、神经架构搜索等下游任务上也展现了优异的性能。
将数据蒸馏转化为minmax优化
NCFM的核心是引入了一个新的分布差异度量NCFD,并将数据集蒸馏问题转化为一个minmax优化问题。
通过交替优化合成数据以最小化NCFD,以及优化采样网络以最大化NCFD,NCFM在提升合成数据质量的同时,不断增强分布差异度量的敏感性和有效性。
特征提取与频率参数采样
NCFM的第一步,是进行特征提取,也就是从真实数据集和合成数据集中分别采样一批数据,并将其输入到特征提取网络中。
特征提取网络将原始数据从像素空间映射到一个特征空间,得到对应的特征表示,目的是提取数据的高层语义特征,为后续的分布匹配做准备。
特征提取网络可以是一个预训练的模型,也可以是一个随机初始化的模型,这里NCFM采用了一种混合方式。
接下来,NCFM引入了一个轻量级的神经网络作为采样网络,它接受一个随机噪声作为输入,输出一组频率参数。
这些频率参数将用于对特征函数(Characteristic Function,CF)进行采样。
特征函数计算与分布差异度量
对于每一个频率参数,将其与特征表示进行内积运算,然后取复指数,就得到了对应的CF值。
这两个CF值都是复数,其中实部刻画了数据在该频率上的分布范围,捕捉分布的散度或多样性;虚部则反映了数据在该频率上的分布中心,捕捉分布的典型性或真实性。
通过比较真实数据和合成数据的CF值,就可以全面地度量它们在特征空间上的分布差异。
为了定量地度量真实数据和合成数据之间的分布差异,NCFM引入了一个称为神经特征函数差异(Neural Characteristic Function Discrepancy,NCFD)的度量。
NCFD综合考虑了所有采样频率上的CF差异,将其汇总为一个标量值。NCFD越小,说明两个分布越接近;NCFD越大,说明两个分布差异越大。
minmax优化
有了NCFD这个分布差异度量,NCFM的优化目标就很清晰了——
最小化NCFD,使得合成数据和真实数据的分布尽可能接近;同时,望最大化NCFD对合成数据的敏感度,使之能够准确反映合成数据的变化。
为了同时实现这两个目标,NCFM引入了一个minmax优化框架:
- 在极小化阶段,固定采样网络的参数,调整合成数据,目标是最小化NCFD。这一步使得合成数据向真实数据分布不断靠拢。
- 在极大化阶段,固定合成数据,调整采样网络的参数,目标是最大化NCFD。这一步使得NCFD对合成数据的差异更加敏感,提升其作为差异度量的有效性。
通过交替进行极小化阶段和极大化阶段的优化,NCFM不断改进合成数据的质量,同时也不断强化NCFD度量的敏感性和准确性。
模型微调与标签生成
为了进一步提升合成数据的质量,NCFM在优化过程中还引入了两个额外的步骤——模型微调和标签生成。
- 在模型微调阶段,NCFM用合成数据微调特征提取网络,使其更加适应合成数据的特征分布,从而进一步缩小合成数据和真实数据之间的特征差异,提高合成数据的真实性;
- 在标签生成阶段,用一个预训练的教师模型来为合成数据生成软标签。软标签提供了更加丰富和细粒度的监督信息,可以指导合成数据更好地模仿真实数据的类别分布,提高合成数据的多样性。
一块2080Ti搞定CIFAR实验
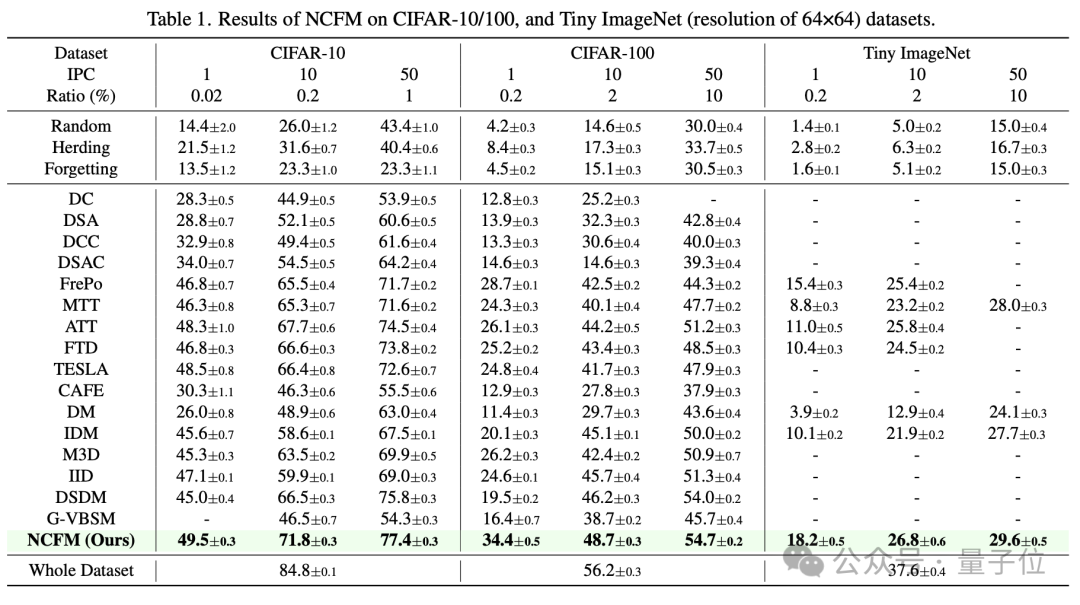
相比于此前方法,NCFM在多个数据集上实现了显著的性能提升。
在CIFAR-10、CIFAR-100、等数据集中上,NCFM在每类1/10/50张图片的情况下的测试精度均超过了所有baseline方法。
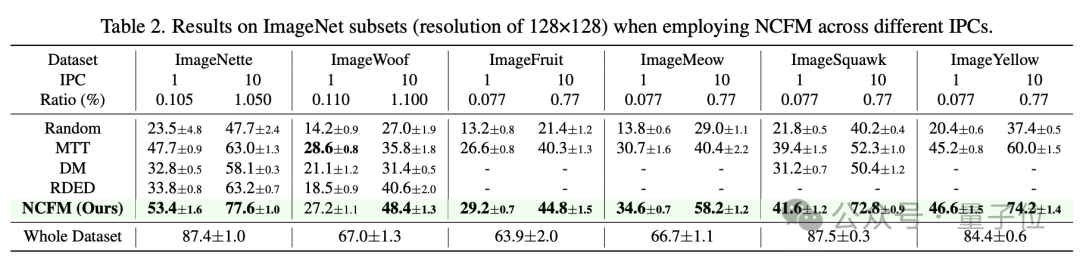
在ImageNet的各个子集上,NCFM也展现了卓越的性能。
例如在ImageNette上,每类10张图片时,NCFM达到了77.6%的测试精度,比现有最佳方法(RDED)高出14.4个百分点;
在ImageSquawk上,每类10张图片时,NCFM达到了72.8%的测试精度,比现有最佳方法(MTT)高出20.5个百分点。
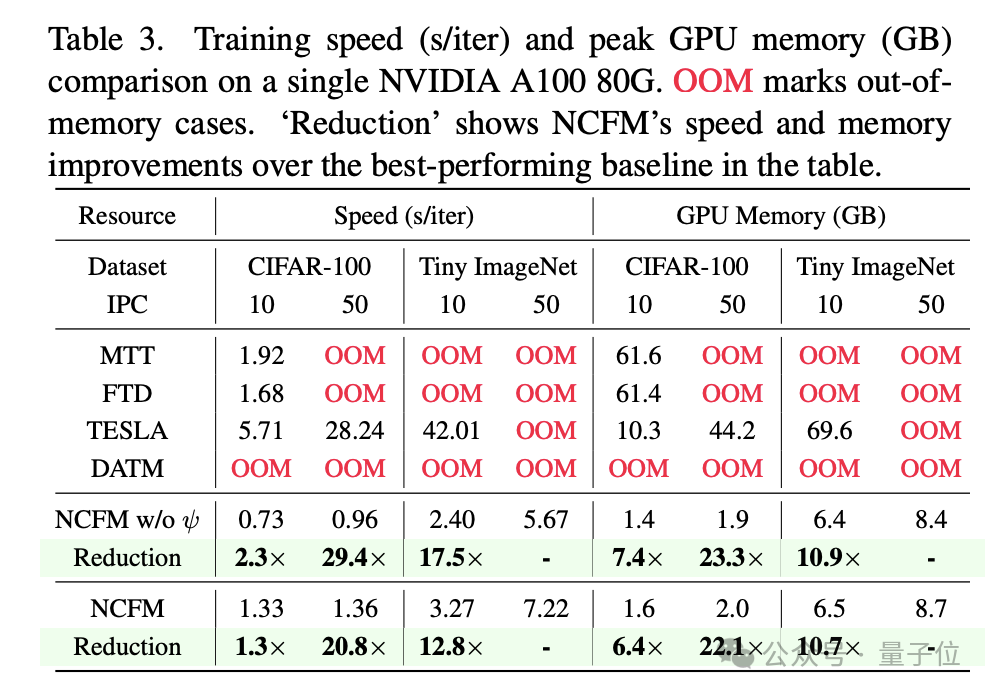
在性能提升的同时,NCFM还实现了大量的速度提升和资源节约。
在CIFAR-100上,NCFM每轮迭代的平均训练时间比TESLA快了29.4倍,GPU内存消耗仅为TESLA的1/23.3(每类50张图片);
在Tiny ImageNet上,NCFM每轮迭代的平均训练时间比TESLA快了12.8倍,GPU内存消耗仅为TESLA的1/10.7(每类10张图片)。
并且,NCFM在CIFAR-10和CIFAR-100上实现了无损的数据集蒸馏,仅使用了约2GB的GPU内存,使得CIFAR上的所有实验都可以在一块2080Ti上进行。
此外,NCFM生成的合成数据在跨模型泛化能力上超过了现有方法。
例如在CIFAR-10上,用NCFM生成的合成数据训练AlexNet、VGG和ResNet,都取得了比现有方法更高的测试精度。

来自上交大“最年轻博导”课题组
本文第一作者,是上交大人工智能学院EPIC实验室博士生王少博。
王少博本科就读于哈工大软件工程专业,专业排名第一名;然后在上交大读研,导师是严骏驰教授,研究方向为深度学习理论和可解释性机器学习,其间专业排名第二。
现在王少博正在张林峰助理教授负责的EPIC实验室读博,研究方向为“高效、可解释的深度学习和”大模型。

王少博现在的导师张林峰,是本文的通讯作者。
张林峰出生于1997年,去年6月在清华叉院取得博士学位,然后到上交大人工智能学院担任博导并负责EPIC实验室,时年仅有27岁。
同时,张林峰还在NeurIPS、ICML、ICLR、CVPR等顶级学术会议当中担任审稿人。

张林峰还曾到香港科技大学(广州)担任访问助理教授,他的邀请人胡旭明同样是一名年轻博导,并且也参与了本项目。
此外还有EPIC实验室的其他成员,以及来自上海AI实验室的学者,亦参与了NFCM的研究。

论文地址:https://github.com/gszfwsb/NCFM/blob/main/asset/paper.pdf
GitHub仓库:https://github.com/gszfwsb/NCFM