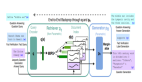
在AI应用爆发的时代,RAG(Retrieval-Augmented Generation,检索增强生成)技术正逐渐成为AI 2.0时代的“杀手级”应用。它通过将信息检索与文本生成相结合,突破了传统生成模型在知识覆盖和回答准确性上的瓶颈。不仅提升了模型的性能和可靠性,还降低了成本,增强了可解释性。
今天来看一篇RAG领域的开山之作,2020年Meta AI发表在NIPS上的一篇工作。

先来看下研究动机:大语言模型(LLM)虽然功能强大,但存在一些局限性,例如知识更新不及时、容易产生“幻觉”(即生成与事实不符的内容),以及在特定领域或知识密集型任务中表现不佳。RAG通过引入外部知识库,检索相关信息来增强模型的输出,从而解决这些问题。
1、方法介绍

RAG模型结合了一个检索器(retriever)和一个生成器(generator),这两个组件协同工作来完成知识密集型的语言生成任务。
- 检索器 (Retriever)
 :检索器负责根据输入序列x检索文本文档z。基于DPR(Dense Passage Retriever)构建,使用预训练的查询编码器和文档编码器来计算查询与文档之间的相似度,并选择最相关的前K个文档。
:检索器负责根据输入序列x检索文本文档z。基于DPR(Dense Passage Retriever)构建,使用预训练的查询编码器和文档编码器来计算查询与文档之间的相似度,并选择最相关的前K个文档。 - 生成器 (Generator)
 :生成器是一个预训练的序列模型(如BART-large),用于根据输入序列x和检索到的文档z来生成目标序列y。它通过将原始输入与检索到的内容拼接起来作为新的上下文来进行解码。
:生成器是一个预训练的序列模型(如BART-large),用于根据输入序列x和检索到的文档z来生成目标序列y。它通过将原始输入与检索到的内容拼接起来作为新的上下文来进行解码。 - 最大内积搜索 (Maximum Inner Product Search, MIPS):通过计算查询向量q(x)和所有文档向量d(z)之间的内积,找到与查询最相关的前K个文档z。
对于整个方法概括来说,用户提供的文本查询x 首先被送入查询编码器,得到查询的向量表示q(x)。利用MIPS算法,在文档索引中快速查找与查询q(x)最相似的前K个文档 。这些文档作为潜在的知识来源,帮助生成更准确的回答。最后,根据输入序列x 和检索到的文档z 来生成目标y。
。这些文档作为潜在的知识来源,帮助生成更准确的回答。最后,根据输入序列x 和检索到的文档z 来生成目标y。
RAG模型使用概率框架来处理检索到的文档作为潜在变量z,这篇文章提出两种方式来边缘化这些潜在文档:
- RAG-Sequence Model:RAG-Sequence 模型使用单一的检索文档来生成完整的序列。具体来说,检索器检索出 top K 文档,生成器为每个文档生成输出序列的概率
p(y∣x)p(y∣x)p(y ∣ x),然后对这些概率进行边缘化处理:

- RAG-Token Model:与此不同的是,RAG-Token允许每个输出token依赖于不同的文档。这意味着对于每一个token,模型都会重新评估一次所有可能的文档,并据此调整生成的概率分布。
边缘化的数学解释
设输入序列为 x,目标序列为 y,检索到的文档集合为 Z。对于给定的输入x 和目标y,我们希望找到一个概率p(y∣x),即在给定输入的情况下生成目标序列的概率。然而,因为我们引入了额外的文档信息z,所以我们实际上需要考虑的是条件概率p(y∣x,z)。
但是,z 是未知的,所以不能直接使用这个条件概率。为此,我们可以利用贝叶斯公式来将z 积分出去,从而得到不依赖于特定文档的p(y∣x):

这里p(z∣x)表示给定查询x 的情况下文档z 被检索出来的概率,这由检索器给出;而p(y∣x,z)则是生成器基于输入x 和文档z 生成目标y 的概率。通过遍历所有可能的文档 z 并加权求和它们各自的贡献,这样就实现了对潜在文档 z 的边缘化。
检索器:DPR
检索组件 基于 DPR ,DPR 采用双编码器架构:
基于 DPR ,DPR 采用双编码器架构:

其中,d(z) 是文档的密集表示,q(x) 是查询表示。使用预训练的DPR来初始化检索器,通过最大内积搜索,计算具有最高先验概率 的k个文档列表,并构建文档索引,将文档索引称为非参数化记忆。
的k个文档列表,并构建文档索引,将文档索引称为非参数化记忆。
生成器:BART
生成器组件 可以使用任何编码器-解码器模型来实现,本文使用 BART-large,在生成时将输入x 与检索到的内容z 简单拼接。 BART 生成器的参数θ称为参数化记忆。
可以使用任何编码器-解码器模型来实现,本文使用 BART-large,在生成时将输入x 与检索到的内容z 简单拼接。 BART 生成器的参数θ称为参数化记忆。
训练
模型采用了负对数似然损失函数训练,即最小化给定输入x 下真实输出 y 的负对数概率。在训练期间,不直接监督应该检索哪些文档,而是让模型学习如何更好地利用检索到的信息来提高生成质量。此外,为了避免频繁更新庞大的文档索引带来的高昂成本,只微调查询编码器和生成器。
解码
测试时,RAG-Sequence 和 RAG-Token 需要不同的方法来近似 。 RAG-Token 模型可以看作是一个标准的自回归 seq2seq 生成器,其转移概率为:
。 RAG-Token 模型可以看作是一个标准的自回归 seq2seq 生成器,其转移概率为:

解码可以通过插入修改后的转移概率 进入常规的束搜索算法完成。
进入常规的束搜索算法完成。
对于RAG-Sequence,整个序列的似然
2、实验结果
开放域问答
RAG-Token 和 RAG-Sequence 在所有四个任务上均达到了新的最先进水平(仅在TriviaQA的一个特定测试集上除外)。

抽象问答
尽管没有使用黄金段落,RAG的表现依然接近需要这些段落才能达到最优表现的模型。
RAG 模型比 BART 更少产生幻觉,并且更频繁地生成符合事实的文本。

Jeopardy 问题生成
表2 显示了Q-BLEU-1度量的结果。表4展示了人工评估结果。表 3 显示了每个模型的典型生成。
RAG-Token 模型特别擅长于从多个检索到的文档中提取信息并组合成复杂的Jeopardy问题。例如,在生成包含两个不同书籍标题的问题时,它能够分别从不同的文档中获取每个书名的信息。
图2 提供了一个具体的例子,展示了当生成“太阳”一词时,文档2(提到《太阳照常升起》)的概率较高;而在生成“A Farewell to Arms”时,文档1(提到海明威的这部作品)的概率较高。
随着每个书名的第一个token被生成后,文档概率分布趋于平坦化,这表明生成器能够在不依赖特定文档的情况下完成整个题目。
非参数化记忆的作用:通过检索相关文档,RAG模型可以引导生成过程,挖掘出存储在参数化记忆中的具体知识。例如,即使只提供了部分解码"The Sun",BART基线也能完成生成"The Sun Also Rises",说明这些信息已经存储在BART的参数中,但RAG能更好地利用外部知识源来增强生成质量。


事实验证
表2 显示了FEVER任务上的分类准确性。对于三类分类任务(支持/反驳/信息不足),RAG得分距离最先进模型仅4.3%以内;对于二类分类任务(支持/反驳),差距更是缩小到2.7%以内。
RAG能够在不依赖检索监督信号的情况下,通过仅提供声明并自己检索证据,实现与复杂管道系统相当的性能。
生成多样性
RAG-Sequence 的生成更加多样化,而RAG-Token次之,两者都显著优于BART。

检索机制的有效性
结果表明,学习检索(即在训练过程中更新检索器)对 RAG 模型的性能至关重要。密集检索器在大多数任务中表现优于传统的 BM25 检索器,尤其是在需要语义匹配和复杂查询处理的任务中。对于某些特定任务(如 FEVER),基于词重叠的 BM25 方法可能更为有效。

检索更多文档的效果

3、总结
RAG的意义简单总结以下几点:
- 提升模型性能:RAG显著提高了生成模型在问答、文本生成等任务中的准确性和可靠性。
- 降低训练成本:无需大规模预训练即可实现知识更新和性能提升。
- 增强可解释性:通过检索过程为生成结果提供明确依据,增强了用户对AI系统的信任。
- 推动行业创新:RAG技术在医疗、金融、法律等多个领域的应用,推动了AI在特定领域的深度落地。
总的来说,RAG技术在AI应用爆发的时代,凭借其对生成模型的增强和优化,正在成为推动AI发展的关键力量。它不仅提升了模型的性能和可靠性,还降低了成本,增强了可解释性。随着技术的不断演进,RAG将在更多领域实现深度应用,为AI的未来发展提供强大动力。