














- 论文标题:WarriorCoder: Learning from Expert Battles to Augment Code Large Language Models
- 论文链接:https://arxiv.org/pdf/2412.17395
01 背景
近年来,大型语言模型(LLMs)在代码相关的任务上展现了惊人的表现,各种代码大模型层出不穷。这些成功的案例表明,在大规模代码数据上进行预训练可以显著提升模型的核心编程能力。除了预训练外,一些通过 instruction 数据对 LLM 进行 post-training 的方法,也使得模型在对指令的理解和回答的质量等方面取得了显著提高。然而,post-training 的效果在很大程度上依赖于可用的高质量数据,但是数据的收集和注释存在着不小的挑战。
为了解决上述挑战,一些方法设计了各种数据飞轮来生成 instruction 数据,如 Self-Instruct,Evol-Instruct 等。这些方法通过多种数据增强手段来构建 instruction 数据,在这些数据上进行训练可以有效提升模型的代码生成能力。然而,如图 1 所示,这些方法仍然依赖于对现存数据集进行扩展并需要调用私有 LLM(如 GPT-3.5、GPT-4 等),使得数据收集成本较高。此外,有限的数据来源和用于注释的 LLM 也限制了数据的多样性,并继承了有限的私有 LLM 本身固有的系统偏见。
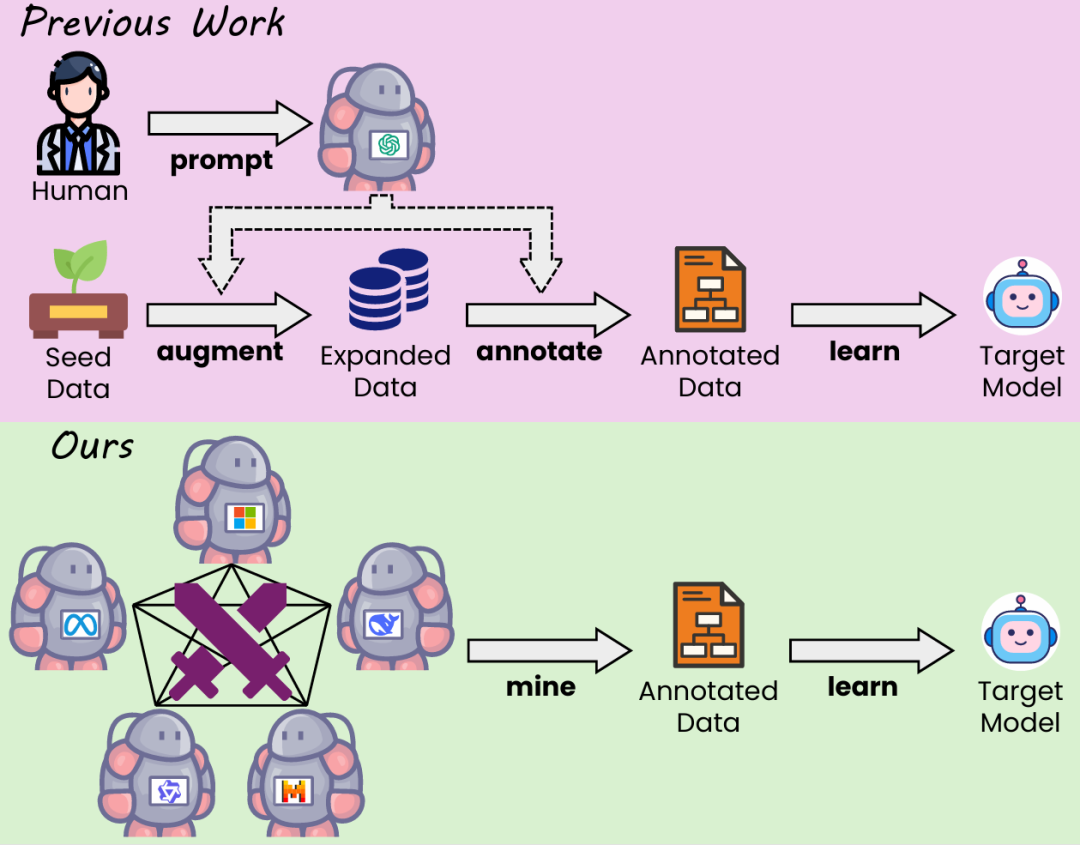
图 1
本文提出了 WarriorCoder,一种全新的代码大模型的数据飞轮训练范式,模型通过学习专家对抗的方式来集成各个代码专家大模型的优点。如图 1 所示,各个代码专家大模型两两对战,攻击者在其自身的专业领域内挑战对手,目标模型则向这些对战中的胜者学习。与之前的方法不同,之前的方法大多都依赖现有开源数据集,将这些数据集做为种子数据去合成和增强,而 warriorCoder 是从 0 到 1 的生成数据不需要种子数据,并且该方法可以融合多个代码专家大模型的优势,而不是仅仅蒸馏个别模型的优势。此外,本文提出的方法消除了在数据收集过程中对人工参与和私有 LLM 的依赖,可以以极低成本收集高质量、多样化的训练数据。实验结果表明,warriorCoder 不仅仅是在代码生成任务中达到了当前的 SOTA,还在 code reasoning 和 libraries using 等 benchmark 上也取得了卓越的成绩,可谓是代码六边形战士。
02 方法
本文构建了一个代码大模型的竞技场。在这里,最先进的代码专家大模型相互对抗,每个模型利用其已经掌握的知识挑战其他模型,而其余模型则担任裁判评估对抗结果。目标模型随后从这些对抗中的胜者学习,逐步整合所有竞争者的优势。本文将参赛者(代码专家大模型)视为一个组,通过组内相对优势答案来优化模型,这一点与 GRPO 有着异曲同工之妙。
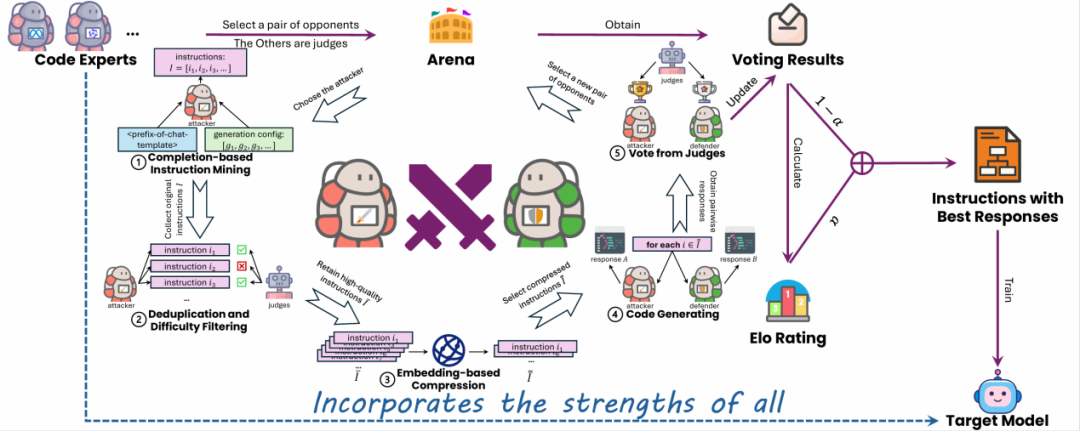
图 2
2.1 Competitors Setting
参赛者的能力决定了 WarriorCoder 的最终表现。理论上,从更大、更强的参赛者池中获得的训练数据多样性更强、质量更高,最终训练出来的模型的性能也就越好。在每一轮竞技场中,只有一对代码专家被选为竞争者,其他的则作为裁判。本文从 BigCodeBench 排行榜中选取了五个 75B 以内的先进大模型 ——Athene-V2-Chat、DeepSeek-Coder-V2-Lite-Instruct、Llama-3.3-70B-Instruct、Qwen2.5-72B-Instruct 和 QwQ-32B-Preview。值得注意的是,这五个大模型均为开源大模型,WarriorCoder 仅基于这些开源大模型的对抗就得到了优异的性能。当然,WarriorCoder 也能够从强大的私有大模型中学习。
2.2 Instruction Mining from Scratch
对于一对对手 ——A 和 B(其中 A 为攻击者,B 为防守者),对抗的第一步是在 A 擅长的领域挑战 B,这就需要了解 A 在训练过程中学到了什么。然而,几乎当前所有的开源大模型都未公布其核心训练数据,这使得攻击者擅长的知识变得极为困难。受 Magpie 的启发,本文设计了一种基于对话补全的方式来挖掘大模型已掌握的能力。以 Qwen2.5 为例,如果要其生成一个快速排序算法,则完整的 prompt 格式如图 3 所示。Prompt 应包括 system content、user content 以及与格式有关的特殊 token,如 “<|im_start|>”、“<|im_end|>” 等。

图 3
而如果仅将前缀部分(本身无任何具体意义,如图 4 所示)输入模型,利用模型的补全能力就可以得到用户指令(user content)。

图 4
通过这种方式,在不同的生成参数配置下(例如不同的温度值和 top-p 值)就可以收集到模型已经学习到的 instruction 数据。与传统的数据合成不同,本文收集的 instruction 数据不是由模型合成的,而是直接从模型的分布中进行采样得到的,这避免了模式过拟合、输出分布偏移等问题。然而,这些指令可能会重复、有歧义、不清晰或过于简单。为了解决这些问题,我们对数据进行去重,并采用裁判模型来评估其难度。本文将难度分为四个等级:Excellent、Good、Average、Poor。最终仅使用 Excellent 和 Good 两个等级的指令,并使用 KcenterGreedy 算法对 instruction 数据进行进一步的压缩。
2.3 Win-Loss Decision
挑战者和防御者都要根据 instruction 数据生成回答,并由裁判(剩余的模型)投票决定输赢:
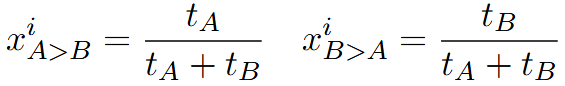
然而,仅依赖于 \textit {局部得分} 来选择获胜者可能会带来偶然性问题。由于投票会受到随机性或评审者偏见等因素的影响,在某些指令下较弱的模型可能会比较强的模型获得更多的投票,即便其回答并没有真正比较强的模型更好。
为了解决这一问题,本文在决策过程中同时考虑局部偶然性和全局一致性。本文引入了全局得分的概念 ——Elo 评级。它能更全面地反映模型相对表现的变化,涵盖不同时间和多次评估中的表现。通过引入 Elo 评级,可以在评估过程中同时考虑模型在单场比赛中的局部表现和在多轮比赛中的全局表现,从而提供一个更为稳健和准确的模型综合能力度量,这有助于降低较弱模型由于偶然的、不具代表性的投票而获胜的风险。
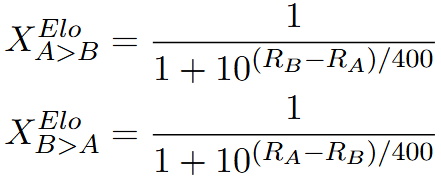
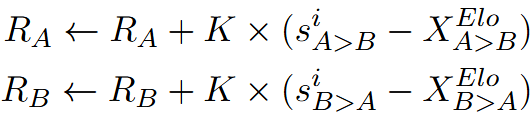
最后的 response 分数由 Elo 评级和裁判投票加权得到:

每一个 response 都要和所有对手的 response 比较,因此该分数代表了当前 response 的组内相对优势。
2.4 Final Training
本文得到的数据格式为 instruction、来自于各个参赛者的 response、各 response 对应的分数。这种数据格式可以支持多种 post-training 方法,比如 SFT、DPO、KTO 等等。本文采用 SFT,将组内分数最高的 response 作为 gold output,使得 WarriorCoder 在训练中可以融合各个参赛者的优势,集百家之长。
03 实验
3.1 主要结果
表 1 显示了 WarriorCoder 在 code generation benchmark 上的表现。与同类工作相比,WarriorCoder 在 HumanEval、HumanEval+、MBPP 和 MBPP + 上取得了 SOTA。值得注意的是,WarriorCoder 完全不需要私有大模型(如 GPT-4 等)就取得了惊艳的效果。
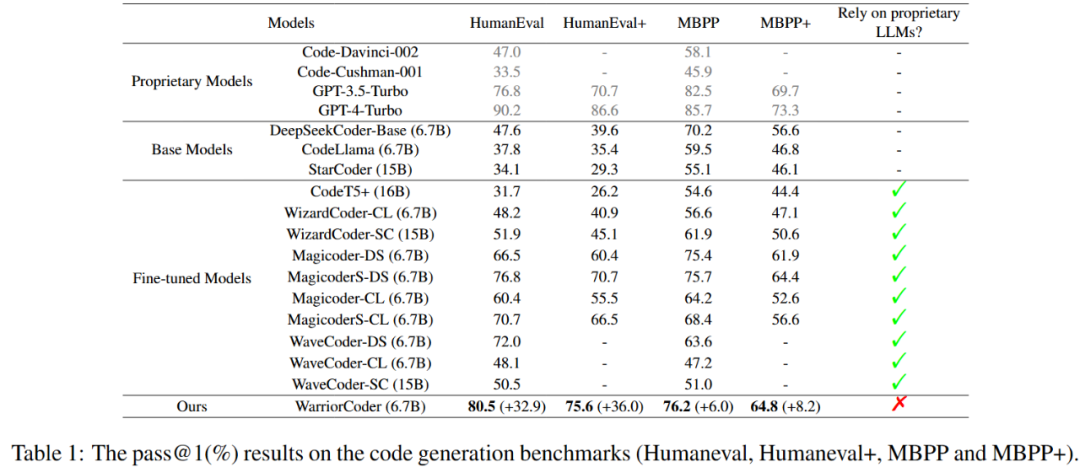
表 1
此外在 code reasoning benchmark 和 libraries using benchmark 上,WarriorCoder 也取得了卓越的成绩。如表 2 和表 3 所示,WarriorCoder 在绝大多数指标上表现最优,甚至超越了 15B 和 34B 等更大量级的模型。这也证明了本文提出的方法具有良好的泛化性,可以让模型从多个代码专家大模型处获得多种不同的能力。
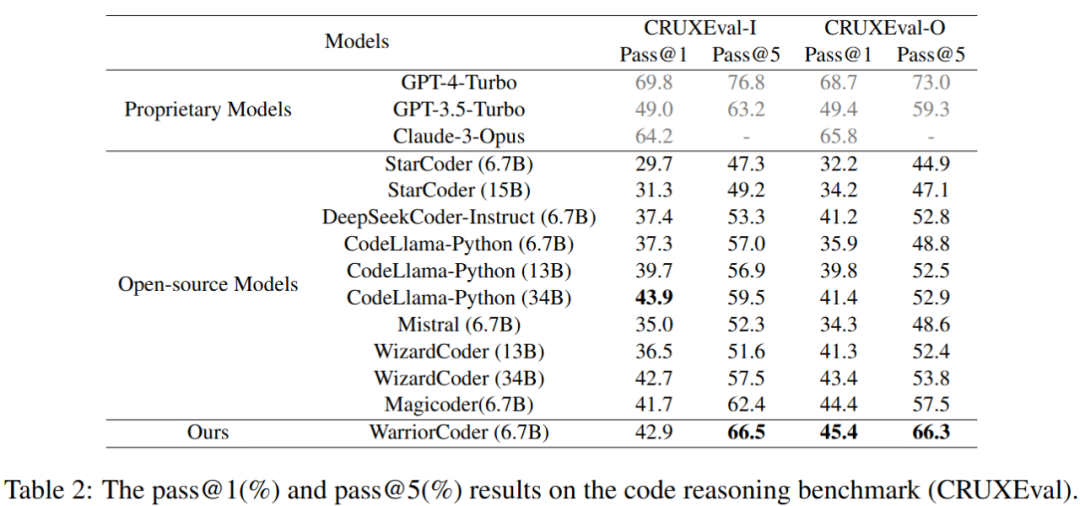
表 2

表 3
3.2 数据分析
本文还对所构造的训练数据进行了分析,从 Dependence、Diversity、Difficulty 三个角度进行研究。
Dependence
此前的工作往往会基于一些现有的代码数据集(如)进行扩展、数据增强,而本文则是完全从零开始构造全新的数据。如图 5 所示,作者计算了训练数据与两个常用代码数据集的重叠程度(rouge 指标),绝大多数指令与 codealpaca 和 codeultrafeedback 的 ROUGE 得分低于 0.3,表明它们与现有数据集中的指令在内容上存在较大差异。值得注意的是,挖掘出的指令中没有任何一项 ROUGE 指标超过 0.6,这进一步证明了这些指令来源于专家大模型的内部分布,而非现有训练数据的简单复制或扩展。因此,这些指令更新颖、具有更高的独立性,这对于训练尤为宝贵。
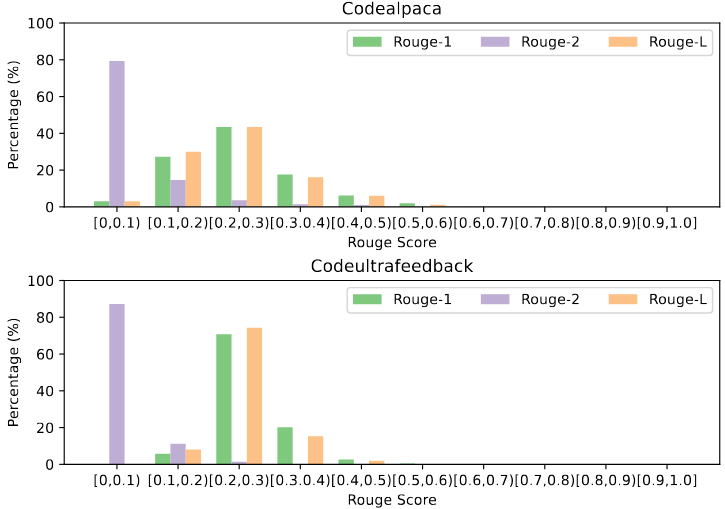
图 5
Diversity
表 4 展示了训练数据的构成,涵盖了 7 种不同的 code 任务,这也是为什么 WarriorCoder 能够在多个 benchmark 上表现优异的原因。值得注意的是 code reasoning 仅占比 2.9% 就使得 WarriorCoder 在相关 benchmark 上具有惊人表现,这说明了本文提出的方法具有很大潜力,如果针对模型的弱点定向挖掘数据可以让模型能力更上一层楼。此外,图 6 的热力图也展示了参赛者对抗结果,即便是再强的模型也终究有表现不好的时候,而 WarriorCoder 仅向当前指令下分数最高的 winner response 学习。

表 4
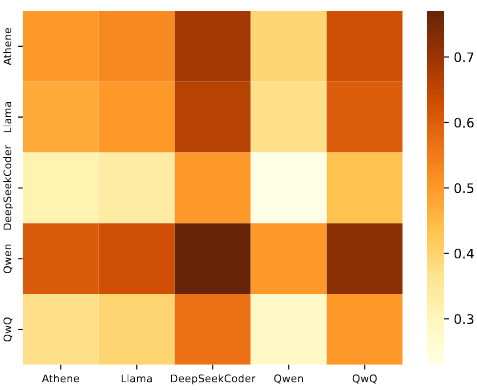
图 6
Difficulty
图 7 展示了不同模型产生的指令的难度比例。大多数指令的难度处于 good 等级,得分在 6 到 8 之间。被评为 excellent(得分 9-10)的指令仅占数据集的一小部分,表明高度复杂或高级的任务相对较为稀少。作者将得分低于 6 的指令被排除在训练集之外,因为它们往往要么过于简单,要么过于模糊,这样的指令会对训练阶段有害,甚至可能削弱模型的性能和泛化能力。
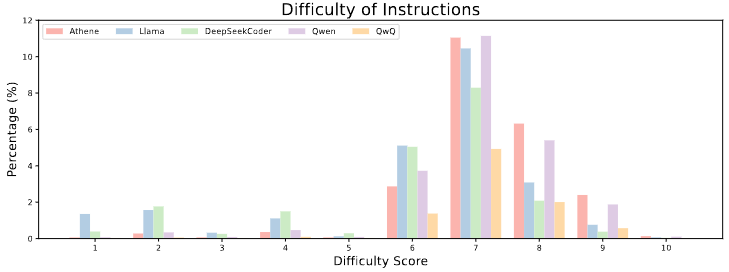
图 7
04 相关资源
虽然作者当前并未开源模型,但是我们发现已经有人复现了作者的工作,地址如下:
项目链接:https://huggingface.co/HuggingMicah/warriorcoder_reproduce




























