一、何为大模型?
大模型,英文名叫Large Model,也被称为基础模型(Foundation Model)。
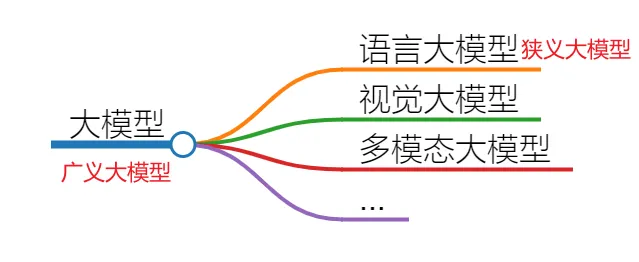
我们通常说的大模型,主要指的是其中最常用的一类——大语言模型(Large Language Model,简称LLM)。除此之外,还有视觉大模型、多模态大模型等。所有这些类别合在一起,被称为广义的大模型;而狭义的大模型则特指「大语言模型」。
1. 大模型的本质
从本质上来讲,大模型是包含超大规模参数(通常在十亿个以上)的神经网络模型。这些参数使得大模型能够处理和理解复杂的任务,如自然语言处理、图像识别等。
2. 神经网络的基础
神经网络是AI领域目前最基础的计算模型。它通过模拟大脑中神经元的连接方式,能够从输入数据中学习并生成有用的输出。
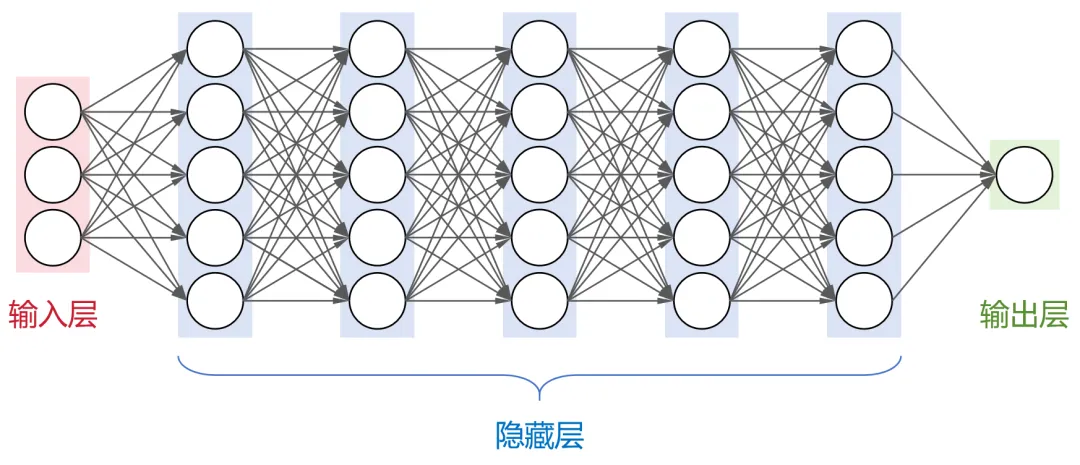
如下图所示,一个典型的神经网络结构包括:
- 输入层:接收外部输入数据。
- 隐藏层:多个中间层,每层神经元与下一层的所有神经元都有连接(即全连接神经网络),负责数据的特征提取和转换。
- 输出层:生成最终的输出结果。
常见的神经网络架构有:
- 卷积神经网络(CNN):主要用于图像处理。
- 循环神经网络(RNN):适用于序列数据处理,如时间序列分析。
- 长短时记忆网络(LSTM):改进版的RNN,能更好地处理长期依赖问题。
- Transformer架构:目前业界大部分大模型都采用了这种架构,尤其擅长处理自然语言任务。
二、大模型的“大”体现在哪些方面?
大模型的“大”,不仅仅是参数规模大,还包括以下几个方面:
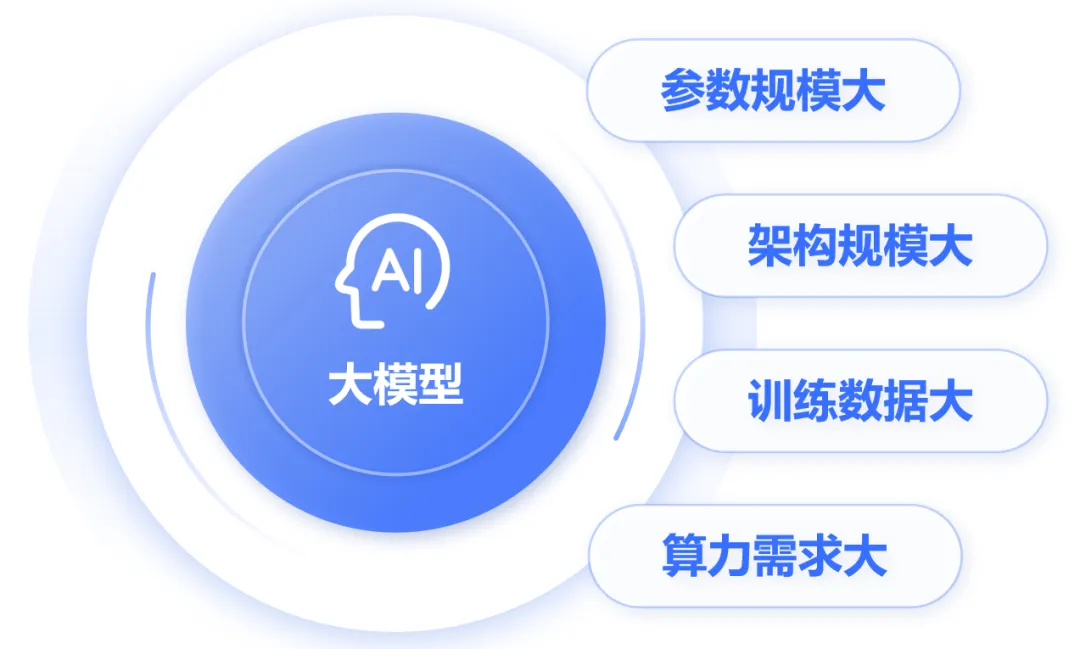
- 参数规模大:大模型包含数十亿甚至数千亿个参数,使其能够捕捉更复杂的模式和关系。
- 架构规模大:大模型通常具有非常深的网络结构,层数可达几十层甚至上百层。
- 训练数据大:大模型需要海量的数据进行预训练,以确保其具备广泛的知识和能力。
- 算力需求大:训练大模型需要强大的计算资源,如高性能GPU集群或TPU,以支持大规模的并行计算。
以OpenAI公司的GPT-3为例,共有96层隐藏层,每层包含2048个神经元,其架构规模非常庞大。
大模型的参数数量和神经元节点数之间存在一定的关系。简单来说,神经元节点数越多,参数也就越多。GPT-3整个模型的参数数量约为1750亿个。
GPT-3的训练数据也非常庞大,采用了多种高质量的数据集进行预训练:
- CC数据集:4千亿词
- WebText2:190亿词
- BookCorpus:670亿词
- 维基百科:30亿词
这些数据集加起来,原始数据总量达到了45TB,即使经过清洗后也有570GB。如此海量的数据确保了GPT-3具备广泛的知识和能力,能够在各种自然语言任务上表现优异。
还有算力需求。很具公开数据显示,训练GPT-3大约需要3640PFLOP·天。如果使用512张NVIDIA A100 GPU(单卡算力195 TFLOPS),大约需要1个月的时间。实际上,由于训练过程中可能会出现中断或其它问题,实际所需时间可能会更长。
总而言之,大模型就是一个虚拟的庞然大物,具有复杂的架构、庞大的参数量、依赖海量数据,并且训练过程非常烧钱。
而参数较少(一般在百万级以下)、层数较浅的小模型,具有轻量级、高效率和易于部署的特点,适用于数据量较小、计算资源有限的垂直领域场景,如简单的文本分类、情感分析等任务。
三、大模型是如何训练出来的?
众所周知,大模型可以通过学习海量数据,吸收数据里面的“知识”。然后再对知识进行运用,例如回答问题、生成内容等。
而「学习知识的过程,就是训练过程。运用知识的过程,即为推理。」
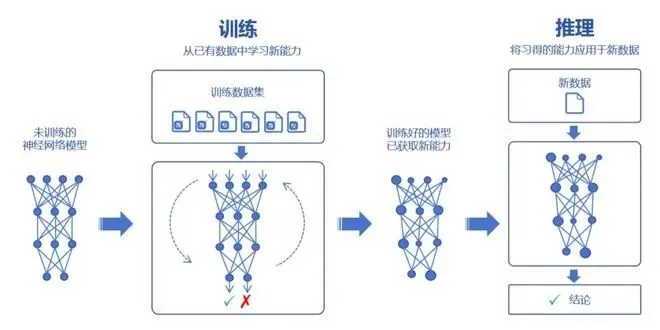
大模型的训练,又分为两个主要环节:预训练(Pre-training)和微调(Fine-tuning)。
1. 预训练
在预训练时,首先需要选择一个合适的模型框架,例如Transformer。然后,通过“投喂”前面提到的海量数据,让大模型学习到通用的特征表示。
(1) 为什么大模型具有强大的学习能力?
大模型之所以具备如此强大的学习能力,主要归功于其庞大的参数规模和复杂的神经网络结构。我们可以从以下几个方面来理解这一点:
① 神经元与权重的关系
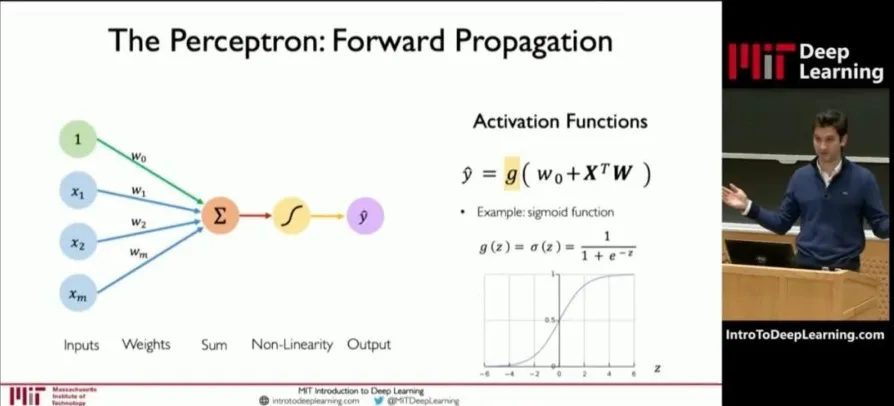
如上图,深度学习模型中的每个神经元可以看做是一个函数计算单元。输入x经过一系列线性变换和非线性激活函数后,产生输出y。这个过程可以用以下公式表示:
其中,
- W是权重(weights),决定了输入特征对模型输出的影响程度。
- b是偏置(bias),影响神经元的激活阈值,即神经元对输入信号的敏感程度。
- f是激活函数,如ReLU、Sigmoid等,用于引入非线性特性。
权重是最主要的参数之一。通过反复训练,模型不断调整权重,使其能够更好的拟合训练数据。「这也就是训练的核心意义——找到最合理的权重和偏置组合,使得模型能够在新数据上表现良好。」
② 参数与学习能力的关系
参数越多,模型通常能够学习到更复杂的模式和特征,从而在各种任务上表现出更强的性能。
我们通常会说大模型具有两个特征能力——涌现能力和泛化能力。
当模型的训练数据和参数不断扩大,直到达到一定的临界规模后,会表现出一些未能预测的、更复杂的能力和特性。模型能够从原始训练数据中,自动学习并发现新的、更高层次的特征和模式。这种能力,被称为“涌现能力”。
“涌现能力”,可以理解为大模型的脑子突然“开窍”了,不再仅仅是复述知识,而是能够理解知识,并且能够发散思维。
泛化能力,是指大模型通过“投喂”海量数据,可以学习复杂的模式和特征,可以对未见过的数据做出准确的预测。就像董宇辉一样,书读得多了,有些书虽然没读过,他也能说几句。
③ 过拟合的风险
然而,参数规模越来越大,虽然能让大模型变得更强,但是也会带来更庞大的资源消耗,甚至可能增加“过拟合”的风险。
过拟合,即是指模型对训练数据学习得过于精确,以至于它开始捕捉并反映训练数据中的噪声和细节,而不是数据的总体趋势或规律。换句话说,模型变成了“书呆子”,只会死记硬背,不愿意融会贯通。
(2) 预训练使用的数据
预训练使用的数据是海量的未标注数据(几十TB)。之所以使用未标注数据,是因为互联网上存在大量的此类数据,很容易获取。而标注数据(基本上靠人工标注)需要消耗大量的时间和金钱,成本太高。
① 数据预处理
为了确保数据的质量和适用性,整个数据需要经过以下预处理步骤:
- 收集:从多个来源收集原始数据。
- 清洗:去除异常数据和错误数据。
- 脱敏:删除隐私信息,确保数据安全。
分类:对数据进行分类,使其更标准化,有利于后续训练。
② 获取数据的方式
获取数据的方式也是多样化的:
- 个人和学术研究:可以通过官方论坛、开源数据库或研究机构获取。
- 企业:既可以自行收集和处理,也可以直接通过外部渠道(市场上有专门的数据提供商)购买。
(3) 无监督学习方法
预训练模型通过无监督学习从未标注数据中学习到通用特征和表示。常见的无监督学习方法包括:
- 自编码器(Autoencoder):通过学习数据的压缩表示来进行重构。
- 生成对抗网络(GAN):通过生成器和判别器之间的对抗训练来学习数据分布。
- 掩码语言建模(Masked Language Modeling, MLM):随机遮蔽部分输入文本,让模型预测被遮蔽的部分。
- 对比学习(Contrastive Learning):通过对比相似和不相似的数据样本,学习数据的表示。
2. 微调
预训练学习之后,我们得到了一个通用大模型,这种模型虽然具备广泛的知识和能力,但在完成特定任务时往往表现不佳。因此,我们需要对模型进行微调。
(1) 什么是微调?
「微调(Fine-tuning)」是给大模型提供特定领域的标注数据集,对预训练的模型参数进行微小的调整,使其更好地完成特定任务。通过微调,可以显著提升模型在特定任务上的性能。
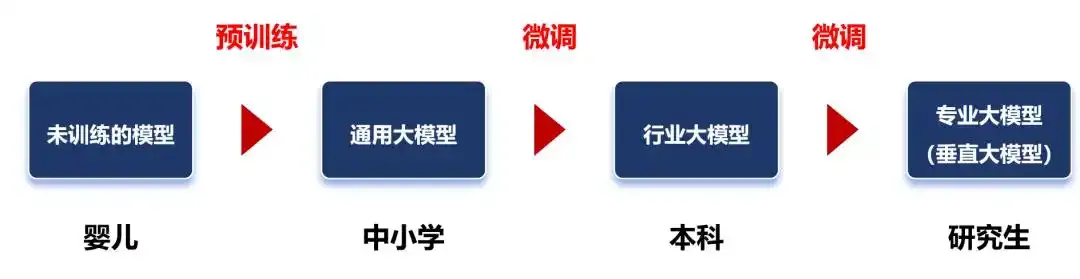
微调之后的大模型可以根据应用场景分为不同层次:
- 通用大模型:类似于中小学生,具有广泛的基础知识,但缺乏专业性。
- 行业大模型:基于特定行业的数据集进行微调。如金融证券大模型通过基于金融证券数据集的微调,可以得到一个专门用于金融分析和预测的大模型。这相当于大学本科生,具备了更专业的知识和技能。
- 专业大模型(或垂直大模型):进一步细分到更具体的领域,如金融领域的股票预测等。这相当于研究生,具备高度专业化的能力。
如下图所示。
(2) 微调的优势
- 减少计算资源需求:微调阶段使用的数据量远小于预训练阶段,因此对算力的需求也小很多。通常只需要少量的GPU或TPU即可完成微调过程。
- 提高任务特定性能:预训练模型在广泛的数据上学习到了通用特征,但这些特征不一定能很好地适用于特定任务。通过微调,模型可以在特定任务上表现出更高的准确性和效率。
- 避免重复投入:对于大部分大模型厂商来说,他们一般只做预训练,不做微调。而对于行业客户来说,他们一般只做微调,不做预训练。“预训练+微调”这种分阶段的大模型训练方式,可以避免重复的投入,节省大量的计算资源,显著提升大模型的训练效率和效果。
(3) 微调的具体步骤
① 选择合适的标注数据集:标注数据集是微调的关键。需要根据具体任务选择高质量的标注数据,确保数据的多样性和代表性。
② 调整模型参数:在微调过程中,通过对少量标注数据的训练,对预训练模型的参数进行微小的调整,使其更适合特定任务。常见的微调方法包括:
- 全层微调:调整所有层的参数。
- 部分层微调:仅调整部分层的参数,保留其他层的参数不变。
- 冻结部分层:冻结某些层的参数,仅调整新添加的层或特定层的参数。
③ 评估模型性能:微调完成后,需要对大模型进行全面评估。评估内容包括性能、稳定性和准确性等,以确认模型是否符合设计要求。常用的评估方法包括:
- 使用实际数据或模拟场景进行测试。
- 比较模型在不同任务上的表现。
- 分析模型的推理速度和资源消耗。
④ 部署与推理:评估和验证完成后,大模型就可以部署到生产环境中,用于推理任务。此时,模型的参数已经定型,不再变化,可以真正开始工作。推理过程就是用户通过提问或提供提示词(Prompt),让大模型回答问题或生成内容。
完整的流程图如下图所示:

四、大模型到底有什么作用?
1. 按训练数据类型分类的大模型
根据训练的数据类型和应用方向,大模型通常分为以下几类:
- 语言大模型(以文本数据进行训练)
- 音频大模型(以音频数据进行训练)
- 视觉大模型(以图像数据进行训练)
- 多模态大模型(结合文本、图像、音频等多种模态的数据)
每种类型的大模型在不同领域中发挥着重要作用。其中,
(1) 语言大模型
应用场景:自然语言处理(NLP)
功能特点:
- 理解、生成和处理人类语言:能够理解和生成高质量的自然语言文本。
- 文本内容创作:生成文章、诗歌、代码等。
- 文献分析:自动摘要、关键词提取、情感分析等。
- 机器翻译:将一种语言翻译成另一种语言。
- 对话系统:如ChatGPT,用于构建智能聊天机器人。
典型应用:
- 内容创作:自动生成新闻报道、博客文章、技术文档等。
- 客服支持:自动化客户服务,回答用户问题。
- 教育辅助:帮助学生学习语言、编写作文等。
- 法律文件处理:审查合同、撰写法律意见书等。
(2) 音频大模型
应用场景:语音识别与合成
功能特点:识别和生成语音内容:能够准确识别语音并转换为文本,或根据文本生成自然的语音。
典型应用:
- 语音助手:如Siri、Alexa等智能语音助手。
- 语音客服:自动应答电话客服系统。
- 智能家居控制:通过语音命令控制家电设备。
- 语音转文字:会议记录、采访转录等。
(3) 视觉大模型
应用场景:计算机视觉(CV)
功能特点:识别、生成和修复图像:能够识别物体、场景、人脸等,并生成或修复图像。
典型应用:
- 安防监控:实时监控和异常检测。
- 自动驾驶:识别道路、行人、交通标志等。
- 医学影像分析:辅助医生诊断疾病,如X光、CT扫描等。
- 天文图像分析:识别星系、行星等天体。
(4) 多模态大模型
应用场景:跨领域任务
功能特点:整合并处理来自不同模态的信息:可以处理文本、图像、音频和视频等多种形式的数据。
典型应用:
- 文生图:根据文本描述生成相应的图像。
- 文生视频:根据文本描述生成视频内容。
- 跨媒体搜索:通过上传图片搜索相关的文字描述,或通过文字搜索相关图片。
- 多媒体内容创作:生成包含文本、图像、音频的综合内容。
2. 按应用场景分类的大模型
除了按照数据类型分类,大模型还可以根据具体应用场景进一步细分。
- 金融大模型:用于风险管理、信用评估、交易监控、市场预测、合同审查、客户服务等。
- 医疗大模型:用于疾病诊断、药物研发、基因分析、健康管理等。
- 法律大模型:用于法律咨询、合同审查、案例分析、法规检索等。
- 教育大模型:用于个性化学习、在线辅导、考试评估、课程推荐等。
- 代码大模型:用于代码生成、代码补全、代码审查、编程助手等。
- 能源大模型:用于能源管理、故障预测、优化调度等。
- 政务大模型:用于政策分析、舆情监测、公共服务等。
- 通信大模型:用于网络优化、故障诊断、服务质量提升等。
五、大模型的发展趋势
截至2024年3月25日,中国10亿参数规模以上的大模型数量已经超过100个,号称“百模大战”。这些大模型的应用领域、参数规模各有不同,但背后都是高昂的成本。根据行业估测的数据,训练一个大模型的成本可能在几百万美元到上亿美元之间。例如,GPT-3的训练成本约为140万美元,而Claude 3模型的训练费用高达约1亿美元。
随着行业的逐渐理性化,大模型的发展趋势也发生了显著变化,主要体现在以下几个方面:
(1) 从追求参数规模到注重实际应用
- 头部企业继续探索超大规模模型:尽管大部分企业已经将万卡和万亿参数视为天花板,但是仍有一些头部企业在死磕参数规模更大的超大模型(拥有数万亿到数千万亿个参数),如OpenAI、xAI等。马斯克宣布xAI团队成功启动了世界上最强大的AI训练集群,由10万块H100组成,主要用于Grok 2和Grok 3的训练和开发。
- 其他企业转向实用化:对于大部分企业来说,再往上走的意愿不强烈,钱包也不允许。因此,越来越多的企业将关注点从“打造大模型”转向“使用大模型”,如何将大模型投入具体应用、吸引更多用户、通过大模型创造收入成为各大厂商的头等任务。
(2) 大模型的轻量化与端侧部署
- AI手机、AI PC、具身智能的概念越来越火:为了将大模型的能力下沉到终端设备,AI手机、AI PC、具身智能等概念成为新的发展热点。高通、联发科等芯片厂商推出了具有更强AI算力的手机芯片,OPPO、vivo等手机厂商也在手机中内置了大模型,并推出了许多原生AI应用。
- 第三方AI应用的数量激增:根据行业数据显示,具有AI功能的APP数量已达到300多万款。2024年6月,AIGC类APP的月活跃用户规模达6170万,同比增长653%。
- 轻量化技术的应用:为了在资源受限的设备上运行,大模型将通过剪枝、量化、蒸馏等技术进行轻量化,保持性能的同时减少计算资源需求。这使得大模型可以在移动设备、嵌入式系统等环境中高效运行。
(3) 开源与闭源并行
- 开源大模型的广泛应用:大部分大模型是基于开源大模型框架和技术打造的,实际上是为了迎合资本市场的需求或蹭热度。开源大模型为中小型企业提供了低成本进入AI领域的途径,促进了创新和应用的多样化。
- 闭源大模型的高端竞争:有能力做闭源大模型的企业并不多,但这些企业的闭源大模型往往具备更高的安全性和定制化能力,适用于对数据隐私和性能要求较高的场景。
(4) 多模态融合的趋势
- 跨领域任务处理:多模态大模型结合了NLP和CV的能力,通过整合并处理来自不同模态的信息(文本、图像、音频和视频等),可以处理复杂的跨领域任务,如文生图、文生视频、跨媒体搜索等。
六、大模型会带来哪些挑战?
大模型确实是一个强大的工具,能够帮助我们节约时间、提升效率,但同时也是一把双刃剑,带来了多方面的挑战。以下是大模型在伦理、法律、社会和经济层面的主要挑战:
(1) 影响失业率
- 岗位替代:大模型所掀起的AI人工智能浪潮可能导致一些人类工作岗位被替代,尤其是那些重复性高、规则明确的工作,如客服、数据录入、内容审核等。
- 失业率上升:随着自动化程度的提高,短期内可能会导致失业率上升,给社会稳定带来压力。
(2) 版权与知识产权问题
- 内容生成争议:大模型基于已有数据进行学习,生成的内容(文本、图像、音乐、视频等)可能引发版权和知识产权问题。这些内容虽然帮助了创作,但也“引用”了人类创作者的作品,界限难以区分。
- 打击创作热情:长此以往,可能会打击人类的原生创作热情,减少原创作品的数量和质量。
(3) 算法偏见和不公平
- 偏差传递:训练数据中存在的偏差会导致大模型学习到这些偏差,从而在预测和生成内容时表现出不公平的行为。例如,性别、种族、宗教等方面的偏见可能被无意中强化。
- 社会影响:大模型生成的内容可能被用于政治宣传和操纵,影响选举和公共舆论,进一步加剧社会不平等。
(4) 被用于犯罪
- 恶意用途:大模型可以生成逼真的文本、图像、语音和视频,这些内容可能被用于诈骗、诽谤、虚假信息传播等恶意用途。
- 监管难度:由于大模型生成的内容难以区分真假,给监管带来了巨大挑战。
(5) 能耗问题
- 资源消耗:大模型的训练和推理需要大量的计算资源,这不仅增加了成本,还带来了巨大的碳排放。
- 无意义的碳排放:很多企业为了服务于资本市场或跟风,盲目进行大模型训练,消耗了大量的资源,导致了无意义的碳排放。
总之,大模型在伦理、法律、社会和经济层面带来的挑战是多方面的,需要社会各界共同努力来解决。通过完善法律法规、加强技术研发、提高公众意识等手段,可以在充分发挥大模型优势的同时,有效应对这些挑战,推动人工智能的健康发展。