译者 | 李睿
审校 | 重楼
本文将深入探讨一个至关重要的问题:当系统出现问题时,应当如何有效地监控服务?

一方面,可以借助具备提醒功能的Prometheus,以及集成仪表板和其他实用功能的Kibana来增强监控能力。另一方面,在日志收集方面,ELK堆栈无疑是首选方案。然而,简单的日志记录往往不足以满足需求,因为它无法提供覆盖整个组件生态系统的请求流程的整体视图。
如果直观地展示请求流程呢?或者需要在系统间追踪关联的请求,该怎么办?这既适用于微服务,也适用于单体服务——有多少服务并不重要;重要的是如何管理它们的延迟。
事实上,每个用户请求可能要经过由独立服务、数据库、消息队列和外部API组成的复杂链路。
在这种复杂的环境中,很难准确地确定延迟发生的位置,确定链路的哪一部分是性能瓶颈,并在发生故障时快速找到其根本原因。
为了有效地应对这些挑战,需要一个集中的、一致的系统来收集遥测数据——包括跟踪、指标和日志。这正是OpenTelemetry和Jaeger发挥重要作用的地方。
了解基础知识
人们必须理解以下两个主要术语:
Trace ID
Trace ID是一个16字节的标识符,通常表示为32个字符的十六进制字符串。它在跟踪开始时自动生成,并在由特定请求创建的所有跨度中保持不变。这样可以很容易地看到请求是如何通过系统中的不同服务或组件传递的。
Span ID
跟踪中的每个单独操作都有自己的Span ID,它通常是一个随机生成的64位值。Span共享相同的Trace ID,但是每个Span都有一个唯一的Span ID,因此可以确定每个Span代表工作流的哪个部分(如数据库查询或对另一个微服务的调用)。
它们之间有何关联?
Trace ID和Span ID是相辅相成的。
当发起请求时,会生成一个Trace ID,并将其传递给所有相关服务。每个服务又会创建一个与Trace ID关联的、具有唯一Span ID的Span,从而能够可视化请求从开始到结束的完整生命周期。
那么,为什么不直接使用Jaeger呢?为什么需要OpenTelemetry(OTEL)及其所有规范?这是一个很好的问题!以下逐步分析。
- Jaeger是一个用于存储和可视化分布式跟踪的系统。它收集、存储、搜索和显示数据,显示请求如何通过服务“传输”。
- OpenTelemetry (OTEL)是一个标准(以及一组库),用于从应用程序和基础设施中收集遥测数据(跟踪、指标、日志)。它不依赖于任何单一的可视化工具或后端。
简而言之:
- OTEL就像一种“通用语言”和一组遥测收集库。
- Jaeger是用于查看和分析分布式跟踪的后端和用户界面。
如果已经有了Jaeger,为什么还需要OTEL?
1.单一的收集标准
在过去,有像OpenTracing和OpenCensus这样的项目。OpenTelemetry将这些收集指标和跟踪的方法统一到一个通用标准中。
2.易于集成
采用Go(或其他语言)编写代码,为自动注入拦截器和跨度添加OTEL库,就这样完成。之后,无论想把数据发送到哪里并不重要——Jaeger、Tempo、Zipkin、Datadog、自定义后端——OpenTelemetry都会负责管道。只需更换导出器即可。
3.不仅仅是跟踪
OpenTelemetry不仅涵盖跟踪,还处理指标和日志。最终,可以使用一个工具集来满足所有遥测需求,而不仅仅是跟踪。
4.以Jaeger为后端
如果主要对分布式跟踪可视化感兴趣,Jaeger是一个很好的选择。但默认情况下,它不提供跨语言检测。另一方面,OpenTetry提供了一种标准化的数据收集方式,然后可以决定将数据发送到哪里(包括Jaeger)。
在实践中,它们经常协同工作:
应用程序使用OpenTelemetry→通过OTLP协议通信→进入OpenTelemetry收集器(HTTP或gRPC)→导出到Jaeger进行可视化。

技术部分
系统设计(简要介绍)
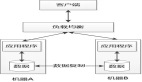
以下快速勾勒出几个服务,这些服务将执行以下操作:
1.购买服务——处理付款并记录在MongoDB中。
2.CDC与Debezium——监听MongoDB表中的更改,并将它们发送到Kafka。
3.购买处理器——使用来自Kafka的消息并调用Auth服务查找user_id进行验证。
4.认证服务——一种简单的用户服务。
总结:
- 3 Go services
- Kafka
- CDC (Debezium)
- MongoDB
代码部分
从基础设施开始。为了将所有内容汇集到一个系统中,将创建一个大型的DockerCompose文件,并从设置遥测开始。
注:所有代码都可以通过本文末尾的链接获得,包括基础设施。
还将配置收集器——收集遥测数据的组件。
在这里选择gRPC进行数据传输,这意味着通信将通过HTTP/2进行:
确保根据需要调整任何地址,这样就完成了基本配置。
OpenTelemetry (OTEL)使用两个关键概念——Trace ID和Span ID,它们有助于跟踪和监控分布式系统中的请求。
代码实现
现在了解如何让它在Go代码中实现这一点。需要以下导入:
然后,当应用程序启动时,在main()中添加一个函数来初始化跟踪器:
在设置跟踪之后,只需要在代码中放置span来跟踪调用。例如,如果想测量数据库调用(因为这通常是寻找性能问题的第一个地方),可以这样写:
在服务层进行跟踪,这太棒了!但可以更深入地分析数据库层:
现在,你对请求过程有了完整的了解。前往Jaeger UI,查询auth-service下的最后20条跟踪记录,将会在一个界面中看到所有的Span以及它们之间的关联方式。

现在,一切都是可见的。如果需要,可以将整个查询包含在标记中。需要记住,不应该使遥测过载——故意添加数据。在这里只是在演示什么是可能的,但包括完整的查询,通常不推荐这种方式。
gRPC客户机-服务器

如果希望查看跨越两个gRPC服务的跟踪,这很简单。需要做的就是从库中添加开箱即用的拦截器。例如,在服务器端:
在客户端,代码也很短:
就是这样!确保导出器配置正确,当客户端调用服务器时,将看到这些服务上记录的单个Trace ID。
处理CDC事件和跟踪
也想变更数据捕获 (CDC)的事吗?一个简单的方法是将Trace ID嵌入到MongoDB存储的对象中。这样,当Debezium捕获更改并将其发送给Kafka时,Trace ID已经是记录的一部分。
例如,如果使用的是MongoDB,可以这样做:

然后Debezium拾取这个对象(包括trace_id)并将其发送给Kafka。在消费者端,只需解析传入消息,提取trace_id,并将其合并到跟踪上下文中:
Go:
替代方案:使用Kafka标头
有时,将Trace ID存储在Kafka标头中比存储在负载本身中更容易。对于CDC工作流来说,这可能无法开箱使用——Debezium可能限制添加到标题中的内容。但是如果控制了生产者端(或者如果使用的是标准的Kafka生产者),那么可以使用Sarama等工具执行以下操作:
将Trace ID注入标头
在消费者端提取Trace ID
根据用例和CDC管道的设置方式,可以选择最有效的方法:
1.在数据库记录中嵌入Trace ID,使其通过CDC自然流动。
2.如果对生产者有更多的控制权,或者想避免增加消息有效载荷的大小,可以使用Kafka标头。
无论哪种方式,都可以确保跨多个服务的跟踪信息保持一致,即使事件是通过Kafka和Debezium异步处理的。
结论
使用OpenTelemetry和Jaeger提供详细的请求跟踪信息,帮助确定分布式系统中延迟发生的位置和原因。
在添加Prometheus之后,可以通过指标(性能和稳定性的关键指标)完善监控体系。这些工具共同构成了一个全面的可观测性堆栈,能够更快地检测和解决问题、优化性能以及提高系统的整体可靠性。
可以说,这种方法在微服务环境中显著加快了故障排除的速度,是在项目中最先实施的事项之一。
参考链接
原文标题:Control Your Services With OTEL, Jaeger, and Prometheus,作者:Ilia Ivankin