1. 高可用复杂度模型
- 核心思想:遵循“冗余法则”,通过集群化实现高可用,避免单点故障。
a.单机高可用不存在:单机无法冗余,高可用必须依赖集群。
b.复杂度本质:冗余带来的复杂性,包括状态同步、故障切换、数据一致性等。
2. 计算高可用
2.1 任务分配
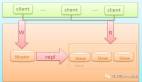
- 核心设计:通过任务分配器(独立服务器或SDK)将任务分发到多个服务器。
- 复杂度分析:
a.任务分配器需管理服务器列表(配置文件或ZooKeeper)。
b.需动态监控服务器状态,故障时快速切换。
c.算法选择(轮询、哈希、权重等)影响负载均衡。
- 关键点:高性能架构关注正常处理,高可用架构关注异常容错。
2.2 任务分解
- 核心设计:按业务逻辑拆分服务器角色(如接入层、逻辑层、存储层)。
- 复杂度分析:
a.任务分解器需记录任务与服务器的映射关系。
b.局部故障隔离,避免业务互相影响。
- 案例:微信服务拆分(独立接入服务器+业务集群)。
3. 存储高可用
3.1 数据复制格式
- 命令复制(如Redis AOF):
a.优点:数据量小,实现简单。
b.缺点:可能不一致(依赖SQL函数)。
c.场景:增量复制。
- 文件复制(如MySQL Row格式):
- 优点:数据一致性强。
- 缺点:流量大。
- 场景:全量复制。
- 混合复制(如Redis RDB+AOF):
- 折衷方案,平衡一致性与性能。
3.2 数据复制方式
- 同步复制:
a.强一致性,但写入性能低(需所有节点确认)。
b.场景:主备架构。
- 异步复制:
a. 高性能,容忍节点故障,但可能数据丢失。
b.场景:数据存储集群。
- 半同步复制(如MySQL半同步):
a. 折衷方案,部分节点确认即可。
- 多数复制(如ZooKeeper):
a.强一致性+高可用性,但实现复杂。
b.场景:分布式一致性系统(OceanBase)。
3.3 状态决策模式
- 独裁式(如Redis Sentinel):
a.决策者单点需高可用(依赖ZooKeeper/Raft)。
b.一致性中等,适用于通用业务。
- 协商式(如心跳检测):
a.简单但易双主(需双通道缓解)。
b.一致性弱,适合内部系统。
- 民主式(如Raft/ZAB算法):
a.高一致性+高可用,但可能脑裂(需Quorum控制)。
b.场景:余额、库存等高一致性需求。
4. 案例与模式
- Redis:命令复制(AOF)+文件复制(RDB),异步+半同步。
- MySQL:命令复制(Statement)+数据复制(Row),异步+半同步。
- Hadoop/ZooKeeper:独裁式决策(依赖ZooKeeper集群)。
- MongoDB:民主式选举(Raft算法)。
5. 核心结论
- 高可用本质:通过冗余应对故障,集群是必然选择。
- 设计核心:状态决策机制(独裁/协商/民主)决定架构复杂度。
- 数据复制权衡:一致性、性能、故障容忍度需平衡。
- 与高性能对比:高可用更复杂(需冗余管理、状态决策、异常处理)。
 图片
图片