DeepSeek 的开源周终于迎来了最后一天。
今天他们开源了一个名为 3FS(Fire-Flyer File System)的系统。这是一种并行文件系统,它利用现代固态硬盘(SSD)和远程直接内存访问(RDMA)网络的全部带宽,能够加速和推动 DeepSeek 平台上所有数据访问操作。
它有以下优势:
- 在 180 节点集群中实现了 6.6 TiB/s 的聚合读取吞吐量;
- 在 25 节点集群的 GraySort 基准测试中达到 3.66 TiB/min 的吞吐量;
- 每个客户端节点在 KVCache 查找时可达到 40+ GiB/s 的峰值吞吐量;
- 采用分离式架构,具有强一致性语义。
在应用场景方面,它支持训练数据预处理、数据集加载、检查点保存 / 重新加载、用于推理的嵌入向量搜索和 KVCache 查找。DeepSeek V3、R1 模型均采用了这个系统。
- 开源链接:https://github.com/deepseek-ai/3FS
- Smallpool(3FS 上的数据处理框架):https://github.com/deepseek-ai/smallpond
如果技术语言不好理解,可以参考这位研究者给出的通俗解释:
同时,这位研究者也是一位早期使用者,他评价说,「DeepSeek 的 3FS 系统快得惊人,它处理数据的速度快到可以在我还没来得及拖延的时候就已经训练好了一个能帮我报税的 AI。它拥有 6.6 TiB/s 的读取速度,这使它成为文件系统界的『博尔特』(世界最快短跑运动员)。你眨眼的功夫,数据就已经处理完毕了。而将这个超级快速的系统开源,就像是给整个 AI 社区免费赠送了一艘宇宙飞船,让其他所有竞争者都不得不加紧脚步追赶。」
3FS 有什么用?
Fire-Flyer File System 是一种高性能分布式文件系统,专为解决 AI 训练和推理工作负载的挑战而设计。它利用现代 SSD 和 RDMA 网络提供共享存储层,简化了分布式应用程序的开发。
3FS 的主要特点和优势包括:
(1) 性能和可用性
- 分离式架构。结合了数千个 SSD 的吞吐量和数百个存储节点的网络带宽,使应用程序能够以不受位置限制的方式访问存储资源。
- 强一致性。实现了带有分配查询的链式复制(CRAQ)以保证强一致性,使应用程序代码简单且易于理解。
- 文件接口。开发了由事务性键值存储(如 FoundationDB)支持的无状态元数据服务。文件接口广为人知且随处可用。无需学习新的存储 API。
(2) 多样化工作负载
- 数据准备。将数据分析管道的输出组织成层次化的目录结构,并高效管理大量中间输出。
- 数据加载器。通过支持跨计算节点对训练样本的随机访问,消除了预取或打乱数据集的需求。
- 检查点保存。支持大规模训练的高吞吐量并行检查点保存。
- 用于推理的 KVCache。为基于 DRAM 的缓存提供了一种成本效益高的替代方案,提供高吞吐量和显著更大的容量。
3FS 性能如何
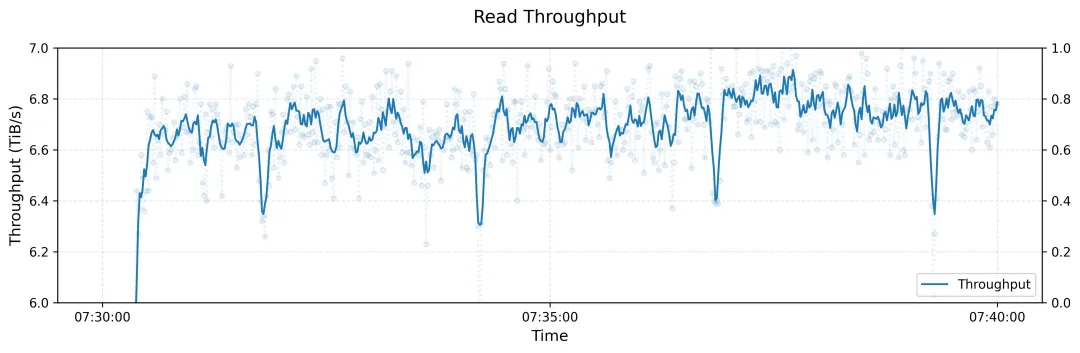
(1) 峰值吞吐量
下图展示了在大型 3FS 集群上进行读取压力测试的吞吐量。该集群由 180 个存储节点组成,每个存储节点配备 2×200Gbps InfiniBand 网卡和 16 个 14TiB NVMe SSD。大约 500+ 个客户端节点用于读取压力测试 ,每个客户端节点配置 1x200Gbps InfiniBand 网卡。在有训练作业的背景流量情况下,最终聚合读取吞吐量达到约 6.6 TiB/s。
(2) 灰度排序
DeepSeek 利用 GraySort 基准对 smallpond 进行了评估,该基准可衡量大规模数据集的排序性能。具体实现采用两阶段方法:(1) 使用键的前缀位通过 shuffle 对数据进行分区,以及 (2) 分区内排序。两个阶段都从 3FS 读取数据 / 向 3FS 写入数据。
测试集群由 25 个存储节点(2 个 NUMA 域 / 节点、1 个存储服务 / NUMA、2×400Gbps NIC / 节点)和 50 个计算节点(2 个 NUMA 域、192 个物理核心、2.2 TiB RAM 和 1×200 Gbps NIC / 节点)组成。对 8192 个分区中的 110.5 TiB 数据进行排序耗时 30 分 14 秒,平均吞吐量为 3.66 TiB / 分钟。
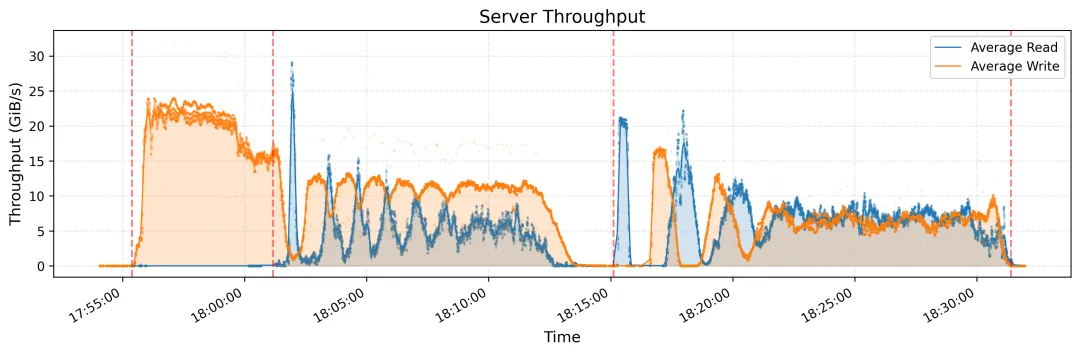
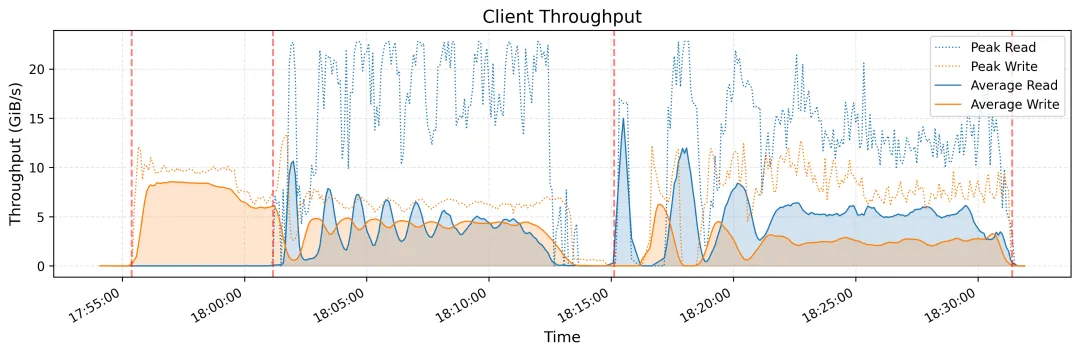
(3) KVCache
KVCache 是一种用于优化 LLM 推理过程的技术。它通过在解码器层中缓存先前 token 的 key 和 value 向量来避免冗余计算。

上图展示了所有 KVCache 客户端的读取吞吐量,突出显示了峰值和平均值,峰值吞吐量高达 40 GiB/s。下图展示了同一时间段内垃圾回收 (GC) 中删除操作的 IOPS。
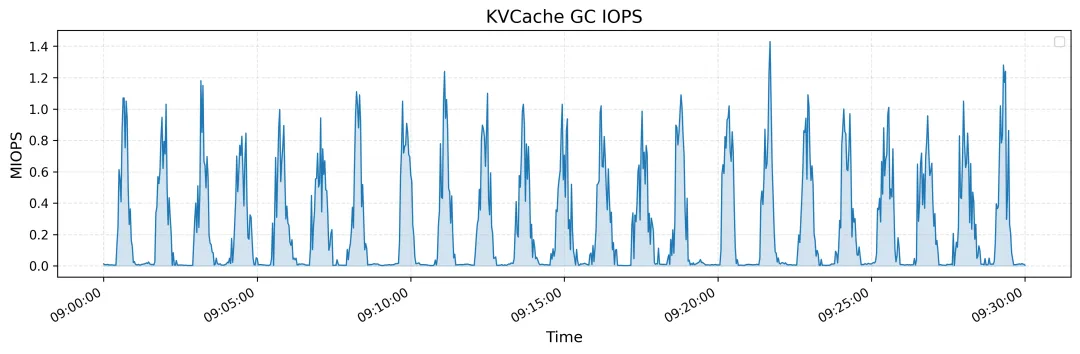
开源周「收官之作」,网友撒花
通过连续一周的高强度开源,DeepSeek 已经收获了一大波开发者的追随。
有开发者表示,3FS 和 Smallpond 是在 AI 数据处理方面树立了新标杆。

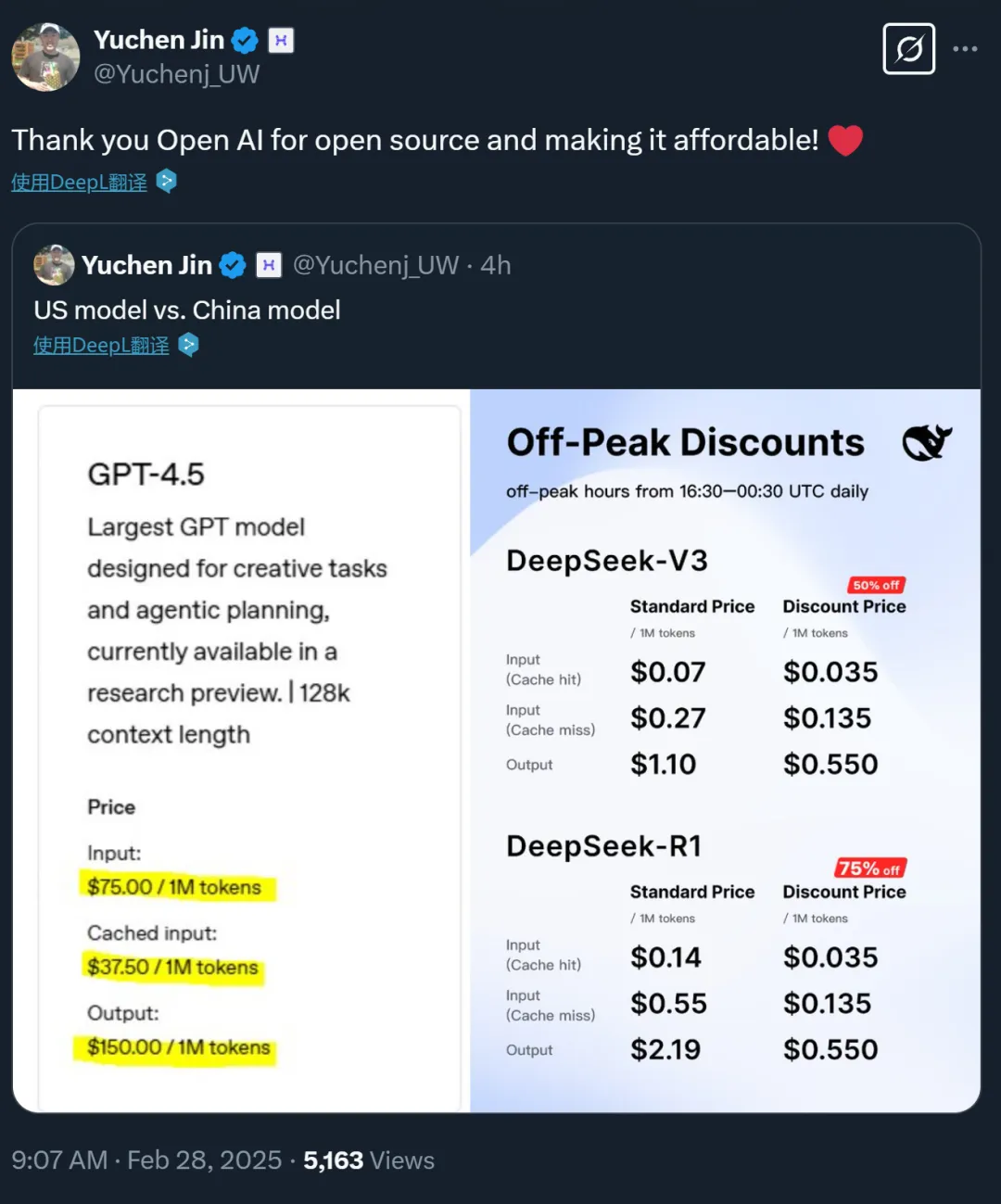
同时,OpenAI 刚刚发布的 GPT-4.5 也被拉出来对比价格:
最后,还有人许愿:DeepSeek V4、R2 和视频模型什么时候有?