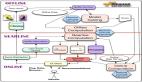
在如今大数据时代,如何高效地处理大量的实时数据并从中提取出有价值的信息,已经成为各大企业面临的核心挑战之一。尤其是在用户个性化推荐领域,实时数据流的处理能力对于提供准确、及时的推荐结果至关重要。Spring Boot作为广泛应用的后端框架,以其高效、易用的特性,成为了构建微服务架构和处理复杂业务逻辑的首选。而Flink作为一款高性能的流处理引擎,能够以毫秒级延迟处理海量数据,特别适合实时推荐、欺诈检测、实时分析等场景。
本篇文章将带你深入探讨如何结合Spring Boot 3.4与Apache Flink,构建一个高效、可扩展的用户个性化推荐系统。我们将从如何集成Flink到Spring Boot项目,如何利用Flink处理实时用户行为数据,到最终如何生成个性化推荐并反馈给用户,逐步展示这一解决方案的实现过程。在此过程中,我们还会讲解一些典型应用场景,帮助读者深入理解流处理技术的巨大潜力,尤其是如何通过技术优化提升用户体验,增强企业的竞争力。以下是几种常见的应用场景:
- 个性化推荐系统实时处理用户行为数据,动态更新用户画像并提供个性化的产品推荐。
- 事件驱动架构在微服务架构中处理跨服务消息,确保系统保持低延迟和高吞吐量。
- 欺诈检测实时分析金融交易或网络活动,识别并报警异常行为,减少潜在的损失。
- 流数据分析实时处理来自传感器或物联网设备的海量数据,分析用户行为,及时反馈信息。
- 日志处理对系统日志进行实时收集、解析和聚合,帮助开发者优化系统性能和排查故障。
- 实时报表生成生成实时的销售报告、市场趋势等,帮助决策者做出快速反应。
- 供应链管理实时监控库存、订单及物流信息,自动调整生产计划以响应需求变化。
- 社交媒体分析实时分析舆情,监测公众对品牌或话题的情绪反馈。
- 网络安全通过实时监控网络流量,检测并应对安全威胁。
代码演示:如何根据用户的行为实时生成个性化推荐
以下演示了如何通过SpringBoot和Flink的结合,处理Kafka中的用户行为数据,并生成个性化推荐结果。
添加必要的依赖
在pom.xml中添加以下依赖:
数据模型定义
定义两个模型类,用于表示用户行为数据和推荐结果。
编写Flink作业
使用Flink从Kafka中读取用户行为数据,计算热门产品,并生成个性化推荐。
启动Spring Boot应用
创建一个Spring Boot应用程序来启动Flink作业:
测试
确保您的Kafka和其他相关服务已经设置好,然后向user-behavior-topic发送消息,如下所示:
检查recommendations-topic中的消息,您将看到个性化推荐结果:
通过这一系列的步骤,您已经完成了一个基于SpringBoot与Flink集成的高效个性化推荐系统!
结论:
通过Spring Boot与Flink的深度结合,我们可以高效、实时地处理用户行为数据,进而为用户提供精准的个性化推荐。在本文中,我们不仅介绍了如何通过Flink从Kafka读取实时数据并处理,还展示了如何根据用户的行为生成推荐结果并返回给系统。借助Flink强大的流处理能力,企业能够在瞬息万变的市场环境中迅速响应用户需求,提供个性化的服务,从而提升用户满意度和粘性。
不仅如此,这一系统还具备了极高的可扩展性,可以应对不同规模的数据流并保证系统的高可用性。这为大数据时代的企业提供了一种可持续发展的解决方案,使其能够在海量的数据中提炼出真正的商业价值。
展望未来,随着数据量的不断增长和实时数据处理需求的日益增加,Spring Boot与Flink的结合将成为更多企业实现高效数据流处理、个性化推荐和实时决策的核心技术。本文所述的架构和实现方式,展示了技术如何驱动商业创新,也为企业在数字化转型过程中提供了一个重要的参考模型。