现在截图生成代码,已经来到了一个新高度——
⾸个⾯向现代前端代码⽣成的多模态⼤模型解决⽅案,来了!
而且是开源的那种。

(注:现代前端代码开发具有组件化、状态管理和数据驱动渲染、开发规范严格以及动态交互性强等特点。这些特点相互关联,共同构成了现代前端开发的复杂体系,对代码生成提出了更高要求。如基于React、Vue等框架的开发。)
这个模型叫做Flame,话不多说,直接来看效果。
例如截图让AI生成下面这个界面: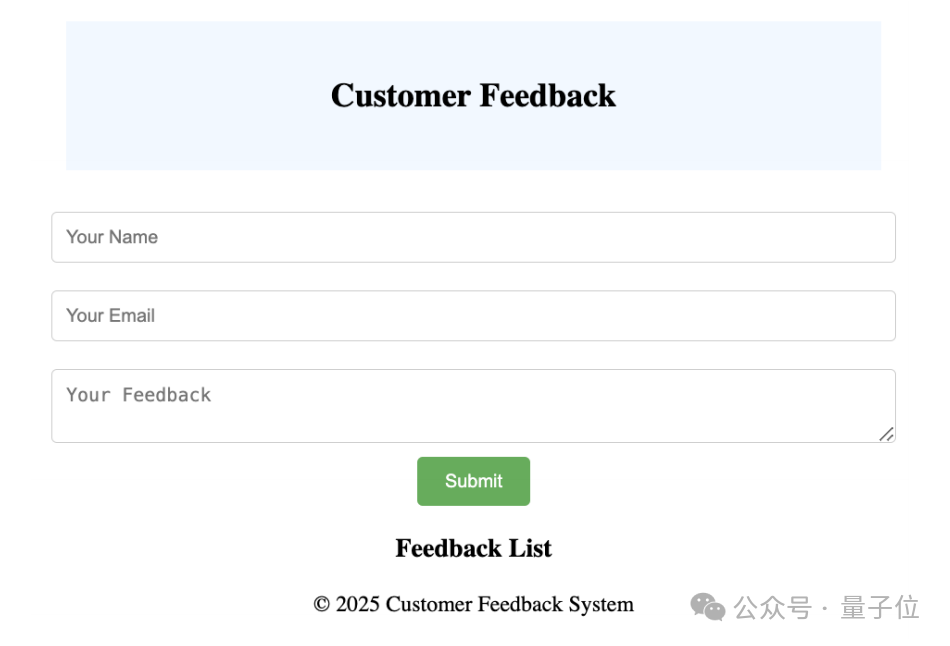
Flame模型在“看”完图片之后,给出来的代码是这样:
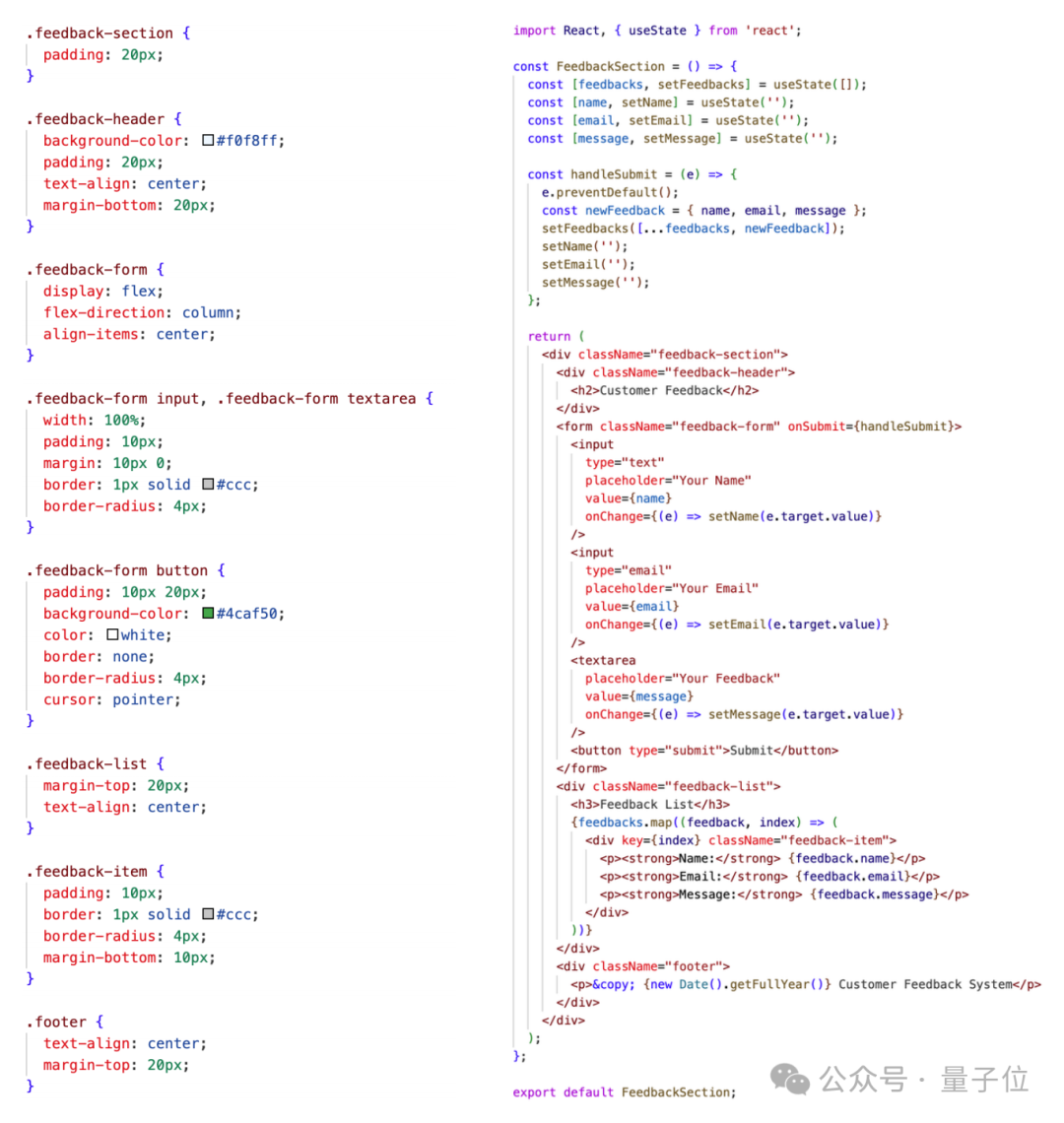
不难看出,Flame⽣成代码明显是符合现代前端开发规范的,包括⽐较清晰的外联样式以及模块化组件结构。
同时在组件的实现中正确定义了组件的各个状态、事件响应、以及基于数据的组件动态渲染。
然而,诚如GPT-4o这样顶尖的SOTA模型,可能也与现代前端开发的核⼼需求背道⽽驰,因为局限在于端到端复刻设计图的过程中只能产出静态组件。
例如同样的界面,GPT-4o的解法是这样的:

问题根源在于这类静态代码既⽆法⽀撑模块化架构,也难以⽀撑动态交互。
每个组件都是“⼀次性产物”,任何细微的需求开发和迭代,可能都要开发者开发⼤量定制化代码,甚⾄是推倒重来。
那么Flame模型又是如何解决这个问题的呢?
核心问题:数据稀缺
⼤型视觉语⾔模型(LVLM)在⽣成专业前端代码上表现不尽⼈意的根本原因在于数据稀缺。
现代前端开发流程⾮常复杂,⽐如像React这样的前端框架,强调组件化、状态管理和数据驱动的渲染⽅式。
这就要求⽣成的代码不仅要能⽤,还要符合开发规范,具备动态性和响应性。
然⽽,开源社区中⽀持前端开发的⾼质量图像-⽂本(代码)数据集极度稀缺。
像websight这样的数据集只涉及静态HTML,不适⽤于现代前端开发。
收集并构建⾼质量的训练数据⾯临许多挑战:
- 如何从公共代码库中提取有效代码片段?
- 如何在保持原有代码效果的情况下进行渲染?
- 如何⽣成符合⼯程师习惯的⼤量、多样化数据?
针对这些问题,Flame模型的团队给出了解法就是数据合成。
为提升LVLM在前端代码⽣成能⼒,我们设计了⼀整套⾃反思的智能体⼯作流,⽤于⽣成前端开发场景下的⾼质量数据。
该⼯作流不仅能⾃动从公共代码库中提取真实数据,还能够⾃主合成数据,⽣成专业、多样化的前端代码。
团队设计并实现了3种合成⽅法:

基于进化的数据合成(Evolution-Based Synthesis)
借鉴WizardLM的Evol-Instruct⽅法,通过随机进化⽣成多样化的代码。它采⽤两种策略:⼴度进化和深度进化。
⼴度进化通过改变代码的功能和视觉⻛格,⽣成新变体;深度进化则通过增加代码的技术复杂度,优化组件处理、状态管理和性能,提升代码的可靠性和可维护性。
通过不断进化,可以得到⼤量覆盖不同需求的前端代码。
基于瀑布模型的数据合成(Waterfall-Model-Based Synthesis)
模拟传统软件开发的瀑布流模型,确保⽣成的代码结构清晰、逻辑⼀致。从需求分析开始,推导出系统功能需求,设计UI布局和架构,保证代码符合现代前端开发的模块化和可扩展性要求。
接着,通过多轮迭代,将需求转化为具体的、可复⽤的前端组件和⻚⾯。这种⽅法⽣成的代码逻辑清晰,适合复杂功能的开发任务。
基于增量开发的数据合成(Additive Development Synthesis)
在现有代码基础上,逐步增加功能和复杂性。通过逐步集成状态管理、交互逻辑或API等功能模块,⽣成的代码能更好地满⾜实际开发需求。
这种⽅法强调逐步提升代码的功能和复杂度,确保每次扩展都最⼤可能符合最佳实践。
上述的三种⽅法不仅丰富了数据集的规模和多样性,还确保了数据质量与实际应⽤价值。
这些⽅法能够低成本⼤规模合成特定前端框架的图⽂数据,借助上述⽅法,Flame团队针对React框架构建了超过400k的多模态数据集。
同时,基于瀑布模型和增量开发的⽅法还⽀持多图场景下的数据合成、视觉思维链的合成,为更复杂场景下的前端代码⽣成提供了更多可能。
Flame:针对前端开发场景的VLM
Flame团队⼈⼯构建了⼀套包含80道测试题⽬的⾼质量测试集并通过改进后的Pass@k来评测多模态模型的前端代码⽣成能⼒。
如果⽣成的代码能够通过编译验证、符合编码规范,并且所渲染出的⻚⾯与输⼊的设计图⾜够相似,则认为该代码符合要求。
评测结果显⽰,当前顶级模型如GPT-4o,Gemini 1.5 Flash因其⽣成代码主要为静态代码,严重偏离代码规范,使其最⾼Pass@1仅为11%,⽽Flame在相同条件下达到了52%+,展现出了极⼤的潜⼒。
同时,同时,Flame仅⽤20w左右的数据量级即取得以上成果,进⼀步验证了上述数据合成⽅法的价值以及⾼质量数据集在多模态模型能⼒提升中的关键作⽤。

△左:测试图;右:Flame效果图
值得一提的是,将训练数据、数据合成流程、模型及测试集已经全⾯开源,感兴趣的小伙伴赶紧去看看吧~
GitHub地址:https://github.com/Flame-Code-VLM/Flame-Code-VLM/blob/main/README.md