在当今数字化时代,网络已成为计算机系统不可或缺的部分。无论是日常的网页浏览、文件传输,还是大规模数据中心的高效通信,网络数据包的收发都在其中扮演着重要角色。对于 Linux 系统而言,深入理解网络数据包的接收过程,是优化网络性能、解决网络问题的关键。
想象一下,你正在进行在线视频会议,突然画面卡顿、声音中断;或者在进行大规模数据传输时,速度远远低于预期。这些令人困扰的网络问题,很多都与 Linux 系统对网络数据包的接收处理过程紧密相关。而这一过程,涉及到从硬件层面的网卡,到软件层面的内核协议栈、中断处理机制等多个复杂环节。
通过深入剖析 Linux 下网络数据包的接收过程,我们不仅能够洞悉网络数据在系统内部的流转路径,还能明确各环节对网络性能的影响。这对于开发者、系统管理员来说,无疑是优化网络性能、解决网络故障的有力武器。它可以帮助我们在面对网络问题时,迅速定位问题根源,采取有效的解决措施,如调整网络配置、优化内核参数等,从而保障网络的稳定高效运行。
一、引言
这里深度理解一下在Linux下网络包的接收过程,为了简单起见,我们用udp来举例,如下:
上面代码是一段udp server接收收据的逻辑。只要客户端有对应的数据发送过来,服务器端执行recv_from后就能收到它,并把它打印出来。那么当网络包达到网卡,直到recvfrom收到数据,这中间究竟都发生过什么?
二、Linux网络基础
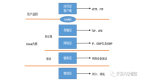
2.1 网络协议栈
在Linux内核实现中,链路层协议靠网卡驱动来实现,内核协议栈来实现网络层和传输层。内核对更上层的应用层提供socket接口来供用户进程访问。我们用Linux的视角来看到的TCP/IP网络分层模型应该是下面这个样子的。
 图片
图片
链路层,作为网络协议栈的最底层,主要负责将网络层传来的数据转换为物理信号,通过物理介质进行传输,并处理物理介质上的数据接收。在以太网环境中,链路层使用以太网协议,它定义了数据帧的格式,包括源 MAC 地址、目的 MAC 地址、类型字段以及数据部分等。
例如,当你的计算机向同一局域网内的另一台计算机发送数据时,链路层会在数据帧中填入对方的 MAC 地址,以便数据能够准确地发送到目标设备。ARP(地址解析协议)也工作在这一层,它用于将 IP 地址解析为对应的 MAC 地址。当主机需要向某个 IP 地址发送数据时,如果不知道该 IP 地址对应的 MAC 地址,就会发送 ARP 请求广播,目标主机收到后会回复其 MAC 地址,从而建立起 IP 地址与 MAC 地址的映射关系。
网络层,其主要职责是实现数据包的路由和转发,使数据能够在不同的网络之间传输。IP 协议是网络层的核心协议,它为每个网络设备分配唯一的 IP 地址,并负责将数据包从源 IP 地址发送到目的 IP 地址。IP 协议还支持数据包的分片与重组功能,当数据包的大小超过链路层的最大传输单元(MTU)时,IP 协议会将数据包进行分片,在到达目标主机后再进行重组。例如,当你访问外网的网站时,数据包会经过多个路由器的转发,每个路由器根据 IP 地址来决定数据包的下一跳路径,最终将数据包送达目标服务器。ICMP(互联网控制消息协议)也是网络层的重要协议,它用于在网络设备之间传递控制消息,如 ping 命令就是利用 ICMP 协议来测试网络的连通性。
传输层,主要负责为应用层提供端到端的通信服务,确保数据的可靠传输或高效传输。TCP(传输控制协议)和 UDP(用户数据报协议)是传输层的两个主要协议。TCP 是一种面向连接的、可靠的协议,它通过三次握手建立连接,在数据传输过程中使用序列号、确认号和重传机制来确保数据的完整性和顺序性。例如,在进行文件传输时,TCP 协议能够保证文件的每个字节都准确无误地到达对方。UDP 则是一种无连接的、不可靠的协议,它不保证数据的可靠传输,但具有传输速度快、开销小的特点,常用于对实时性要求较高的应用场景,如视频流、音频流等。比如,在观看在线视频时,UDP 协议可以快速地将视频数据传输给用户,即使偶尔有数据包丢失,也不会对用户体验造成太大影响。
这些不同层次的协议相互协作,共同完成了网络数据包的接收与发送过程。从物理介质上接收到的数据,会依次经过链路层、网络层和传输层的处理,最终被传递到应用层,供应用程序使用。
2.2 中断机制
在 Linux 网络数据处理中,中断机制起着至关重要的作用,它主要包括硬中断和软中断 。
硬中断,是由硬件设备产生的,用于通知 CPU 有紧急事件需要处理。当网卡接收到网络数据包时,会触发一个硬中断信号,通知 CPU 有新的数据到达。这个过程就像是门铃突然响起,提醒主人有访客到来。CPU 在接收到硬中断信号后,会立即暂停当前正在执行的任务,保存现场信息,然后跳转到对应的中断处理程序。对于网卡的硬中断处理程序,其主要任务是将接收到的数据从网卡的缓冲区拷贝到内存中,并进行一些初步的处理,如设置数据的相关标志位等。由于硬中断处理需要快速响应,以避免数据丢失,因此硬中断处理程序通常只执行一些紧急且耗时较短的操作。
软中断,是一种推后执行的机制,用于处理那些可以稍微延迟处理的任务。在硬中断处理完成后,会触发相应的软中断,将数据包的后续处理工作交给软中断来完成。软中断的处理函数通常在一个特定的上下文中执行,这个上下文允许执行一些相对耗时的操作,而不会影响硬中断的及时响应。例如,在网络数据处理中,软中断会对从网卡拷贝到内存中的数据包进行进一步的解析和处理,将其传递给相应的网络协议栈层进行后续处理。软中断的优势在于可以在合适的时机批量处理多个任务,提高系统的整体效率。与硬中断相比,软中断的触发不是由硬件直接产生,而是由软件在特定条件下触发,并且软中断的处理可以在多个 CPU 核心上并行进行,从而提高处理速度。
硬中断和软中断在 Linux 网络数据处理中紧密配合。硬中断负责快速响应硬件事件,及时将数据从硬件设备传输到内存;软中断则负责对数据进行后续的详细处理,将数据传递给相应的协议栈层进行进一步的分析和处理,确保网络数据能够被系统有效地接收和处理。
内核实现了网络层的 ip 协议,也实现了传输层的 tcp 协议和 udp 协议。这些协议对应的实现函数分别是 ip_rcv(),tcp_v4_rcv()和udp_rcv()。
网络协议栈是通过函数 inet_init() 注册的,通过inet_init,将这些函数注册到了inet_protos和ptype_base数据结构中了。如下图:
相关代码如下:
上面的代码中我们可以看到,udp_protocol结构体中的handler是udp_rcv,tcp_protocol结构体中的handler是tcp_v4_rcv,通过inet_add_protocol被初始化了进来。
inet_add_protocol函数将tcp和udp对应的处理函数都注册到了inet_protos数组中了。
再看dev_add_pack(&ip_packet_type);这一行,ip_packet_type结构体中的type是协议名,func是ip_rcv函数,在dev_add_pack中会被注册到ptype_base哈希表中。
这里我们需要记住inet_protos记录着udp,tcp的处理函数地址,ptype_base存储着ip_rcv()函数的处理地址。后面我们会看到软中断中会通过ptype_base找到ip_rcv函数地址,进而将ip包正确地送到ip_rcv()中执行。在ip_rcv中将会通过inet_protos找到tcp或者udp的处理函数,再而把包转发给udp_rcv()或tcp_v4_rcv()函数。
三、接收前的准备工作
3.1 网络子系统初始化
在 Linux 内核启动的过程中,网络子系统的初始化是一项关键任务,它为后续的网络数据接收和处理奠定了基础。这一过程涉及一系列复杂的步骤和众多关键函数的调用。
在内核启动阶段,start_kernel函数作为启动的入口,会有条不紊地调用一系列初始化函数。其中,net_dev_init函数在网络子系统初始化中扮演着核心角色。net_dev_init函数会对每个可能的 CPU 进行初始化操作,为网络数据的接收和处理准备好相关的数据结构。例如,它会初始化每个 CPU 上的softnet_data结构体,该结构体包含了用于存储网络数据包的队列,如input_pkt_queue用于接收来自网络设备的数据包,process_queue则用于存放等待进一步处理的数据包 。通过skb_queue_head_init函数对这些队列进行初始化,确保它们能够正确地存储和管理数据包。
在网络子系统初始化过程中,还需要对软中断进行注册。软中断是一种用于处理可延迟任务的机制,在网络数据处理中起着至关重要的作用。通过open_softirq函数,分别注册了用于网络发送的NET_TX_SOFTIRQ和用于网络接收的NET_RX_SOFTIRQ软中断。以NET_RX_SOFTIRQ为例,它会关联到net_rx_action函数,当网络设备接收到数据包并触发相应的软中断时,net_rx_action函数将被调用,从而启动对接收数据包的后续处理流程。linux内核通过调用subsys_initcall来初始化各个子系统,其中网络子系统的初始化会执行到net_dev_init函数:
首先为每个CPU都申请一个softnet_data数据结构,在这个数据结构里的poll_list是等待驱动程序将其poll函数注册进来,稍后网卡驱动初始化的时候我们可以看到这一过程。
然后 open_softirq 为每一种软中断都注册一个处理函数。NET_TX_SOFTIRQ的处理函数为net_tx_action,NET_RX_SOFTIRQ的为net_rx_action。
open_softirq 会把不同的 action 记录在softirq_vec变量里的。后面ksoftirqd线程收到软中断的时候,也会使用这个变量来找到每一种软中断对应的处理函数。
 图片
图片
3.2 网卡驱动初始化
网卡驱动的初始化是网络数据包能够被正确接收的前提条件,它涉及到驱动的加载与注册,以及为数据接收所做的一系列准备工作。
在 Linux 系统中,大多数网卡通过 PCI 总线与系统相连,内核通过 PCI 子系统对这些设备进行管理。当系统启动时,会遍历 PCI 总线上的设备,并为它们寻找合适的驱动程序。对于网卡驱动而言,首先要使用pci_register_driver函数向内核注册驱动程序。在注册过程中,需要提供一个pci_driver结构体,该结构体包含了驱动的名称、所支持的 PCI 设备 ID 表、探测函数(probe)等重要信息。
以常见的igb网卡驱动为例,igb_driver结构体中定义了驱动的名称为igb_driver_name,并指定了igb_pci_tbl作为所支持的 PCI 设备 ID 表。当内核发现一个 PCI 设备的 ID 与igb_pci_tbl中的某个条目匹配时,就会调用igb_probe探测函数。在igb_probe函数中,会进行一系列的初始化操作,如为网卡分配内存空间、初始化 DMA(直接内存访问)、设置网卡的相关寄存器等。它还会注册net_device结构体,这个结构体代表了网络设备,包含了设备的各种属性和操作函数,如设备的打开、关闭、数据发送和接收等函数。通过这些初始化操作,网卡驱动为后续的数据接收做好了充分准备,确保网卡能够与内核进行有效的通信,将接收到的网络数据包传递给内核进行处理。这里以 FSL 系列网卡为例,其驱动位于:drivers/net/ethernet/freescale/fec_main.c
Linux 以太网驱动会向上层提供 net_device_ops ,方便应用层控制网卡,比如网卡被启动(例如,通过 ifconfig eth0 up)的时候会被调用 fec_enet_open,此外它还包含着网卡发包、设置 mac 地址等回调函数。
此外,网卡驱动实现了 ethtool 所需要的接口,当 ethtool 发起一个系统调用之后,内核会找到对应操作的回调函数。可以看到 ethtool 这个命令之所以能查看网卡收发包统计、能修改网卡自适应模式、能调整RX 队列的数量和大小,是因为 ethtool 命令最终调用到了网卡驱动的相应方法。
3.3 ksoftirqd 内核线程创建
ksoftirqd内核线程在 Linux 网络数据处理中承担着处理软中断的重要职责,其创建过程与系统的启动流程紧密相关。
在系统启动时,start_kernel函数会创建init线程,随后init线程调用do_pre_smp_initcalls函数。在do_pre_smp_initcalls函数中,会调用spawn_ksoftirqd函数来创建ksoftirqd内核线程。spawn_ksoftirqd函数通过两次调用cpu_callback函数,分别使用CPU_UP_PREPARE和CPU_ONLINE参数来完成ksoftirqd线程的创建和唤醒。
当使用CPU_UP_PREPARE参数调用cpu_callback函数时,会通过kthread_create函数创建一个新的内核线程,并将其命名为ksoftirqd/%d,其中%d为 CPU 的编号。创建完成后,将该线程的task_struct指针存储在per_cpu(ksoftirqd, hotcpu)变量中,以便后续对该线程进行管理和调度。接着,使用CPU_ONLINE参数再次调用cpu_callback函数,此时的作用是唤醒刚刚创建的ksoftirqd线程,使其能够开始执行任务。
ksoftirqd线程的主要任务是处理系统中的软中断。当网络设备接收到数据包并触发硬中断后,硬中断处理程序会快速完成一些必要的操作,然后触发相应的软中断。ksoftirqd线程会不断地检查是否有软中断等待处理,一旦发现有软中断,就会调用相应的软中断处理函数,对网络数据包进行进一步的处理,如解析数据包、将其传递给协议栈的上层进行处理等。通过这种方式,ksoftirqd线程有效地分担了硬中断处理的工作量,避免了硬中断处理时间过长而影响系统对其他硬件中断的响应,确保了系统能够高效、稳定地处理网络数据。
四、数据包接收流程
4.1 网卡接收数据
当网络数据包在网络中传输并抵达网卡时,网卡便开始发挥其关键作用。网卡具备专门的硬件电路,能够识别和捕获这些数据包。通过直接内存访问(DMA)技术,网卡得以将接收到的数据包高效地存入内存缓冲区中。
DMA 是一种强大的技术,它允许外部设备(如网卡)直接与内存进行数据传输,而无需 CPU 的频繁干预 。在这个过程中,网卡中的 DMA 控制器会负责管理数据的传输过程,它会在内存中开辟出一块特定的缓冲区,通常被称为 Ring Buffer(环形缓冲区)。Ring Buffer 就像是一个环形的队列,数据包按照顺序依次存入其中。由于其环形的结构,当缓冲区的尾部到达末尾时,下一个数据包会接着存入缓冲区的头部,从而实现了连续的数据存储。
与传统的通过 CPU 进行数据传输的方式相比,DMA 具有显著的优势。传统方式下,CPU 需要亲自参与数据的读取和写入操作,这会占用大量的 CPU 时间和资源,导致 CPU 无法高效地处理其他任务。而采用 DMA 技术,CPU 可以将精力集中在其他重要的任务上,大大提高了系统的整体性能。例如,在进行大规模数据传输时,如果没有 DMA 技术,CPU 可能会被数据传输任务所占据,导致系统响应迟缓,其他应用程序无法正常运行。而有了 DMA 技术,网卡可以在后台默默地将数据传输到内存中,CPU 则可以同时处理用户的其他操作,如运行其他应用程序、处理文件等,极大地提高了系统的并发处理能力。
4.2 硬件中断处理
当网卡成功将数据包存入内存缓冲区后,为了及时通知 CPU 有新的数据到达,网卡会触发一个硬件中断信号 。这个信号就像是一个紧急通知,告诉 CPU 需要立即处理新到达的数据。
CPU 在接收到这个硬件中断信号时,会迅速做出响应。它会暂停当前正在执行的任务,保存当前任务的现场信息,包括寄存器的值、程序计数器的值等,以便在处理完中断后能够恢复到原来的任务执行状态。之后,CPU 会根据中断向量表,找到对应的中断处理函数。中断向量表就像是一个索引表,它记录了每个中断源对应的中断处理函数的入口地址。通过查询中断向量表,CPU 可以快速找到处理网卡中断的函数。
对于网卡的中断处理函数,其主要任务是将接收到的数据从网卡的缓冲区拷贝到内核缓冲区中,并进行一些初步的处理 。它会对数据包进行简单的校验,检查数据包是否完整、是否存在错误等。如果发现数据包存在问题,可能会采取相应的措施,如丢弃该数据包或者发送错误通知。中断处理函数还会设置一些与数据包相关的标志位,以便后续的处理程序能够了解数据包的状态。由于硬件中断处理需要快速响应,以避免数据丢失或其他硬件事件的延迟处理,因此硬件中断处理函数通常只执行一些紧急且耗时较短的操作,而将更复杂的处理工作交给后续的软中断处理。
首先当数据帧从网线到达网卡,网卡在分配给自己的 ringBuffer 中寻找可用的内存位置,找到后 DMA 会把数据拷贝到网卡之前关联的内存里。当 DMA 操作完成以后,网卡会向 CPU 发起一个硬中断,通知 CPU 有数据到达。中断处理函数为:
这里我们看到,list_add_tail修改了CPU变量softnet_data里的poll_list,将驱动napi_struct传过来的poll_list添加了进来。其中softnet_data中的poll_list是一个双向列表,其中的设备都带有输入帧等着被处理。紧接着 __raise_softirq_irqoff 触发了一个软中断 NET_RX_SOFTIRQ。
 图片
图片
注意:当RingBuffer满的时候,新来的数据包将给丢弃。ifconfig查看网卡的时候,可以里面有个overruns,表示因为环形队列满被丢弃的包。如果发现有丢包,可能需要通过ethtool命令来加大环形队列的长度。
4.3 软中断处理
在硬件中断处理完成后,会触发相应的软中断,将数据包的后续处理工作交给软中断机制来完成 。软中断的处理主要由ksoftirqd内核线程负责。
ksoftirqd线程会不断地检查是否有软中断等待处理。当检测到网络接收相关的软中断(NET_RX_SOFTIRQ)被触发时,它会调用net_rx_action函数。net_rx_action函数是软中断处理网络数据包的核心函数,它会从 Ring Buffer 中取出数据包,并调用网卡驱动注册的poll函数。
poll函数的作用是对数据包进行进一步的处理和准备工作 。它会对数据包进行合并、整理等操作。有时,一个完整的数据包可能会被分成多个部分存储在 Ring Buffer 中,poll函数会将这些分散的部分合并成一个完整的数据包。poll函数还会对数据包进行一些过滤和筛选,去除不符合要求的数据包。经过poll函数处理后的数据包,会被传递给内核协议栈的网络层进行后续的处理,从而实现了从硬件层面到软件层面的数据交接,确保数据包能够在系统中继续流转和处理。接下来进入软中断处理函数:
在网络设备子系统初始化中,讲到为 NET_RX_SOFTIRQ 注册了处理函数 net_rx_action。所以 net_rx_action 函数就会被执行到了。
首先获取到当前CPU变量softnet_data,对其poll_list进行遍历, 然后执行到网卡驱动注册到的 poll 函数。对于 FSL 网卡来说,其驱动对应的 poll 函数就是 fec_enet_rx_napi。
 图片
图片
然后进入 GRO 处理,流程如下:
 图片
图片
最终通过函数 netif_receive_skb_list_internal() 进入内核协议栈。
4.4 协议栈逐层处理
⑴网络接口层
当数据包从软中断处理环节传递到内核协议栈的网络接口层时,网络接口层首先会对数据包的合法性进行严格检查 。它会验证数据包的格式是否符合网络接口层协议的规定,例如以太网协议规定了数据帧的特定格式,包括前导码、帧起始定界符、源 MAC 地址、目的 MAC 地址、类型字段、数据字段和帧校验序列(FCS)等。网络接口层会检查这些字段是否完整、正确,FCS 是否匹配,以确保数据包在传输过程中没有出现错误。
网络接口层还会仔细判断数据包所使用的协议类型 。在以太网环境中,类型字段用于标识上层协议,常见的类型值如 0x0800 表示 IP 协议,0x0806 表示 ARP 协议等。通过识别这个类型字段,网络接口层能够确定该数据包应该被传递给哪个上层协议进行进一步处理。如果是 IP 协议的数据包,网络接口层会去掉以太网帧头和帧尾,将剩余的 IP 数据包传递给网络层;如果是 ARP 协议的数据包,则会在网络接口层进行相应的 ARP 处理,如更新 ARP 缓存表等。
⑵网络层
在网络接口层完成处理后,IP 数据包被传递到网络层。网络层的首要任务是对 IP 包进行深入的路由判断 。它会检查 IP 包的目的 IP 地址,然后查询系统的路由表,以确定该数据包应该被发送到哪里。路由表中存储了一系列的路由规则,这些规则根据目的 IP 地址的网络部分来确定数据包的下一跳地址。例如,如果目的 IP 地址属于本地网络,网络层会直接将数据包发送到本地的目标主机;如果目的 IP 地址属于其他网络,网络层会根据路由表将数据包发送到合适的路由器,由路由器继续转发数据包。
网络层还负责将数据包分发给正确的上层协议 。IP 包的首部中有一个协议字段,该字段用于标识上层协议的类型,如 6 表示 TCP 协议,17 表示 UDP 协议等。根据这个协议字段的值,网络层能够确定将数据包传递给传输层的哪个协议模块进行后续处理。当确定上层协议为 TCP 时,网络层会去掉 IP 头,将剩余的 TCP 数据段传递给传输层的 TCP 模块;若上层协议为 UDP,则将 UDP 数据报传递给传输层的 UDP 模块。
⑶传输层
传输层在接收到网络层传递过来的 TCP 数据段或 UDP 数据报后,会依据端口号来准确地将数据送到对应的 Socket 。每个 Socket 都与一个特定的端口号相关联,而端口号则用于区分不同的应用程序或服务。
对于 TCP 协议,传输层会根据 TCP 数据段中的源端口号、目的端口号、源 IP 地址和目的 IP 地址这四元组,在系统中查找与之匹配的 Socket 。这个四元组就像是一个唯一的标识,能够准确地确定一个 TCP 连接。一旦找到对应的 Socket,传输层会将 TCP 数据段中的数据拷贝到该 Socket 的接收缓冲区中,等待应用程序通过 Socket 接口来读取数据。例如,当你在浏览器中访问一个网站时,浏览器会与网站服务器建立一个 TCP 连接,传输层会根据这个连接的四元组信息,将接收到的网页数据准确地送到对应的 Socket 接收缓冲区,供浏览器读取并显示网页内容。
对于 UDP 协议,传输层同样根据 UDP 数据报中的源端口号和目的端口号,查找对应的 Socket 。由于 UDP 是无连接的协议,它不需要像 TCP 那样进行复杂的连接建立和管理过程。一旦找到匹配的 Socket,传输层就会将 UDP 数据报中的数据拷贝到该 Socket 的接收缓冲区中。例如,在进行实时视频聊天时,视频数据通常通过 UDP 协议传输,传输层会快速地将接收到的 UDP 视频数据报送到对应的 Socket 接收缓冲区,以便视频播放程序能够及时读取并显示视频画面。
五、数据包到达应用层
经过一系列复杂的处理,数据包终于抵达了应用层,这是数据旅程的最后一站,也是数据能够被应用程序实际使用的关键环节。应用程序通过 Socket 接口来读取这些数据,从而实现各种网络功能。
在 Linux 系统中,Socket 是应用程序与网络协议栈进行交互的重要接口。它为应用程序提供了一种统一的方式来发送和接收网络数据,隐藏了底层网络协议的复杂性。当数据包到达传输层并被存入对应的 Socket 接收缓冲区后,应用程序便可以通过系统调用,如recv或recvfrom函数,从 Socket 缓冲区中读取数据。
以一个简单的网络聊天程序为例,当用户发送消息时,消息会被封装成数据包,经过网络协议栈的层层处理发送出去;而当接收方收到数据包时,数据包会沿着协议栈层层向上传递,最终到达应用层。接收方的聊天程序通过 Socket 接口调用recv函数,从 Socket 接收缓冲区中读取数据,将其解析为用户能够理解的消息内容,并显示在聊天窗口中。
在实际应用中,应用程序可能会根据自身的需求,对读取到的数据进行进一步的处理和解析。例如,对于一个 HTTP 服务器应用程序,它接收到的数据包可能包含了 HTTP 请求信息,服务器会解析这些请求,提取出请求的资源路径、请求方法等信息,然后根据这些信息返回相应的 HTTP 响应。