deepseek开源Flash-MLA,业内纷纷表示:
- “这是加速AGI进程的里程碑技术”
- “deepseek才是真正的open AI”
今天简单聊聊:
- 吃瓜:FLASH-MLA是干嘛的?
- 技术:MLA是个啥?
- 普通人有什么用:对写提示词有什么启示?

1. Flash-MLA是干嘛的?
GPU高速解码器,可以理解为这是为高性能显卡定制的“AI加速工具”。
加速到什么程度?
- 处理速度达到3000GB/s;
- 算力达到580万亿次/s;
对整个行业有什么影响?
- 训练/计算都更快:AGI进程大大加速;
- 更省成本:大模型不再是大公司的专利,更多创新公司也玩得起AI了;
- 开源免费,技术普惠:开发者福音,更多被算力卡脖子的应用将更快释放,几天就能训练与部署垂直领域AI;
2. MLA是个啥?
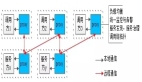
Multi-head Latent Attention,多头潜在注意力机制,是对多头注意力机制的一种改进。
那什么是多头注意力机制?
Multi-head Attention(MHA),这是Transformer模型的核心组件,它通过多个独立的注意力权重矩阵,对输入数据进行并行分析,最终再融合输出,以提高计算效率与输出质量。
简言之:并行分析,最后整合,提质提效。
打个通俗的比喻。
用户输入:设计一个电商高可用架构。
普通注意力机制 -> 安排一个架构师,通过训练好的注意力矩阵,对系统进行设计。
多头注意力机制 -> 安排一个系统架构师,一个业务架构师,一个运维专家,一个安全专家,一个DBA…. 分别通过训练好的注意力矩阵,并行设计,最终整合设计方案。
既能缩短设计时间,又能提升设计质量。
MLA对MHA是怎么改进的?
- 引入潜在向量(Latent Vector),矩阵降维,压缩KV缓存,压缩率能达到90%+;
- 限制注意力范围,聚焦局部窗口与关键片段,降低长提示词计算复杂度;
- …
画外音:相关文档还在研究,截止发文,还没有全部搞懂。
3. 对我们普通人写提示词有什么启示?
提示词技巧一:显示并行步骤拆分。
bad case:请系统性介绍MLA。
better case,请系统性介绍MLA:
- 介绍MLA概念,用通俗的语言表达;
- 介绍MHA与MLA的关联与异同;
- 举几个MLA例子说明;
- 补充MLA关联知识点;
原理:MHA可以多注意力并行处理,通过提示词显示派发并行任务可以充分发挥其潜力。
提示词技巧二:标记关键变量信息。
上述提示词还可以进一步优化:
请系统性介绍{$input}:
{$input}=MLA
- 介绍{$input}概念,用通俗的语言表达;
- 介绍MHA与{$input}的关联与异同;
- 举几个{$input}例子说明;
- 补充{$input}关联知识点;
原理:MLA对潜在的变量符号敏感,它能帮助模型捕捉提示词之间的层次与隐藏关系,减少重复分析与计算。
提示词技巧三:分段输入。
bad case:请分析这篇关于MLA的文章:
- #正文#...
- 并进行总结。
better case,请分析这篇关于MLA的文章:
- #正文第一部分# …
- #正文第二部分# …
- #正文第三部分# …
- 并进行总结。
原理:MLA擅长处理局部信息,分段输入可减少跨段冗余计算,提高效率。
4. 稍作总结
- Flash-MLA是显卡加速工具,它的开源使得计算更快更便宜,实现了技术普惠;
- MLA是deepseek的核心技术(之一),它是对MHA的优化;
- MHA的关键是:并行分析,最后整合,提质提效;
- 提示词层面:拆分并行步骤,标记关键变量,分段输入等充分发挥MLA的潜能;
一切的一切,提示词只有适配了AI的认知模式,才能最高效的发挥最大的作用。
知其然,知其所以然。
思路比结论更重要。