一、背景介绍
随着互联网技术的飞速发展,微服务架构逐渐成为企业级应用开发的主流选择。在微服务架构中,各个服务独立部署、独立运行,通过网络进行通信和协作,以实现复杂的业务功能。然而,这种架构模式也带来了一系列挑战,其中之一就是服务之间的调用关系复杂,一旦某个服务出现故障,可能会引发连锁反应,导致整个系统不可用,这就是著名的 “雪崩效应”。
为了应对这一问题,熔断机制应运而生,而 Spring Cloud 网关作为微服务架构中的重要组件,其熔断机制的实现和应用对于保障系统的稳定性具有至关重要的作用。

二、熔断机制的技术原理
1. 熔断机制概述
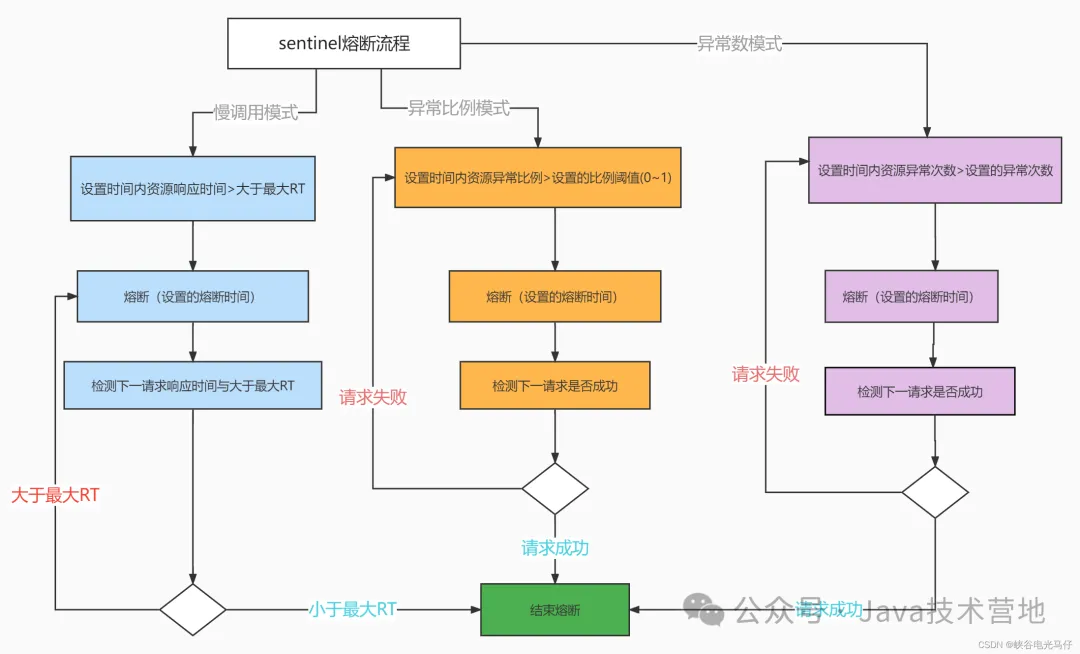
熔断机制是一种在微服务架构中用于保护系统稳定性的重要技术手段。其核心思想是,当某个服务出现故障或者响应延迟过高时,通过熔断器快速切断对该服务的请求,避免故障蔓延和系统雪崩。熔断器通常有三种状态:闭合、断开和半开。
- 闭合状态 :系统正常运行时,熔断器处于闭合状态,请求可以正常通过,调用下游服务。此时,熔断器会统计请求的成功率、响应时间等指标,为后续的状态转换提供依据。
- 断开状态 :当在一定时间内,请求的成功率低于设定的阈值,或者响应时间超过设定的阈值时,熔断器会切换到断开状态。此时,请求将不再被发送到下游服务,而是直接返回错误响应,避免下游服务因过多请求而崩溃。
- 半开状态 :经过一段时间的断开状态后,熔断器会进入半开状态,允许少量请求通过,以测试下游服务是否恢复正常。如果这些请求成功,则认为下游服务已恢复,熔断器切换回闭合状态;如果请求仍然失败,则再次切换到断开状态。
2. Spring Cloud 网关中的熔断器实现
在 Spring Cloud 网关中,常用的熔断器实现是 Resilience4j。Resilience4j 是一个轻量级的故障处理库,它提供了断路器、限流器、重试、熔断器等组件,用于构建弹性微服务架构。Resilience4j 的熔断器通过统计请求的成功率、响应时间等指标,自动切换熔断器的状态,实现对请求的快速失败和流量控制。
Resilience4j 的熔断器主要通过以下参数来控制熔断行为:
- failureRateThreshold :失败率阈值,当请求的失败率超过该阈值时,熔断器会切换到断开状态。默认值为 50%。
- minimumNumberOfCalls :最小请求数,只有当请求次数达到该值时,才会开始统计失败率。默认值为 20。
- waitDurationInOpenState :断开状态的持续时间,当熔断器切换到断开状态后,会等待该时长,然后进入半开状态。默认值为 10 秒。
- permittedNumberOfCallsInHalfOpenState :半开状态允许的请求数,用于测试下游服务是否恢复正常。默认值为 5。
通过合理配置这些参数,可以实现对熔断行为的精确控制,以适应不同的业务场景和需求。
3. 熔断机制的优势
在 Spring Cloud 网关中应用熔断机制,具有以下优势:
- 防止雪崩效应 :当某个服务出现故障时,熔断器会快速切断对该服务的请求,避免故障蔓延到其他服务,从而防止整个系统发生雪崩。
- 提高系统可用性 :通过熔断机制,可以快速失败请求,避免请求长时间等待,提高系统的响应速度和可用性。
- 保护下游服务 :熔断器可以限制对下游服务的请求流量,避免下游服务因过多请求而崩溃,从而保护下游服务的稳定性。
- 自动恢复 :熔断器会自动检测下游服务的状态,当服务恢复正常后,会自动切换回闭合状态,恢复对下游服务的请求。
三、Spring Cloud 网关熔断机制的实践应用
1. 实践场景与挑战
在实际的微服务项目中,经常会遇到因某个服务故障而导致整个系统不可用的情况。例如,一个电商系统中,用户下单服务依赖于库存服务和支付服务。如果库存服务出现故障,响应时间过长或返回错误,可能会导致用户下单失败,影响用户体验和业务运营。如果不对这种情况进行处理,可能会引发连锁反应,导致整个系统的雪崩。
在这种情况下,应用 Spring Cloud 网关的熔断机制可以有效应对。通过配置熔断器,当库存服务的失败率超出设定阈值或响应时间过长时,熔断器会切换到断开状态,网关会停止向库存服务发送请求,而是直接返回错误响应或引导用户进行其他操作。这样可以防止故障蔓延到支付服务等其他服务,保障系统的整体可用性。
2. 熔断器的配置与使用
在 Spring Cloud 网关中,可以通过配置文件和注解的方式轻松启用和配置熔断器。以下是使用 Resilience4j 实现熔断器的示例配置:
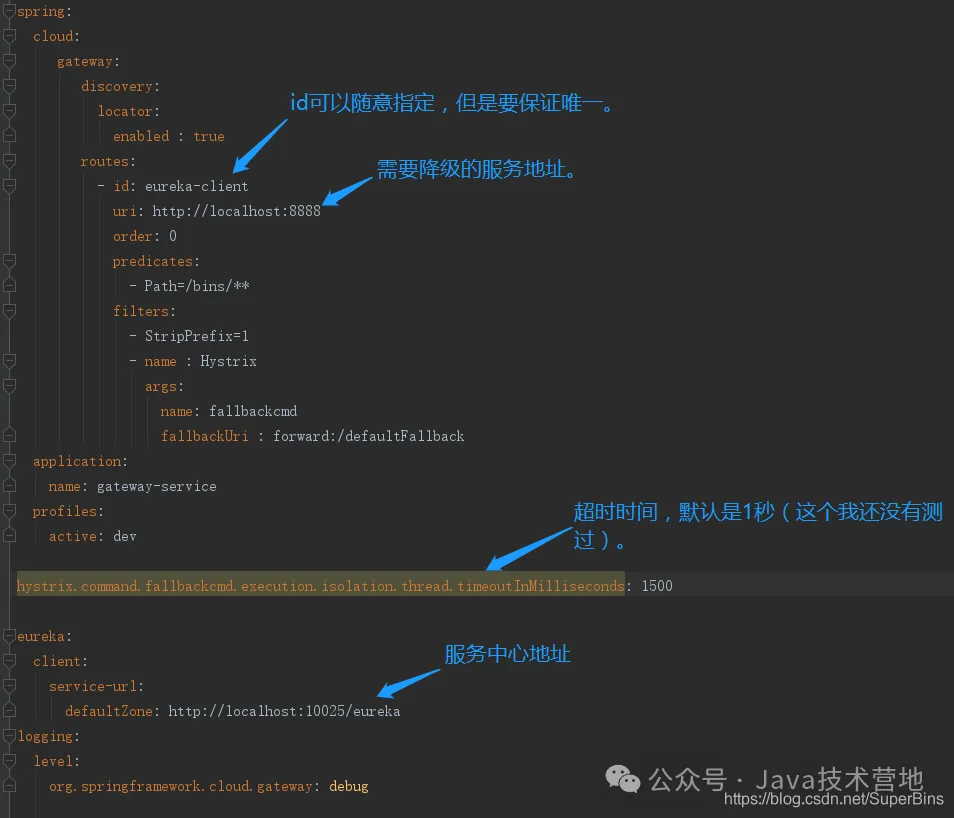
在上述配置中,我们为 inventory_service 路由添加了一个熔断器过滤器,并通过 CircuitBreaker 过滤器的参数指定了熔断器的实例名称 inventoryBreaker 和回退 URI forward:/inventoryFallback。当熔断器切换到断开状态时,请求将自动转发到回退 URI,我们可以在这个 URI 对应的处理逻辑中返回友好的错误信息或引导用户进行其他操作,例如显示库存不足或稍后再试等提示。
以下是一个简单的回退接口示例:
3. 实践案例分析
在某实际项目中,我们应用了上述熔断机制来应对库存服务的故障。通过配置熔断器,当库存服务的失败率达到 50% 时,熔断器会切换到断开状态,并保持 10 秒的断开时间。在这段时间内,所有对库存服务的请求都会被网关直接返回错误响应或引导用户进行其他操作。经过 10 秒后,熔断器进入半开状态,允许少量请求通过。如果请求成功,则恢复正常的请求路由;如果请求仍然失败,则再次切换到断开状态,保护下游服务。通过这种机制,系统在库存服务出现故障时仍然能够保持较高的可用性,避免了雪崩效应的发生。
四、熔断机制的优化与扩展
1. 动态调整熔断参数
在实际应用中,系统的负载和业务需求是不断变化的,因此熔断机制的参数也需要根据实际情况进行动态调整。Spring Cloud 网关支持通过配置中心(如 Spring Cloud Config 或 Apollo)实现熔断参数的动态配置。例如,可以根据系统的实时负载情况,动态调整熔断器的失败率阈值、最小请求数、断开状态持续时间等参数。当系统负载较低时,可以适当提高失败率阈值,减少误报;当系统负载较高时,可以适当降低失败率阈值,加强对请求的保护。
此外,还可以通过监控系统实时收集熔断器的运行数据,如请求成功率、响应时间、断路器状态等,根据这些数据自动调整熔断参数。例如,当请求成功率持续下降时,可以自动降低失败率阈值,提前触发熔断器的断开状态,保护系统免受进一步的损害。
2. 结合监控系统与日志分析
为了更好地管理和优化熔断机制,需要将熔断器与监控系统和日志分析工具相结合。通过监控系统,可以实时查看熔断器的状态、请求成功率、响应时间等关键指标,及时发现潜在的问题。例如,当熔断器频繁切换到断开状态时,可能意味着下游服务的稳定性存在问题,需要进一步排查和优化。
同时,日志分析工具可以帮助开发人员深入了解熔断器的行为和请求失败的原因。通过分析熔断器的日志,可以获取请求的详细信息、失败原因、熔断器的状态变化等,为问题的诊断和解决提供有力的支持。例如,如果发现某个服务的请求失败率较高,可以通过日志分析确定是下游服务本身的故障,还是网络问题或其他因素导致的。
3. 根据业务需求定制熔断策略
不同的业务场景和系统特性对熔断机制的要求是不同的,因此需要根据业务需求定制熔断策略。例如,对于一些对外提供服务的接口,可能需要更严格的熔断策略,以确保服务的高可用性和用户体验。而对于一些内部后台系统的接口,可能可以采用相对宽松的熔断策略,在保证系统稳定性的同时,兼顾资源的利用率。
此外,还可以根据业务的重要性和优先级,为不同的请求设置不同的熔断规则。例如,对于核心业务的请求,可以配置更严格的熔断条件和回退策略,确保核心业务的稳定运行;而对于非核心业务的请求,可以适当放宽熔断条件,以节省资源。
通过根据业务需求定制熔断策略,可以更好地满足不同场景下的系统需求,提高系统的整体稳定性和可靠性。