













本文来自南京大学计算机学院软件研究所徐经纬DeepEngine团队,作者为徐经纬准聘助理教授、硕士生赖俊宇和黄云鹏。目前该论文已被 ICLR2025 接收。
在大语言模型领域中,预训练 + 微调范式已经成为了部署各类下游应用的重要基础。在该框架下,通过使用搭低秩自适应(LoRA)方法的大模型参数高效微调(PEFT)技术,已经产生了大量针对特定任务、可重用的 LoRA 适配器。但使用 LoRA 适配器的微调方法需要明确的意图选择,因此在搭载多个 LoRA 适配器的单一大语言模型上,自主任务感知和切换方面一直存在挑战。
为此,团队提出了一个可扩展、高效的多任务嵌入架构 MeteoRA。该框架通过全模式混合专家模型(MoE)将多个特定任务的 LoRA 适配器重用到了基础模型上。该框架还包括了一个新颖的混合专家模型前向加速策略,以改善传统实现的效率瓶颈。配备了 MeteoRA 框架的大语言模型在处理复合问题时取得了卓越的性能,可以在一次推理中高效地解决十个按次序输入的不同问题,证明了该模型具备适配器及时切换的强化能力。

- 论文标题:MeteoRA: Multiple-tasks Embedded LoRA for Large Language Models
- 论文地址:https://arxiv.org/abs/2405.13053
- 项目主页:https://github.com/NJUDeepEngine/meteora
该工作的创新点主要有以下部分:
- 可扩展的 LoRA 集成框架:MeteoRA 框架能够整合现有的 LoRA 适配器,并提供了大语言模型自主按需选择和切换不同 LoRA 的能力。
- 混合专家模型的前向加速策略:揭示了混合专家模型的效率问题,使用新的 GPU 内核操作实现了前向传播加速策略,在保持内存开销不变的同时实现了平均约 4 倍的加速。
- 卓越的模型性能:评估表明使用 MeteoRA 框架的大语言模型在复合任务中表现出了卓越的性能,因而增强了大语言模型在结合使用现成 LoRA 适配器上的实际效果。
相关工作
低秩适应 (LoRA):低秩适应 [1] 提供了一种策略来减少下游任务微调所需要的可训练参数规模。对于一个基于 Transformer 的大语言模型,LoRA 会向每一个基本线性层的权重矩阵注入两个可训练的低秩矩阵,并用两个低秩矩阵的相乘来代表模型在原来权重矩阵上的微调。LoRA 可以用于 Transformer 中自注意力模块和多层感知机模块的 7 种权重矩阵,有效缩减了微调权重的规模。应用低秩适应技术可以在不改变预训练模型参数的前提下,使用自回归语言模型的优化目标来训练 LoRA 适配器的参数。
多任务 LoRA 融合:LoRA 适配器通常被微调来完成特定的下游任务。为了增强大语言模型处理多种任务的能力,主流的做法有两种。一种方法是从多种任务中合并数据集,在此基础上训练单一的 LoRA 适配器,但相关研究已经证明同时学习不同领域的知识很困难。[2] 另一种方法是直接将多种 LoRA 适配器整合到一个模型中,如 PEFT [3]、S-LoRA [4]。但是流行的框架必须要明确指定注入的 LoRA 适配器,因此模型缺乏自主选择和及时切换 LoRA 的能力。现有的工作如 LoRAHub [5] 可以在不人为指定的情况下完成 LoRA 适配器的选择,但仍旧需要针对每一个下游任务进行少量的学习。
混合专家模型(MoE):混合专家模型是一种通过组合多个模型的预测结果来提高效率和性能的机器学习范式,该范式通过门控网络将输入动态分配给最相关的 “专家” 来获得预测结果。[6] 该模型利用来自不同专家的特定知识来改善在多样、复杂的问题上的总体表现,已有研究证明 MoE 在大规模神经网络上的有效性 [7]。对于每个输入,MoE 只会激活一部分专家,从而在不损害模型规模的基础上显著提高计算效率。该方法已被证实在扩展基于 Transformer 的应用架构上十分有效,如 Mixtral [8]。
方法描述
该工作提出了一个可扩展、高效的多任务嵌入架构 MeteoRA,它能够直接使用开源社区中或面向特定下游任务微调好的 LoRA 适配器,并依据输入自主选择、及时切换合适的 LoRA 适配器。如图 1 所示,MeteoRA 模块可以被集成到注意力模块和多层感知机模块的所有基本线性层中,每一个模块都包括了一系列低秩矩阵。通过 MoE 前向加速策略,大语言模型能够高效解决广泛的问题。

图 1:集成了 MeteoRA 模块实现 MoE 架构的大语言模型框架
图 2 展示了 MeteoRA 模块的内部结构。MeteoRA 模块中嵌入了多个 LoRA 适配器,并通过一个门控网络来实现 MoE 架构。该门控网络会依据输入选择 top-k 个 LoRA 适配器,并将它们组合作为微调权重进行前向传播。通过这种架构,门控网络会执行路由策略,从而根据输入选取合适的 LoRA 适配器。每一个 MeteoRA 模块都包含一个独立的门控网络,不同门控网络依据它们的输入独立决策,并在全部解码器模块的前向传播过程中动态选取不同 LoRA 适配器。
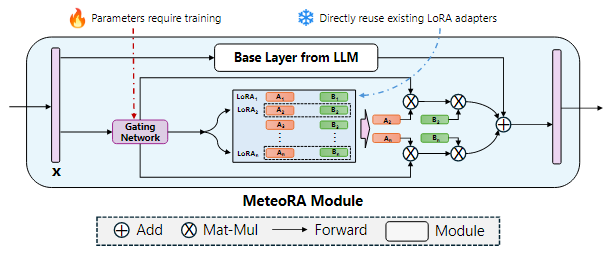
图 2:应用 MoE 模型集成 LoRA 嵌入的 MeteoRA 模块的架构
MeteoRA 模块的训练遵循自回归语言建模任务下的模型微调准则,训练中需要保持基本的大语言模型权重和预训练的 LoRA 适配器参数不变。由于 MeteoRA 模块支持选择权重最高的若干个 LoRA 适配器,团队引入了一种将自回归语言建模损失和所有门控网络损失组合起来的联合优化方案。该优化函数综合了自回归模型中的预测损失和 MeteoRA 模块中 LoRA 分类的交叉熵损失,实现门控网络的训练。
MeteoRA 模块的核心组件是整合了多个 LoRA 适配器的 MoE 架构。首先,团队将 LoRA 整合成在 HBM 上连续分配的张量。对于每个批次的输入序列中的每个标记,由于该模块需要利用门控网络找到 LoRA 适配器的编号索引集合,MeteoRA 模块几乎不可能与单独的 LoRA 模块保持相同的效率。基于原始循环(loop-original)的简单实现 [8] 采用 for-loop 遍历 LoRA 适配器,在每次遍历中对该适配器的候选集合应用 LoRA 前向传递。该方法简单地将所有批次的所有标记拆成 LoRA 数量个集合,并且使得每个集合按顺序传递。然而,考虑到输入标记相互独立的性质,这种方法无法充分利用并行化 GEMM 算子 [9] 加速,尤其是当某些 LoRA 适配器仅被少数标记选择,或是待推理标记小于 LoRA 数量时,实验中可能花费最多 10 倍的运行时间。
该工作采用了前向传播加速策略 bmm-torch,直接索引全部批次标记的 top-k 适配器,这会利用到两次 bmm 计算。相比于原始的循环方法,bmm-torch 基于 PyTorch 提供的 bmm 操作符 [10] 并行化所有批次标记的 top-k 个适配器,实现了约 4 倍的加速。在实验中该策略仅比它的上限单 LoRA 模块慢 2.5 倍。由于 PyTorch 的索引约束(indexing constraints)[11],bmm-torch 需要分配更大的内存执行批处理,当批次或者输入长度过大时 bmm-torch 的大内存开销可能成为瓶颈。为此,该工作使用了 Triton [12] 开发了自定义 GPU 内核算子,不仅保持了 bmm-torch 约 80% 的运算效率,而且还保持了原始循环级别的低内存开销。
实验结果
该工作在独立任务和复合任务上,对所提出的架构和设计进行了广泛的实验验证。实验使用了两种知名的大语言模型 LlaMA2-13B 和 LlaMA3-8B,图 3 显示了集成 28 项任务的 MeteoRA 模块与单 LoRA、参考模型 PEFT 在各项独立任务上的预测表现雷达图。评估结果表明,无论使用哪种大语言模型,MeteoRA 模型都具备与 PEFT 相近的性能,而 MeteoRA 不需要显式地激活特定的 LoRA。表 1 展示了所有方法在各项任务上的平均分数。
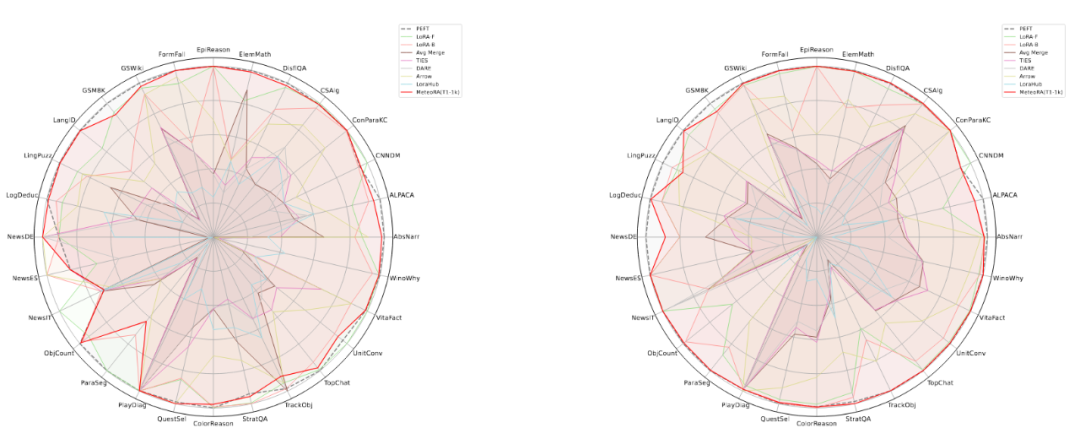
图 3:MeteoRA 模型在 28 项选定任务上的评估表现
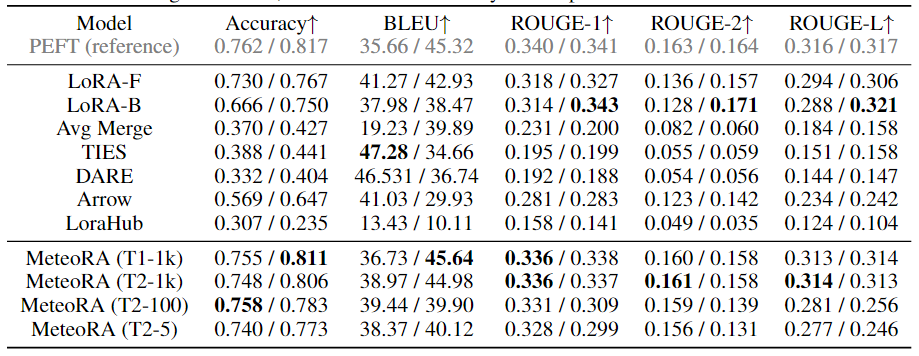
表 1:各模型在 28 项选定任务上的平均表现
为了验证该模型按顺序解决复合问题的能力,该工作通过串行连接独立的任务来构建 3 个数据集,分别整合了 3、5、10 项任务,期望模型能够按次序解决同一序列中输入的不同类别问题。实验结果如表 2 所示,可见随着复合任务数的提升,MeteoRA 模块几乎全面优于参考 LoRA-B 模型。
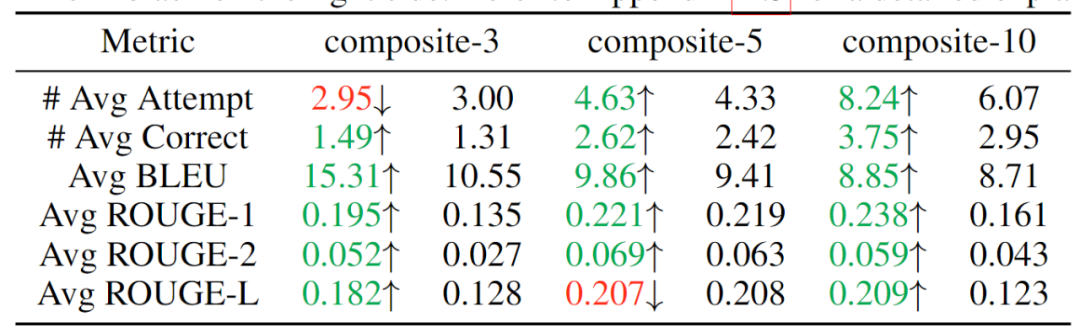
表 2:复合任务的评估结果,左侧为 MeteoRA 模块,右侧为 LoRA-B
为了更进一步验证门控网络在 MeteoRA 模块中的功能,该工作展示了在复合任务推理过程中采用 top-2 策略的 LoRA 选择模式。在两个相邻任务的连接处,门控网络正确执行了 LoRA 的切换操作。

图 4:在 3 项任务复合中 LoRA 选取情况的例子
为了验证采用自定义 GPU 算子的前向传播设计的运算效率,该工作在 28 项任务上截取了部分样本,将新的前向传播策略与其上限和原始实现对比。评估结果如图 5 所示,展现了新的加速策略卓越的性能。

图 5:四种不同的前向传播策略在 28 项任务上的整体运行时间





























