本文由纽约州立大学布法罗分校的田运杰,David Doermann和中国科学院大学的叶齐祥合作完成。田运杰是布法罗大学博士后,David Doermann是布法罗大学教授、IEEE Fellow, 叶齐祥是中国科学院大学教授。三位作者长期从事计算机视觉、机器感知等方向的研究。
YOLO 系列模型的结构创新一直围绕 CNN 展开,而让 transformer 具有统治优势的 attention 机制一直不是 YOLO 系列网络结构改进的重点。这主要的原因是 attention 机制的速度无法满足 YOLO 实时性的要求。本周三放出的 YOLOv12 着力改变这一现状并取得具有优势的性能。

- 论文标题:YOLOv12: Attention-Centric Real-Time Object Detectors
- 论文地址:https://arxiv.org/pdf/2502.12524
- 代码地址:https://github.com/sunsmarterjie/yolov12
介绍
造成 attention(注意力机制)不能作为核心模块用于 yolo 框架的主要原因在于其本身的低效性,这主要源于两个因素:(1)attention 的计算复杂度呈二次增长;(2)attention 的内存访问操作低效(后者是 FlashAttention 主要解决的问题)。在相同的计算预算下,基于 CNN 的架构比基于 attention 的架构快约 2-3 倍,这极大限制了 attention 在 YOLO 系统中的应用,由于 YOLO 体系高度依赖高推理速度。
首先,作者提出了一种简单而高效的区域注意力模块(area attention, A2),该模块在保持大感受野的同时,以最简单直接的方式降低了 attention 的计算复杂度,从而提升了计算速度。
其次,作者引入了残差高效层聚合网络(R-ELAN),以解决 attention(主要是大规模模型)带来的优化难题。
R-ELAN 在原始的基础上进行了两项改进:1)block 级残差设计,结合缩放技术以优化梯度流动;2)重新设计的特征聚合方法,以提升模型的优化效率。
最后,作者针对 YOLO 体系对 attention 进行了一系列架构改进,优化了传统的 attention 主导架构,包括:1)引入 FlashAttention 以解决注意力机制的显存访问问题;2)移除位置编码等设计,使模型更加高效简洁;3)调整 MLP ratio(从 4 降至 1.2),以平衡注意力机制和前馈网络的计算开销,从而提升整体性能;4)减少堆叠块的深度,以简化优化过程等。
Area Attention

首先介绍 area attention 机制,其目的在于降低传统 attention 的计算代价,同时克服线性注意力和局部注意力在全局依赖性、稳定性及感受野方面的局限性。为此,作者提出了一种简单高效的区域注意力(A2)模块。
不同于局部注意力的显式窗口划分,A2 采用最简单的方式将特征图划分为纵向或横向的区域(每个区域大小为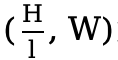 或
或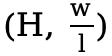 ,这仅需简单的 reshape 操作,避免了额外的复杂计算带来的开销,从而提升计算效率。
,这仅需简单的 reshape 操作,避免了额外的复杂计算带来的开销,从而提升计算效率。
在实验中,作者将默认分割数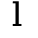 设为 4,使感受野缩小至原来的
设为 4,使感受野缩小至原来的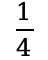 ,仍能覆盖足够的信息范围。在计算复杂度方面,A2 将注意力机制的计算量从
,仍能覆盖足够的信息范围。在计算复杂度方面,A2 将注意力机制的计算量从 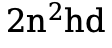 降低至
降低至 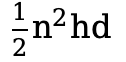 。尽管仍保持二次复杂度,但在 token 数量 n 不是特别大的情况下(如 YOLO:640x640),此优化方案在实际应用中仍足够高效,满足了实时推理的需求。最终,实验表明,A2 仅对性能产生轻微影响,但显著提升了计算速度,为 YOLO 等对速度要求极高的任务提供了一种更优的注意力机制替代方案。
。尽管仍保持二次复杂度,但在 token 数量 n 不是特别大的情况下(如 YOLO:640x640),此优化方案在实际应用中仍足够高效,满足了实时推理的需求。最终,实验表明,A2 仅对性能产生轻微影响,但显著提升了计算速度,为 YOLO 等对速度要求极高的任务提供了一种更优的注意力机制替代方案。
R-ELAN
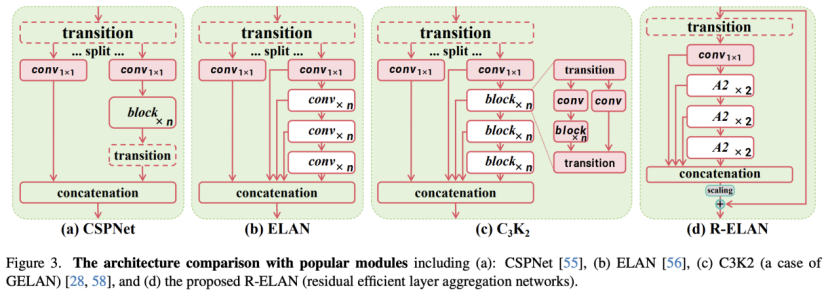
R-ELAN 的主要动机是优化 ELAN 结构,以提升特征聚合效率并解决其带来的优化不稳定性问题,尤其是在引入注意力机制后,参数量较大的模型(如 YOLOv12-L 和 YOLOv12-X)容易发生梯度阻塞或收敛困难。为此,作者提出了残差高效层聚合网络(R-ELAN)。
与原始 ELAN 不同,R-ELAN 在整个 block 内引入从输入到输出的残差连接,并结合缩放因子(默认 0.01),以稳定训练并优化梯度流动。
此外,作者重新设计了特征聚合方式,使其采用瓶颈结构(如上图所示),通过调整通道维度并简化计算流程,以减少计算成本和显存占用,同时保持高效的特征融合能力。最终,R-ELAN 显著提升了模型的优化稳定性和计算效率,使 YOLOv12 的大规模模型能够更好地收敛,并在保证性能的同时提升推理速度。
结构改进
另外,作者还提出一些优化技术,使注意力机制更适应实时目标检测任务,同时降低计算开销并提升优化稳定性。
首先,作者保留了 YOLO 主干网络的分层设计,不同于很多基于 attention 的架构采用的平铺结构的视觉 Transformer。
此外,作者减少了主干网络(Backbone)最后阶段的堆叠的 block 数量,仅保留单个 R-ELAN block,以减少计算量并优化训练收敛性。主干网络的前两阶段继承自 YOLOv11,未使用 R-ELAN,以保持轻量级设计。
同时,作者对基础注意力机制进行了一系列优化,包括:调整 MLP ratio(从 4 降至 1.2 或 2)以更合理地分配计算资源,用 Conv2d+BN 替换 Linear+LN 以充分利用卷积算子的计算效率,移除位置编码并引入 7x7 可分离卷积(Position Perceiver) 以帮助区域注意力感知位置信息。
最终,这些改进提升了模型的优化稳定性和计算效率,使其更适用于 YOLO 系统,同时保持具有竞争力的性能。
实验结果
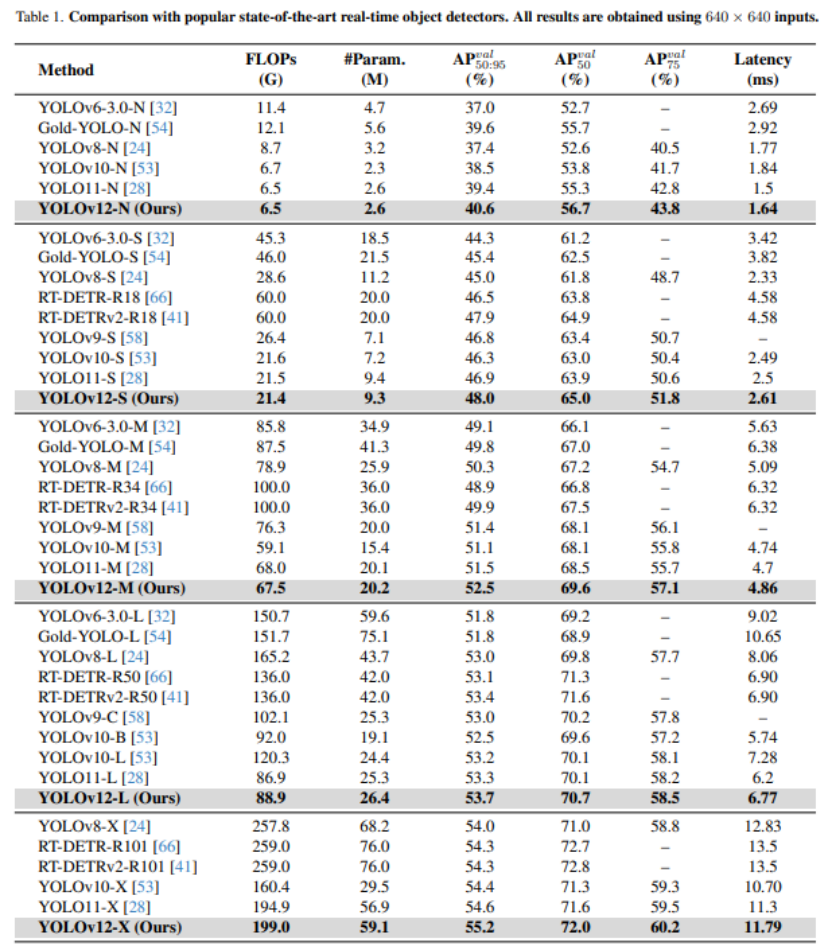
YOLOv12 在 COCO 上取得的效果如下表所示:
- N-scale 模型:YOLOv12-N 比 YOLOv6-3.0-N、YOLOv8-N、YOLOv10-N 和 YOLOv11-N 分别提升 3.6%、3.3%、2.1%、1.2%,同时计算量和参数规模相近或更少,推理速度达到具有竞争力的 1.64 ms / 图像。
- S-scale 模型:YOLOv12-S 在 21.4G FLOPs 和 9.3M 参数的情况下,实现 48.0% mAP,比 YOLOv8-S、YOLOv9-S、YOLOv10-S 和 YOLOv11-S 分别提升 3.0%、1.2%、1.7%、1.1%,计算量相近或更少,并且在推理速度、计算开销和参数量方面明显优于 RT-DETR-R18 / RT-DETRv2-R18。
- M-scale 模型:YOLOv12-M 在 67.5G FLOPs 和 20.2M 参数的情况下,实现 52.5 mAP,推理速度 4.86 ms / 图像,在各项指标上均优于 Gold-YOLO-M、YOLOv8-M、YOLOv9-M、YOLOv10-M、YOLOv11-M 以及 RT-DETR-R34 / RT-DETRv2-R34。
- L-scale 模型:YOLOv12-L 相较于 YOLOv10-L,减少了 31.4G FLOPs 的计算量,同时 mAP 仍优于 YOLOv11-L 达 0.4%,计算量和参数量相近。此外,YOLOv12-L 在推理速度、FLOPs(减少 34.6%)和参数量(减少 37.1%)方面均优于 RT-DETR-R50 / RT-DETRv2-R50。
- X-scale 模型:YOLOv12-X 比 YOLOv10-X 和 YOLOv11-X 分别提升 0.8% 和 0.6%,计算量和参数量相近,推理速度基本持平。同时,相比 RT-DETR-R101 / RT-DETRv2-R101,YOLOv12-X 计算量减少 23.4%,参数量减少 22.2%,且推理速度更快。
可视化分析

参数量 / CPU 速度 - 精度的 Trade-offs 比较:YOLOv12 在参数量和 CPU 推理速度方面上均实现了突破。如上图所示,实验结果显示,YOLOv12 在准确率 - 参数量平衡方面优于现有方法,甚至超越了参数量更少的 YOLOv10,证明了其高效性。此外,在 CPU(Intel Core i7-10700K @ 3.80GHz)上的推理速度测试中,YOLOv12 在不同 YOLO 版本中展现出最佳的计算效率。

YOLOv12 热力图分析:上图展示了 YOLOv12 与当前最先进的 YOLOv10 和 YOLOv11 的热力图对比。这些热力图来自 X-scale 模型主干网络的第三阶段,显示了模型激活的区域,从而反映其目标感知能力。结果表明,相较于 YOLOv10 和 YOLOv11,YOLOv12 能够生成更清晰的目标轮廓和更精确的前景激活,说明其目标感知能力得到了提升。这一改进主要归因于区域注意力机制(Area Attention),该机制相比卷积网络具有更大的感受野,因此在捕捉全局上下文信息方面更具优势,从而实现了更精准的前景激活。作者认为,这一特性使 YOLOv12 在检测性能上占据优势。
最后,我们期待 YOLO 社区能继续提出更强大的检测器,为实时目标检测任务提供更多选择。