译者 | 崔皓
审校 | 重楼
随着机器学习模型的复杂性和规模不断增长,任何企业或者组织在部署、扩展模型上都面临着巨大的挑战。迫在眉睫的挑战是如何在内存限制与模型规模之间取得平衡,并保持高性能和成本效益。本文探讨了一种创新的架构解决方案,通过将共享神经编码器与专门的预测头结合的混合方法来应对这些挑战。

挑战:ML 模型部署中的内存限制
传统机器学习模型的部署通常需要将完整模型加载到内存中,以供用例或客户应用程序使用。例如,在自然语言理解(NLU)应用中使用基于 BERT 的模型,每个模型通常消耗大约 210-450MB 的内存。在为众多客户提供服务时,这会面临内存容量不足需要扩展的挑战。拥有 72GB CPU 内存的经典服务器只能支持大约 100 个模型,如此这般就会为服务能力设定上限。
一种新颖的解决方案:解耦架构
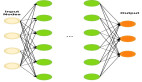
为了解决模型服务量增大而内存不足的问题,我们采用了解耦架构,将模型分为两个关键组件。第一个是共享神经编码器(SNE),一个预训练的神经网络组件,处理输入数据的基本编码。在实践应用过程中,基于 BERT 架构的这个编码器生成上下文嵌入 - 对于输入文本中的每个标记是 768 维向量。第二个组件是任务特定的预测头(TSPH),它是用来嵌入特定预测的专业化组件。这种架构允许多个客户应用相同的共享编码器,同时通过各自的专业化组件保持其独特的预测能力。
关键组件及其相互作用
共享神经编码器
共享神经编码器充分利用了预训练模型,该预训练模型在大型通用数据集上进行过训练。实现过程中,编码器组件需要大约 227 MB 的非量化形式,但通过 INT8 量化,可以将其减少到约 58 MB。在处理文本时,它处理长达 250 个令牌的序列,生成高维上下文嵌入。对于典型的包含 15 个令牌的话语,编码器生成尺寸为 15x768 的输出张量,对嵌入需要约 45 KB 的内存。
任务特定的预测头
任务专用预测头代表了在效率上的显著改进,其非量化形式只需 36 MB,量化后甚至只需 10 MB。该组件针对意图分类和实体识别等任务保留了自定义配置,同时比传统完整模型消耗的内存大大减少。例如,单个预测头可以在标准 CPU 硬件上在不到 5 毫秒内处理 15x768 维的嵌入向量并输出分类分数。
性能指标和实施
通过使用这种架构进行的测试,收获了令人满意的性能特征。使用一台具有 36 个虚拟 CPU 和 72GB 内存的 c5.9xlarge 实例,单个服务器在仅运行预测头时可以处理约每秒 1,500 笔运算(TPS),且 p90 延迟为 25 毫秒。当将两个组件组合在同一硬件上时,我们仍然可以实现 300TPS,p90 延迟为 35 毫秒——对大多数生产工作负载来说已足够。
编码器组件在 GPU 硬件上部署时(具体为 p3.2xlarge 实例),可以以每秒超过 1,000 个请求的速度处理,延迟仅为 10 毫秒。该配置允许对请求进行高效的分批处理,最佳分批大小为 16 个请求,提供吞吐量和延迟的最佳平衡。
基础设施设计
采用具有特定性能目标的单元架构方法。架构中的每个单元设计用于处理约 1,000 个活跃模型,同时具有自动扩展功能,可在三个可用区域中保持单元的健康状态。系统采用复杂的负载平衡策略,能够处理每个单元高达 600TPS 的突发量,同时保持 p99 延迟在 80 毫秒以下。
为了实现高可用性,架构实施了一种多环设计,其中每个环提供特定的语言区域。例如,所有英语变体可能共享一个环,而法语变体则共享另一个环,可根据特定语言模型特性进行有效的资源分配。每个环包含多个单元格,可以根据需求独立进行扩展。
资源优化
解耦架构实现了显著的资源优化。在生产环境中,实际测量显示如下:
- 内存减少。原始 210 MB 的模型被缩减到 10 MB 的预测头部加上一个共享的 58 MB 编码器。
- 存储效率。编码器可以为数千个预测头提供服务,最多可以减少 75%的总存储需求。
- 成本效率。 GPU 资源在编码器的所有请求之间共享,而更便宜的 CPU 资源用于处理预测头。
- 延迟改善。端到端处理时间,对于缓存模型从 400 毫秒减少到大约 35 毫秒。
对未来的影响
这种架构模式为 ML 部署打开了新的可能性,特别是随着模型规模不断增长。随着当前趋势指向更大的语言模型,共享编码表示变得越来越有价值。这种架构通过以下方式支持未来的增长:
- 动态模型更新:可以部署新的编码器版本,而无需更新预测头。
- 灵活的缩放:基于特定工作负载特征独立缩放编码器和预测组件。
- 资源池:高效共享 GPU 资源,服务于更多客户。
结论
将“共享神经编码器”与“特定任务预测头”相结合的解耦架构代表着机器学习模型部署中的一项重大进步。在性能提升方面表现优秀,例如: 75% 的内存减少、40% 的延迟改善,从而支持高并发模型。该方法提供了一种解决方案,既可以应对规模挑战,同时又能保持性能并控制成本。
对于希望实施类似架构的组织,应仔细考虑特定工作负载特征。方案的成功与否取决于,对基础设施设计和智能资源管理策略的深度思考,只有这样才能支持强大的监控和扩展策略。
译者介绍
崔皓,51CTO社区编辑,资深架构师,拥有18年的软件开发和架构经验,10年分布式架构经验。
原文标题:Scaling ML Models Efficiently With Shared Neural Networks,作者:Meghana Puvvadi