由于深度学习的「黑箱」本性,从业者自我调侃道:
如果说深度神经网络是现代版的「炼金术」,我们在古代就是「炼金术士」。

2018年5月3日, Science发表新闻,标题直指「炼金术」,强调加强AI的科学基础
但这次的谷歌的团队,却有不一样的看法:
在许多方面,深度学习仍然带有一定的「炼金术」色彩,但理解和优化模型性能并不一定如此——即使是在大规模环境下!
近日,谷歌DeepMind科学家Jacob Austint在X上, 发布了基于JAX和TPU的大模型Scaling教科书《How to Sacle Your Model》。

Jeff Dean转发原帖,并打起了广告:
谷歌最强的Gemini模型的训练,重度依赖JAX软件栈+TPU硬件平台。
如果你想了解更多详情,来看看这本超棒的书:「How to Sacle Your Model」。

进入教科书网站,可以看到大写的标题:「如何扩大模型规模(How to Sacle Your Model)」。
正如小标题所言,这本书关于在张量处理单元(TPU)上大语言模型的的系统观点。
这是一本关于LLM底层硬核技术的教科书,简介如下:
训练大语言模型(LLMs)常常让人感觉就像炼金术,但理解和优化模型的性能其实并不复杂。
本书的目标是揭开在TPU上扩展语言模型的科学谜团:TPU是如何工作的,它们如何相互通信,LLM在实际硬件上是如何运行的,以及在训练和推理过程中如何对模型进行并行化,以便在大规模运行时实现高效性。
如果你想知道「训练这个LLM需要多贵的成本」、「要自己部署这个模型需要多少内存」或者「什么是AllGather」这些问题的答案,希望本书能对你有所帮助。
教科书链接:https://jax-ml.github.io/scaling-book/
模型Scaling,无需恐惧
三四年前,大多数机器学习研究人员,可能并不需要了解模型扩展(model scaling)。
但如今,即便是「较小」的模型,也已经逼近硬件极限,因此研究要有真正的创新性,就必须考虑如何在大规模环境下提高效率。
作者详细解释了为什么要模型扩展及其目标:
如果某种方法能在基准测试中提升20%的性能,但同时使Roofline效率下降20%,那么这样的优化是没有意义的。
许多有前景的模型架构最终失败,并不是因为它们在理论上不可行,而是因为它们无法高效扩展,或者没有人投入足够的精力去优化它们的计算效率。
模型扩展的目标是在增加用于训练或推理的芯片数量时,实现吞吐量的线性增长,这被称为 「强扩展」(Strong Scaling)。
通常,增加芯片数量(即「并行计算」)可以减少计算时间,但同时也会带来额外的芯片间通信开销。如果通信时间超过了计算时间,就会遇到 「通信瓶颈」,导致无法实现理想的扩展性能。如果对硬件足够了解,能够预测这些瓶颈的出现位置,就可以通过调整模型设计或重新配置系统来规避它们。
看不懂这些,也没关系,毕竟这是谷歌最强模型Gemini同款的技术栈!
但作者诚意十足,表示:如果认真看完后,有晦涩的地方,请及时反馈,保证一定改。
作者保证:必有所得
从处理单个加速器到处理数万个加速器,相对简单的原则无处不在,了解这些原则可以让你做很多有用的事情:
- 粗略评估模型的各个部分与理论最优性能的接近程度。
- 在不同规模下,合理选择并行计算方案(如何在多个设备间分配计算任务)。
- 估算训练和运行大型Transformer模型所需的成本和时间。
- 设计能够充分利用特定硬件特性的算法。
- 设计硬件时,基于对当前算法性能瓶颈的明确理解来进行优化。
此书的目标是解释TPU(以及 GPU)的工作原理,以及为了当前硬件上实现高效计算,Transformer架构如何不断演化。
希望这些内容既能帮助研究人员设计新的模型架构,也能为工程师提供指导,以优化当前一代的大语言模型(LLM)计算性能。
作者保证,读完此书一定有所收获:
在阅读完本书后,应该能自信地为特定硬件平台上的Transformer模型选择最佳并行方案,并大致估算训练和推理的耗时。
如果你仍然感到困惑,请告诉我们!我们希望知道如何让这些内容更加清晰易懂。
基础知识
要阅读此书,作者提醒读者:
对LLM(大语言模型)和Transformer架构有基本的了解,但不一定熟悉它们在大规模计算中的运作方式。
应该了解LLM训练的基础知识,并且最好对JAX有一定的了解。
下面的背景资料,有助于了解所需的基础知识:
博客链接:https://jalammar.github.io/illustrated-transformer/

JAX讲义:https://github.com/rwitten/HighPerfLLMs2024
整体结构
在本书中,将解答以下问题:
- 矩阵乘法的计算时间如何估算?在多大规模下,它的计算受限于计算能力、内存带宽还是通信带宽?
- TPU是如何连接在一起组成训练集群的?系统的各个部分分别具备多少带宽?
- 在多个TPU之间进行数据收集(gather)、分发(scatter)或重新分布(re-distribute)需要多少时间?
- 如何高效地计算跨设备分布的矩阵乘法?
这些内容能帮助读者,深入理解LLM在现代硬件上的运行机制,并学会如何优化训练和推理的效率。
《第1章》介绍屋顶线分析(Roofline Analysis),并探讨限制模型扩展的关键因素,包括通信、计算和内存。
《第2章》和《第3章》详细讲解TPU和现代GPU的工作原理,既包括作为独立芯片的运行机制,也涵盖了更关键的内容——它们如何通过芯片间互连(inter-chip links)形成一个计算集群,并受到带宽和延迟的限制。
五年前,机器学习领域的架构还十分多样化包——括卷积神经网络、长短时记忆网络、多层感知机和Transformer等。如今,Transformer架构一家独大。
Transformer结构的每一个细节,都非常值得深入理解,包括:矩阵的具体尺寸、归一化(Normalization)发生的位置、各部分包含多少参数和FLOPs(浮点运算次数)。
《第4章》将详细解析Transformer的数学计算,帮助你掌握如何计算训练和推理过程中的参数量和FLOPs。
这些计算将揭示:
- 模型的内存占用有多大?
- 计算和通信的时间消耗分布如何?
- 注意力机制(Attention)和前馈网络(Feed-Forward Blocks)何时成为计算的瓶颈?
通过这些分析,将能够更精确地优化Transformer训练和推理的效率,并更深入地理解其计算特性。
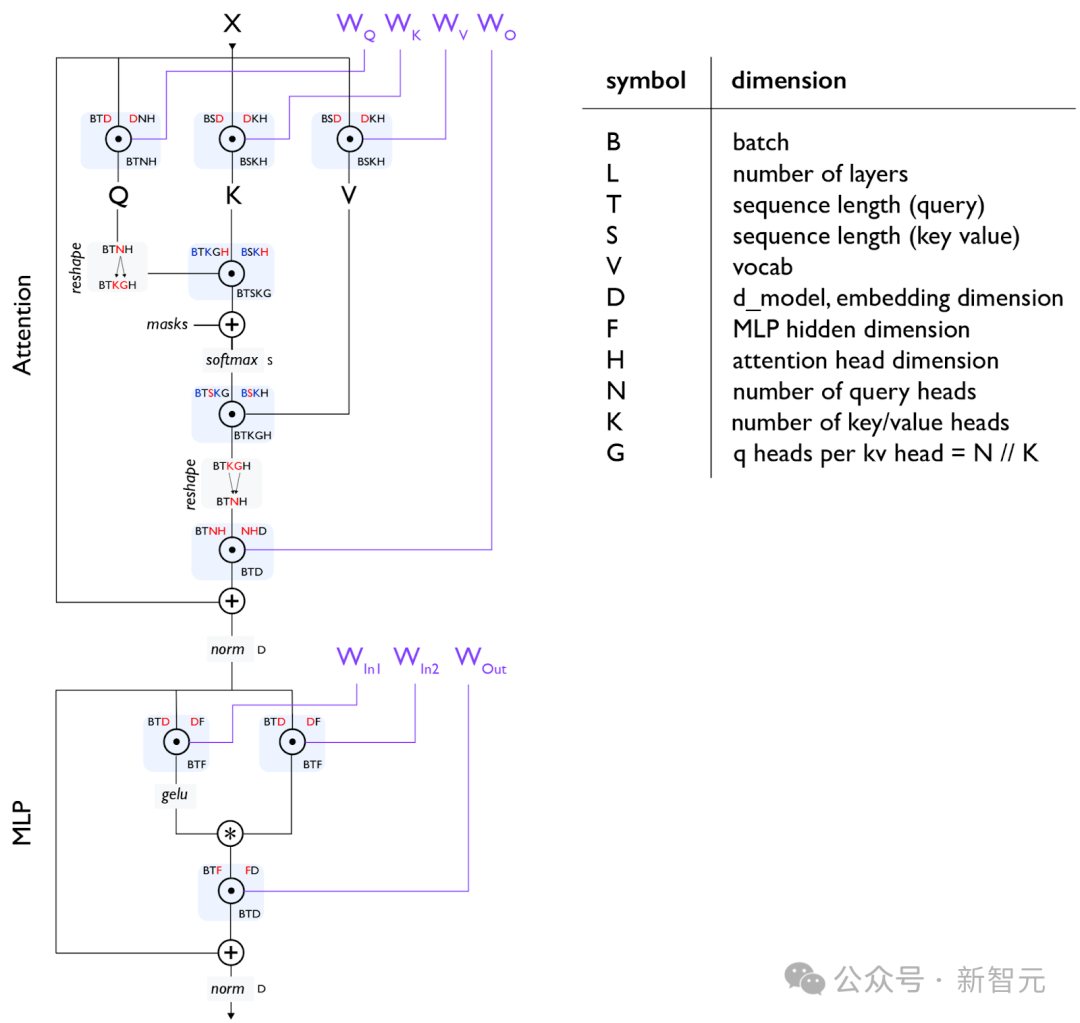
图示2:标准Transformer层,每个矩阵乘法(matmul)以圆圈中的点表示。所有参数(不包括归一化层)以紫色显示。
《第5章:训练》和《第7章:推理》是本书的核心内容,在这两章中将讨论一个根本问题:
给定一个大小和一定数量芯片的模型,如何将模型并行化,以保持在「强扩展」(strong scaling)范畴内?
这个看似简单的问题,其实有着令人意外的复杂答案。
从高层次来看,主要有四种并行化技术用于将模型分布到多个芯片上:数据并行(Data Parallelism)、张量并行(Tensor Parallelism)、流水线并行(Pipeline Parallelism)以及专家并行(Expert Parallelism)。
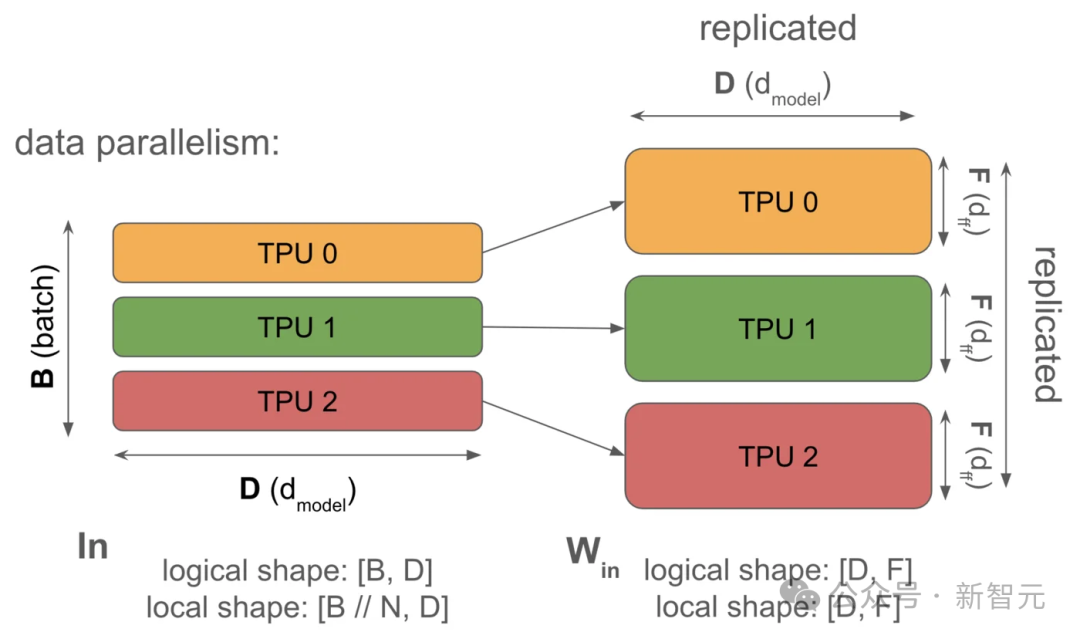
图3:纯数据并行(前向传播)示意图。激活(Activations)(左侧)完全按照批次维度(batch dimension) 进行分片。
这种方法通过将批次分配到多个 TPU 上,实现了数据并行,从而在没有额外通信负担的情况下,加速模型的计算。
此外,还有多种技术可以减少内存需求,比如重新计算(Rematerialization)、优化器/模型分片(Optimizer/Model Sharding,也称为ZeRO)、主机卸载(Host Offload)、梯度累积(Gradient Accumulation)。
在这两章中将讨论这些技术,并帮助理解如何在新的架构或设置中选择最适合的并行化策略。
《第6章》和《第8章》是实际操作教程,应用这些概念于LLaMA-3,更直观地理解如何在实际应用中进行操作。

最后,《第9章》和《第10章》将讨论如何在JAX中实现这些想法,并介绍当代码出现问题时如何进行性能分析和调试。
在《第11章》中,会给出进一步阅读清单和更深入的参考文献。
在整个过程中,会给出一些需要自己动手解决的问题。
作者温馨提示:
请不要觉得有压力要按顺序阅读所有章节,也不一定要全部阅读完。
我们鼓励你留下反馈意见。
目前这是草稿版本,未来会继续修订和改进。
当前的目录,翻译如下: