前言
某次金融系统迁移项目中,原计划8小时完成的用户数据同步迟迟未能完成。
24小时后监控警报显示:由于全表扫描SELECT * FROM users导致源库CPU几乎熔毁,业务系统被迫停机8小时。
这让我深刻领悟到——10亿条数据不能用蛮力搬运,得用巧劲儿递接!
今天这篇文章,跟大家一起聊聊10亿条数据,如何做迁移,希望对你会有所帮助。
一、分而治之
若把数据迁移比作吃蛋糕,没人能一口吞下整个十层蛋糕;
必须切成小块细嚼慢咽。
避坑案例:线程池滥用引发的血案
某团队用100个线程并发插入新库,结果目标库死锁频发。
最后发现是主键冲突导致——批处理必须兼顾顺序和扰动。
分页迁移模板代码:
避坑指南:
- 每批取递增ID而不是OFFSET,避免越往后扫描越慢
- 批处理大小根据目标库写入能力动态调整(500-5000条/批)
二、双写
经典方案是停机迁移,但对10亿数据来说停机成本难以承受,双写方案才是王道。
双写的三种段位:
- 青铜级:先停写旧库→导数据→开新库 →风险:停机时间不可控
- 黄金级:同步双写+全量迁移→差异对比→切流 →优点:数据零丢失
- 王者级:逆向同步兜底(新库→旧库回写),应对切流后异常场景
当然双写分为:
- 同步双写
- 异步双写
同步双写实时性更好,但性能较差。
异步双写实时性差,但性能更好。
我们这里考虑使用异步双写。
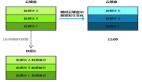
异步双写架构如图所示:
 图片
图片
代码实现核心逻辑:
- 开启双写开关
- 差异定时校验
三、用好工具
不同场景需匹配不同的工具链,好比搬家时家具用货车,细软用包裹。
工具选型对照表
工具名称 | 适用场景 | 10亿数据速度参考 |
mysqldump | 小型表全量导出 | 不建议(可能天级) |
MySQL Shell | InnoDB并行导出 | 约2-4小时 |
DataX | 多源异构迁移 | 依赖资源配置 |
Spark | 跨集群大数据量ETL | 30分钟-2小时 |
Spark迁移核心代码片段:
避坑经验:
- 分区数量应接近Spark执行器核数,太多反而降低效率
- 分区字段必须是索引列,防止全表扫
四、影子测试
迁移后的数据一致性验证,好比宇航员出舱前的模拟训练。
影子库验证流程:
- 生产流量同时写入新&旧双库(影子库)
- 对比新旧库数据一致性(抽样与全量结合)
- 验证新库查询性能指标(TP99/TP95延迟)
自动化对比脚本示例:
五、回滚
即便做好万全准备,也要设想失败场景的回滚方案——迁移如跳伞,备份伞必须备好。
回滚预案关键点:
- 备份快照:迁移前全量快照(物理备份+ Binlog点位)
- 流量回切:准备路由配置秒级切换旧库
- 数据标记:新库数据打标,便于清理脏数据
快速回滚脚本:
总结
处理10亿数据的核心心法:
- 分而治之:拆解问题比解决问题更重要。
- 逐步递进:通过灰度验证逐步放大流量。
- 守牢底线:回滚方案必须真实演练过。
记住——没有百分百成功的迁移,只有百分百准备的Plan B!
搬运数据如同高空走钢丝,你的安全保障(备份、监控、熔断)就是那根救命绳。