译者 | 核子可乐
审校 | 重楼
2025年将成为AI智能体之年。在本文的场景中,AI智能体是一套能够利用AI通过一系列步骤实现目标的系统,且具备就结果进行推理及更正的能力。在实践中,智能体遵循的步骤可总结成图表形式。
我们将构建一款响应式应用(对来自用户的输入做出响应),帮助人们规划自己的完美假期。此智能体将根据用户指定的餐食、海滨和活动需求,在指定的国家/地区内推荐最佳城市。
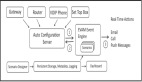
智能体基本架构如下:

在第一阶段,智能体将并行收集信息,根据单一特征对各城市进行排名。最后一步代表根据信息选出的最佳城市。
本用例仅使用ChatGPT执行所有步骤,大家也可根据需求配合搜索引擎。这里使用Fibry中手动添加的Actor系统以显示图形并细化控制并行性。
Fibry是一款轻量化Actor系统,允许参与者轻松简化多线程代码,且不涉及任何依赖项。Fibry还提供有限状态机,这里我们将对其扩展以实现Java编程。
这里建议大家使用Fibry 3.0.2,如:
Plain Text
1
compile group: 'eu.lucaventuri', name: 'fibry', version: '3.0.2'设定提示词
第一步是设定大模型所需要的揭示词:
Java
public static class AiAgentVacations {
private static final String promptFood = "You are a foodie from {country}. Please tell me the top 10 cities for food in {country}.";
private static final String promptActivity = "You are from {country}, and know it inside out. Please tell me the top 10 cities in {country} where I can {goal}";
private static final String promptSea = "You are an expert traveler, and you {country} inside out. Please tell me the top 10 cities for sea vacations in {country}.";
private static final String promptChoice = """
You enjoy traveling, eating good food and staying at the sea, but you also want to {activity}. Please analyze the following suggestions from your friends for a vacation in {country} and choose the best city to visit, offering the best mix of food and sea and where you can {activity}.
Food suggestions: {food}.
Activity suggestions: {activity}.
Sea suggestions: {sea}.
""";
}设定状态
一般我们会在四个步骤中各设定一个状态。但由于分支往来比较常见,因此这里专门添加功能来仅使用一个状态处理此问题。因此,我们只需要用到两个状态:CITIES,即收集信息的城市,以及CHOICE,即我们选定的城市。
Plain Text
1
enum VacationStates { CITIES, CHOICE }设定上下文
智能体中的各步骤将收集存储在他处的信息,我们称之为上下文。理想情况下,每个步骤最好各自独立,且尽可能少触及其他步骤。但既要保持实现简单、使用的代码量不大,同时保持尽可能多的类型安全性与线程安全,显然不是件容易的事。
因此这里选择强制上下文记录,提供部分功能以更新记录的值(使用下面列出的反射),同时等待JEP 468(创建派生记录)的实现。
Java
public record VacationContext(String country, String goal, String food, String activity, String sea, String proposal) {
public static VacationContext from(String country, String goal) {
return new VacationContext(country, goal, null, null, null, null);
}
}设定节点
现在我们可以设定智能体的逻辑。本用例允许用户使用两种不同的大语言模型,如用于搜索的“普通”模型和用于选择步骤的“推理”模型。
到这里开始上难度了,因为信息密度很大:
Java
AgentNode<VacationStates, VacationContext> nodeFood = state -> state.setAttribute("food", modelSearch.call("user", replaceField(promptFood, state.data(), "country")));
AgentNode<VacationStates, VacationContext> nodeActivity = state -> state.setAttribute("activity", modelSearch.call("user", replaceField(promptActivity, state.data(), "country")));
AgentNode<VacationStates, VacationContext> nodeSea = state -> state.setAttribute("sea", modelSearch.call("user", replaceField(promptSea, state.data(), "country")));
AgentNode<VacationStates, VacationContext> nodeChoice = state -> {
var prompt = replaceAllFields(promptChoice, state.data());
System.out.println("***** CHOICE PROMPT: " + prompt);
return state.setAttribute("proposal", modelThink.call("user", prompt));
};大家肯定已经猜到,modelSearch代表用于搜索的模型(如ChatGPT 40),
modelThink代表“推理模型”(如ChatGPT o1)。Fibry提供一个简单的大模型接口和一个简单的ChatGPT实现,并通过ChatGpt类进行公开。
请注意,调用ChatGPT API需要相应的API密钥,你需要使用“-DOPENAI_API_KEY=xxxx” JVM参数来定义此密钥。
还有一个跟Fibry理念相关的小问题,因为其不涉及任何依赖项,所以这在JSON中会比较麻烦。这里Fibry可以通过两种方式运行:
- 若检测到Jackson,Fibry将使用它进行反射以解析JSON。
- 若未检测到Jackson,则使用简单的自定义解析器(似乎可与ChatGPT输出搭配使用)。但这种方法仅适用于快速测试,不推荐在生产环境下使用。
- 或者,你也可以提供自己的JSON处理器实现并调用JsonUtils.setProcessor(),也可查看JacksonProcessor以获取灵感。
- replaceField() 和 replaceAllFields()方法由RecordUtils 定义,且只是替换提示词中文本内容的便捷方法,以便我们将数据提供给大模型。 setAttribute()函数用于设置状态中属性的值,而无需手动重新创建记录或定义“withers”方法。大家也可以使用其他方法,例如 mergeAttribute(), addToList(), addToSet()和 addToMap()。
构建智能体
逻辑已经有了,接下来需要描述各状态间的依赖关系图并指定希望实现的并行性。对于生产运行状态下的大型多功能体系统,最重要的就是既通过并行性实现性能最大化,又不致耗尽资源、达到速率限制或者超过外部系统的承载上限。这就是Fibry的意义所在,它能让整个设计思路非常明确,而且设置难度也不算高。
首先创建智能体builder:
Plain Text
var builder = AiAgent.<VacationStates, VacationContext>builder(true);其中参数autoGuards 用于对状态设置自动保护,其以AND逻辑执行,且仅在处理完所有传入状态后才会执行该状态。
若参数为false,则每个传入状态调用一次该状态。

在以上示例中,若目标是执行两次D,分别在A和C之后,则autoGuards应当为false。若希望在A和C之后再执行一次D,则autoGuards应为true。
这里继续说回咱们的度假智能体。
Plain Text
builder.addState(VacationStates.CHOICE, null, 1, nodeChoice, null);让我们从addState()方法开始。它用于指定某个状态应跟踪另一状态并执行某个逻辑。此外,大家还可以指定并行性(后文具体介绍)和guards。
在本示例中:
- 状态为CHOICE
- 无默认的后续状态
- 并行性为1
- 无guard
下一状态仅为默认状态,因为节点可能会覆盖下一状态,因此上图可以在运行时动态变更,特别是可以执行循环。例如需要重复某些步骤以收集更多或更好的信息这类高级用例。
并行性在这里没有涵盖,因为智能体的单次运行不太涉及这个问题,但在大规模生产中却非常重要。
在Fibry中,每个节点都由一个actor支持——所谓actor,其实就是一个包含待处理消息列表的线程。每条消息都代表一个执行步骤。因此,并行度指可以一次执行的消息数。具体来讲:
- parallelism == 1 代表只有一个线程管理该步骤,因此每次只能执行一条。
- parallelism > 1 代表有一个线程池支持该actor,线程数由用户指定。默认情况下使用虚拟线程。
- parallelism == 0 代表每条消息都会创建一个由虚拟线程支持的新actor,因此并行度可根据需求尽量调高。
每个步骤均可独立配置,因此大家可以灵活配置性能和资源使用情况。请注意,如果parallelism != 1则可能存在多线程,因为与actor相关的线程限制经常会丢失。
状态压缩
如前所述,多个状态彼此关联也是常见情况,比如需要并行执行和加入,而后才能转向公共状态。这时候我们不需要设定多个状态,而只使用其一:
Plain Text
builder.addStateParallel(VacationStates.CITIES, VacationStates.CHOICE, 1, List.of(nodeFood, nodeActivity, nodeSea), null);在这种情况下,我们看到CITIES 状态由三个节点定义,其中addStateParallel()负责并行执行各节点并等待所有节点执行完成。这时候应该在每个节点上应用并行性,借此获取三个单线程actor。
请注意,如果不使用autoGuards,则可将OR 与 AND逻辑混合起来。
如果希望合并一些处于相同状态的节点,但要求其按顺序执行(例如需要使用前一个节点生成的信息),则可使用 addStateSerial()方法。
AI智能体的创建很简单,但需要指定相关参数:
- 初始状态
- 最终状态(可以为null)
- 尽量并行执行的状态标记
Plain Text
var vacationAgent = builder.build(VacationStates.CITIES, null, true);现在我们已经有了智能体,调用进程即可使用:
Plain Text
vacationsAgent.process(AiAgentVacations.VacationContext.from("Italy", "Dance Salsa and Bachata"), (state, info) -> System.out.println(state + ": " + info));此版本的 process() 需要两个参数:
- 初始状态,其中包含智能体执行操作所需要的信息
- 可选监听器,支持如打印各步骤输出等需求
若需要启动操作并检查其后续返回值,可以使用 processAsync()。
如果大家关注并行选项的更多信息,建议各位查看单元测试 TestAIAgent。它会模拟节点休眠一段时间后的智能体,借此查看各选项的实际影响:

扩展至多智能体
我们刚刚创建的是一个actor智能体,它会在自己的线程上(加上各节点使用的所有线程)运行,并实现了Function接口以备不时之需。
多智能体其实没什么特别,基本逻辑就是一个智能体的一个或多个节点要求另一智能体执行操作。我们可以构建一套智能体库以将它们良好组合起来,从而简化整个系统。
接下来,我们要利用之前的智能体输出计算度假费用,以便用户判断是否符合需求。到这里,是不是就跟真正的旅行社很像了?
下图为构建流程:

首先用提示词来提取目的地并计算成本。
Java
private static final String promptDestination = "Read the following text describing a destination for a vacation and extract the destination as a simple city and country, no preamble. Just the city and the country. {proposal}";
private static final String promptCost = "You are an expert travel agent. A customer asked you to estimate the cost of travelling from {startCity}, {startCountry} to {destination}, for {adults} adults and {kids} kids}";这里只需两个状态,一个用于研究城市(由上一智能体完成),另一个用于计算费用。
Plain Text
enum TravelStates { SEARCH, CALCULATE }我们还需要上下文,此上下文负责保存上一智能体的提议。
Plain Text
public record TravelContext(String startCity, String startCountry, int adults, int kids, String destination, String cost, String proposal) { }之后可以定义智能体逻辑,该逻辑需要另一智能体作为参数。首节点调用上一智能体以获取提议。
Java
var builder = AiAgent.<TravelStates, TravelContext>builder(false);
AgentNode<TravelStates, TravelContext> nodeSearch = state -> {
var vacationProposal = vacationsAgent.process(AiAgentVacations.VacationContext.from(country, goal), 1, TimeUnit.MINUTES, (st, info) -> System.out.print(debugSubAgentStates ? st + ": " + info : ""));
return state.setAttribute("proposal", vacationProposal.proposal())
.setAttribute("destination", model.call(promptDestination.replaceAll("\\{proposal\\}", vacationProposal.proposal())));
};第二节点负责计算成本:
Plain Text
AgentNode<TravelStates, TravelContext> nodeCalculateCost = state -> state.setAttribute("cost", model.call(replaceAllFields(promptCost, state.data())));之后是定义图表并构建智能体:
Java
builder.addState(TravelStates.SEARCH, TravelStates.CALCULATE, 1, nodeSearch, null);
builder.addState(TravelStates.CALCULATE, null, 1, nodeCalculateCost, null);
var agent = builder.build(TravelStates.SEARCH, null, false);
Now we can instantiate the two agents (I chose to use ChatGPT 4o and ChatGPT 01-mini) and use them:Java
try (var vacationsAgent = AiAgentVacations.buildAgent(ChatGPT.GPT_MODEL_4O, ChatGPT.GPT_MODEL_O1_MINI)) {
try (var travelAgent = AiAgentTravelAgency.buildAgent(ChatGPT.GPT_MODEL_4O, vacationsAgent, "Italy", "Dance Salsa and Bachata", true)) {
var result = travelAgent.process(new AiAgentTravelAgency.TravelContext("Oslo", "Norway", 2, 2, null, null, null), (state, info) -> System.out.println(state + ": " + info));
System.out.println("*** Proposal: " + result.proposal());
System.out.println("\n\n\n*** Destination: " + result.destination());
System.out.println("\n\n\n*** Cost: " + result.cost());
}
}最终输出
假设我们说自己想跳萨尔萨舞和巴恰塔舞,得到的长输出如下:
目的地
Plain Text
Naples, Italy提议
Plain Text
Based on the comprehensive analysis of your friends' suggestions, **Naples** emerges as the ideal city for your vacation in Italy. Here's why Naples stands out as the best choice, offering an exceptional mix of excellent food, beautiful seaside experiences, and a vibrant salsa and bachata dance scene:
### **1. Vibrant Dance Scene**
- **Dance Venues:** Naples boasts numerous venues and events dedicated to salsa and bachata, ensuring that you can immerse yourself in lively dance nights regularly.
- **Passionate Culture:** The city's passionate and energetic atmosphere enhances the overall dance experience, making it a hotspot for Latin dance enthusiasts.
### **2. Culinary Excellence**
- **Authentic Neapolitan Pizza:** As the birthplace of pizza, Naples offers some of the best and most authentic pizzerias in the world.
- **Fresh Seafood:** Being a coastal city, Naples provides access to a wide variety of fresh seafood dishes, enhancing your culinary adventures.
- **Delicious Pastries:** Don't miss out on local specialties like **sfogliatella**, a renowned Neapolitan pastry that is a must-try for any foodie.
### **3. Stunning Seaside Location**
- **Bay of Naples:** Enjoy breathtaking views and activities along the Bay of Naples, including boat tours and picturesque sunsets.
- **Proximity to Amalfi Coast:** Naples serves as a gateway to the famous Amalfi Coast, allowing you to explore stunning coastal towns like Amalfi, Positano, and Sorrento with ease.
- **Beautiful Beaches:** Relax on the city's beautiful beaches or take short trips to nearby seaside destinations for a perfect blend of relaxation and exploration.
### **4. Cultural Richness**
- **Historical Sites:** Explore Naples' rich history through its numerous museums, historic sites, and UNESCO World Heritage landmarks such as the Historic Centre of Naples.
- **Vibrant Nightlife:** Beyond dancing, Naples offers a lively nightlife scene with a variety of bars, clubs, and entertainment options to suit all tastes.
### **5. Accessibility and Convenience**
- **Transportation Hub:** Naples is well-connected by air, rail, and road, making it easy to travel to other parts of Italy and beyond.
- **Accommodation Options:** From luxury hotels to charming boutique accommodations, Naples offers a wide range of lodging options to fit your preferences and budget.
### **Conclusion**
Naples perfectly balances a thriving dance scene, exceptional culinary offerings, and beautiful seaside attractions. Its unique blend of culture, history, and vibrant nightlife makes it the best city in Italy to fulfill your desires for travel, good food, and lively dance experiences. Whether you're dancing the night away, savoring authentic pizza by the sea, or exploring nearby coastal gems, Naples promises an unforgettable vacation.
### **Additional Recommendations**
- **Day Trips:** Consider visiting nearby attractions such as Pompeii, the Isle of Capri, and the stunning Amalfi Coast to enrich your travel experience.
- **Local Experiences:** Engage with locals in dance classes or attend festivals to dive deeper into Naples' vibrant cultural scene.
Enjoy your trip to Italy, and may Naples provide you with the perfect blend of everything you're looking for!费用
Plain Text
To estimate the cost of traveling from Oslo, Norway, to Naples, Italy, for two adults and two kids, we need to consider several key components of the trip: flights, accommodations, local transportation, food, and activities. Here's a breakdown of potential costs:
1. **Flights**:
- Round-trip flights from Oslo to Naples typically range from $100 to $300 per person, depending on the time of booking, the season, and the airline. Budget airlines might offer lower prices, while full-service carriers could be on the higher end.
- For a family of four, the cost could range from $400 to $1,200.
2. **Accommodations**:
- Hotels in Naples can vary significantly. Expect to pay approximately $70 to $150 per night for a mid-range hotel room that accommodates a family. Vacation rentals might offer more flexibility and potentially lower costs.
- For a typical 5-night stay, this would range from $350 to $750.
3. **Local Transportation**:
- Public transportation in Naples (buses, metro, trams) is affordable, and daily tickets cost around $4 per person.
- Assume about $50 to $100 for the family's local transport for the entire trip, depending on usage.
4. **Food**:
- Dining costs are highly variable. A budget for meals might be around $10-$20 per person per meal at casual restaurants, while dining at mid-range restaurants could cost $20-$40 per person.
- A family of four could expect to spend around $50 to $100 per day, reaching a total of $250 to $500 for five days.
5. **Activities**:
- Entry fees for attractions can vary. Some museums and archaeological sites charge around $10 to $20 per adult, with discounts for children.
- Budget around $100 to $200 for family activities and entrance fees.
6. **Miscellaneous**:
- Always allow a little extra for souvenirs, snacks, and unexpected expenses. A typical buffer might be $100 to $200.
**Estimated Total Cost**:
- **Low-end estimate**: $1,250
- **High-end estimate**: $2,950
These are general estimates and actual costs can vary based on when you travel, how far in advance you book, and your personal preferences for accommodation and activities. For the most accurate assessment, consider reaching out to airlines for current flight prices, hotels for room rates, and looking into specific attractions you wish to visit.内容着实不少,而且这还只是两个“推理”模型的输出!
但结果非常有趣,那不勒斯也确实是个不错的选项。接下来我们检查一下中间结果,发现得出结论的过程相当合理。
中间输出
如果感兴趣,大家还可以查看中间结果。
餐食
Plain Text
As a foodie exploring Italy, you're in for a treat, as the country boasts a rich culinary heritage with regional specialties. Here's a list of the top 10 cities in Italy renowned for their food:
1. **Bologna** - Often referred to as the gastronomic heart of Italy, Bologna is famous for its rich Bolognese sauce, tasty mortadella, and fresh tagliatelle.
2. **Naples** - The birthplace of pizza, Naples offers authentic Neapolitan pizza, as well as delicious seafood and pastries like sfogliatella.
3. **Florence** - Known for its Florentine steak, ribollita (a hearty bread and vegetable soup), and delicious wines from the surrounding Tuscany region.
4. **Rome** - Enjoy classic Roman dishes such as carbonara, cacio e pepe, and Roman-style artichokes in the bustling capital city.
5. **Milan** - A city that blends tradition and innovation, Milan offers risotto alla milanese, ossobuco, and an array of high-end dining experiences.
6. **Turin** - Known for its chocolate and coffee culture, as well as traditional dishes like bagna cauda and agnolotti.
7. **Palermo** - Sample the vibrant street food scene with arancini, panelle, and sfincione, as well as fresh local seafood in this Sicilian capital.
8. **Venice** - Famous for its seafood risotto, sarde in saor (sweet and sour sardines), and cicchetti (Venetian tapas) to enjoy with a glass of prosecco.
9. **Parma** - Home to the famous Parmigiano-Reggiano cheese and prosciutto di Parma, it’s a haven for lovers of cured meats and cheeses.
10. **Genoa** - Known for its pesto Genovese, focaccia, and variety of fresh seafood dishes, Genoa offers a unique taste of Ligurian cuisine.
Each of these cities offers a distinct culinary experience influenced by local traditions and ingredients, making them must-visit destinations for any food enthusiast exploring Italy.海滨
Plain Text
Italy is renowned for its stunning coastline and beautiful seaside cities. Here are ten top cities and regions perfect for a sea vacation:
1. **Amalfi** - Nestled in the famous Amalfi Coast, this city is known for its dramatic cliffs, azure waters, and charming coastal villages.
2. **Positano** - Also on the Amalfi Coast, Positano is famous for its colorful buildings, steep streets, and picturesque pebble beachfronts.
3. **Sorrento** - Offering incredible views of the Bay of Naples, Sorrento serves as a gateway to the Amalfi Coast and provides a relaxing seaside atmosphere.
4. **Capri** - The island of Capri is known for its rugged landscape, upscale hotels, and the famous Blue Grotto, a spectacular sea cave.
5. **Portofino** - This quaint fishing village on the Italian Riviera is known for its picturesque harbor, pastel-colored houses, and luxurious coastal surroundings.
6. **Cinque Terre** - Comprising five stunning villages along the Ligurian coast, Cinque Terre is a UNESCO World Heritage site known for its dramatic seaside and hiking trails.
7. **Taormina** - Situated on a hill on the east coast of Sicily, Taormina offers sweeping views of the Ionian Sea and beautiful beaches like Isola Bella.
8. **Rimini** - Located on the Adriatic coast, Rimini is known for its long sandy beaches and vibrant nightlife, making it a favorite for beach-goers and party enthusiasts.
9. **Alghero** - A city on the northwest coast of Sardinia, Alghero is famous for its medieval architecture, stunning beaches, and Catalan culture.
10. **Lerici** - Near the Ligurian Sea, Lerici is part of the stunning Gulf of Poets and is known for its beautiful bay, historic castle, and crystal-clear waters.
Each of these destinations offers a unique blend of beautiful beaches, cultural sites, and local cuisine, making Italy a fantastic choice for a sea vacation.活动
Plain Text
Italy has a vibrant dance scene with many cities offering great opportunities to enjoy salsa and bachata. Here are ten cities where you can indulge in these lively dance styles:
1. **Rome** - The capital city has a bustling dance scene with numerous salsa clubs and events happening regularly.
2. **Milan** - Known for its nightlife, Milan offers various dance clubs and events catering to salsa and bachata enthusiasts.
3. **Florence** - A cultural hub, Florence has several dance studios and clubs where you can enjoy Latin dances.
4. **Naples** - Known for its passionate culture, Naples offers several venues and events for salsa and bachata lovers.
5. **Turin** - This northern city has a growing salsa community with events and social dances.
6. **Bologna** - Known for its lively student population, Bologna has a number of dance clubs and events for salsa and bachata.
7. **Venice** - While famous for its romantic canals, Venice also hosts various dance events throughout the year.
8. **Palermo** - In Sicily, Palermo has a vibrant Latin dance scene reflecting the island's festive culture.
9. **Verona** - Known for its romantic setting, Verona has several dance studios and clubs for salsa and bachata.
10. **Bari** - This coastal city in the south offers dance festivals and clubs perfect for salsa and bachata enthusiasts.
These cities offer a mix of cultural experiences and lively dance floors, ensuring you can enjoy salsa and bachata across Italy.有趣的是,那不勒斯在各个分段排名上都没登顶,但综合下来却是最优选项。
许可细节
这里再聊几句关于Fibry许可证的情况。FIbry目前已经不再以纯MIT许可证的形式发布。最大的变更是,如果大家想要急雨 套系统来为第三方(如软件工程师智能体)大规模生成代码,则需要申请商业许可证。此外,它还禁止用户将其作为数据集来训练系统生成代码(例如ChatGPT不得在Fibry的源代码上进行训练)。除此之外,所有用途都不受影响。
总结
希望这篇文章能帮助大家了解如何使用Fibry编写AI智能体。其实对于分布在多个节点上的多智能体系统,Fibry也不在话下!但受篇幅所限,这里不过多展开。
在Fibry中,通过网络的消息发送和接收会被抽象出来,因此无需修改智能体逻辑即可实现分发。这使得Fibry能够轻松实现跨节点扩展,核心逻辑完全不受影响。
祝大家编码愉快!
原文标题:Designing AI Multi-Agent Systems in Java,作者:Luca Venturi