













Hello folks,我是 Luga,今天我们来聊一下人工智能应用场景 - 构建高效、灵活的计算架构的 GPU 内存交换机技术。
众所周知,LLMs 虽然在诸多任务中表现出色,但其庞大的模型体积和复杂的计算需求,使得高效利用 GPU 资源成为一大难题。
尤其是在高并发场景下,如何快速加载和卸载模型,避免 GPU 闲置,成为影响推理性能和成本的关键因素...

一、GPU 设备资源调度的当前现状与困境
随着AI 产业的持续落地,越来越多的公司开始将大型语言模型(LLMs)部署到生产环境,并确保能够大规模服务于用户。
然而,与此同时,企业却面临着一个极为严峻的挑战:如何在保障高负载期间提供快速响应的同时,确保 GPU 资源的使用高效,从而有效控制成本。在这种情况下,企业通常需要在两种策略之间做出艰难的权衡选择:
策略一:过度配置以应对流量高峰
在这种策略下,企业为了应对可能出现的流量高峰,会提前部署大量配备 GPU 的副本。这些副本能够确保在流量激增时,系统能够快速响应,保持稳定的服务质量,避免任何服务中断。虽然这种方法在短期内能够保障系统性能,防止因资源不足导致的故障或延迟,但也带来了一些明显的劣势。
最为显著的是,这些 GPU 资源在大部分时间内会处于闲置状态,导致硬件资源的大量浪费。企业不得不为这些空闲的计算资源支付高昂的费用,造成了资金的严重浪费,极大地消耗了预算。因此,这种策略虽然能够保障性能,却由于过度配置资源而带来了高昂的运营成本。
策略二:动态调整资源的零点扩容
为了避免前述策略中的资源浪费,一些企业采取了积极的零点扩容策略。这种方法通过动态调整计算资源,依据实际流量需求来优化 GPU 的分配。通过实时监控和快速响应,这种策略旨在根据实时负载来增加或减少计算资源,从而避免资源闲置的浪费。理论上,这种方法能够降低成本,确保资源的高效利用。
然而,零点扩容的策略也存在一定的风险,特别是在流量的突发波动期间。由于资源的动态调整无法及时跟上流量的激增,用户可能会面临长时间的延迟,甚至在极端情况下可能会出现服务不可用的情况。延迟的增加不仅会影响用户体验,还可能导致用户的流失,进而影响企业的声誉和品牌价值。因此,尽管这种策略能有效节省资源和成本,但在高负载时,它往往会牺牲用户体验,导致性能下降。
这两种策略各有利弊,企业面临的核心挑战就是如何在性能和成本之间找到最佳的平衡点。
策略一虽然确保了在高负载时服务的连续性和快速响应,但却导致了硬件资源的大量浪费和高额的运营成本;
而策略二虽然能够有效节省计算资源和运营成本,但可能在突发流量高峰时导致性能的下降,影响用户体验。这种权衡问题正是大规模部署 LLMs 时,尤其是在面对高并发和突发流量场景时,企业必须解决的核心难题。
那么,如何破局?...
二、何为 Model Hot Swapping 技术?
作为一项创新技术,旨在进一步拓展 GPU 在推理工作负载中的利用率, Run:ai 的 GPU 内存交换,又称“模型热交换(Model Hot Swapping)” 便应运而生,以解决上述痛点。
Model Hot Swapping 技术旨在解决大规模部署大型语言模型(LLMs)时所面临的一个重大挑战,特别是在高负载、高并发的生产环境中。传统的 GPU 内存管理方法往往要求在模型加载和切换时进行重启或重新初始化,这不仅会浪费大量时间,还会导致资源闲置和推理延迟。
而 Model Hot Swapping 技术则通过允许在 GPU 内存中动态加载和卸载不同的模型,完全避免了这些问题。在此技术的加持下,GPU 能够在无需重启的情况下,根据具体的推理请求,实时地加载所需的模型,并立即开始推理任务。推理完成后,模型会被卸载,释放 GPU 内存空间,为其他模型的加载提供足够的资源。
在实际的场景中,Model Hot Swapping 技术优势主要体现在如下几个方面:
1. 极大地提高 GPU 利用率
通过动态加载和卸载模型,GPU 始终保持在工作状态,避免了因模型加载和切换导致的 GPU 资源闲置。传统的静态模型加载方式往往使得 GPU 在某些时刻空闲,浪费了宝贵的计算资源。而通过这种技术,GPU 的计算能力被充分调动,确保其始终处于高效运行状态。
2. 显著降低推理延迟
基于此技术,模型可以迅速加载并立即开始推理,极大地减少了因模型加载过程而产生的延迟。对于需要快速响应的应用场景,推理延迟的降低直接提升了系统的响应速度和用户体验,尤其是在面对大量并发请求时,能够提供更加流畅和即时的服务。
3. 有效降低部署成本
由于 GPU 资源得到了更高效的利用,企业不再需要为每个模型准备大量的独立 GPU 设备。这种动态调度模型的方式显著减少了所需的 GPU 数量,进而降低了硬件采购和运维成本。此外,减少了 GPU 空闲的时间,也进一步降低了能源消耗和运维费用。
三、为什么需要 Model Hot Swapping 技术?
Model Hot Swapping(模型热交换)的引入,为模型服务中的资源管理带来了一种更具活力的动态方式,允许多个模型共享同一组 GPU,即便它们的总内存需求超过了可用的 GPU 容量。其核心运作方式如下:
- 动态内存卸载: 在特定时间段内没有接收到任何请求的模型,将不再持续占用 GPU 内存。它们会被交换到 CPU 内存中,以释放宝贵的 GPU 资源。
- 快速激活: 当接收到新的请求时,所需的模型会以极小的延迟被迅速交换回 GPU 内存,并立即投入运行。
- 更多模型副本,更少硬件投入: 模型热交换技术支持多个模型共享相同的硬件资源,从而显著减少了“常驻运行”的机器数量,同时又不会影响响应速度。此外,由于服务器(即 CPU 进程)即使在 GPU 部分被交换出去时仍然保持活动状态,因此当需要重新激活某个模型副本时,可以快速完成,因为服务器已经初始化。
通过模型热交换,企业能够高效地处理不可预测的工作负载,同时避免因过度配置硬件而造成的资源浪费。这意味着企业可以在保障服务性能的前提下,大幅降低硬件成本和运营成本,从而实现更高效、更经济的 LLM 部署。
来一些对比测试数据,具体可参考如下:
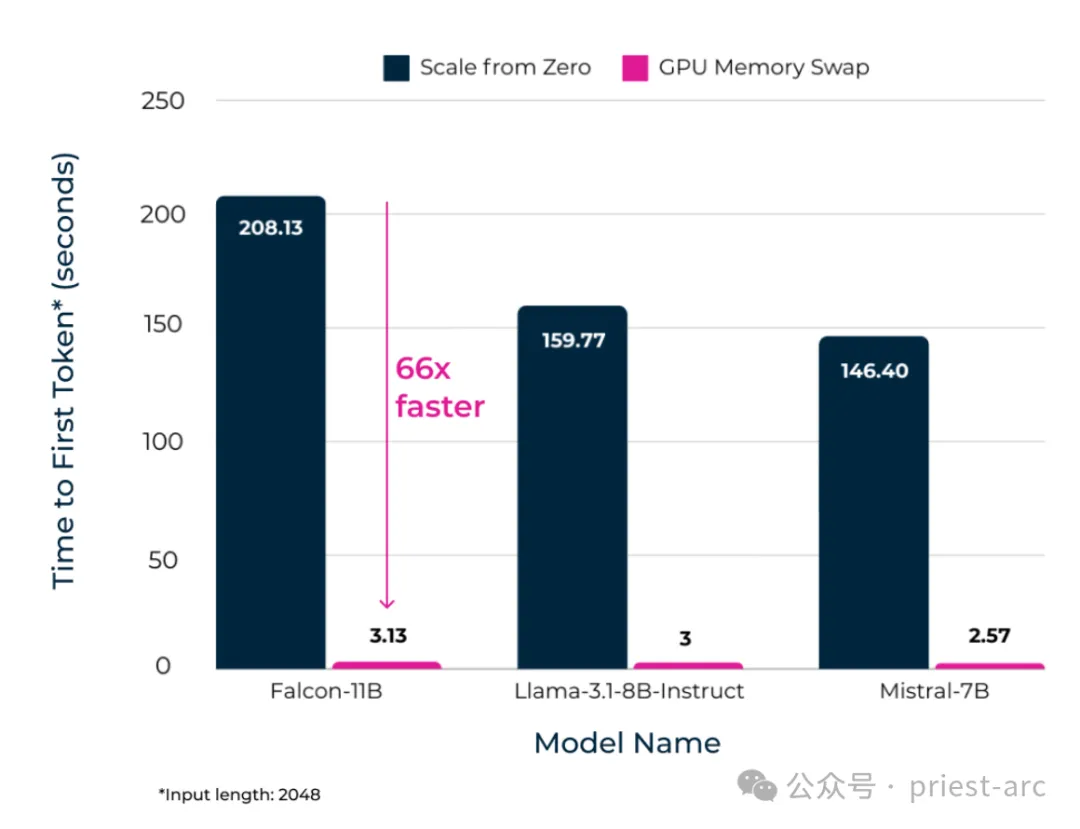
Model Hot Swapping(模型热交换)内存交换技术为企业在部署大型语言模型(LLMs)时提供了一种创新的解决方案,成功在性能和成本之间找到了理想的平衡点。该技术通过优化模型加载和内存管理,将模型加载时间(TTFT,Time to First Token)缩短至仅几秒钟,显著提升了系统的响应速度。这种方法使企业能够将更多的工作负载整合到更少的 GPU 上,同时保持严格的服务水平协议(SLAs),确保系统的高效性和可靠性。
与传统的始终保持“温暖”状态的常驻模型相比,Model Hot Swapping 技术在仅牺牲少量延迟的情况下,实现了显著的成本节约。通过动态加载和卸载模型,企业可以避免在低负载时期维持大量闲置的 GPU 资源,从而大幅降低硬件成本和能源消耗。
尽管 Model Hot Swapping 技术涉及模型的动态加载和卸载,但其优化的内存交换机制确保了模型加载时间(TTFT)被控制在几秒钟内。这使得系统能够在高负载时期依然保持快速的响应速度,满足用户对低延迟的需求。
综上所述,Model Hot Swapping 内存交换技术为企业提供了一种智能、高效的模型部署解决方案,成功在性能和成本之间实现了最优平衡。通过动态加载和智能内存管理,企业可以在保持严格服务水平协议(SLAs)的同时,显著降低硬件成本和资源浪费。借助 GPU 内存交换技术,企业能够更智能地部署资源,而非简单地堆叠硬件,从而在满足用户期望的响应速度的同时,实现成本效益的。
Reference :
- [1] https://forums.developer.nvidia.com/
- [2] https://www.run.ai/


















