神经网络在零样本图像分类中取得了惊人的成就,但它们真的能“看”得有多好呢?现有的用于评估这些模型鲁棒性的数据集仅限于网络上的图像或通过耗时且资源密集的手动收集创建的图像。这使得系统评估这些模型在面对未见数据和真实世界条件(包括背景、纹理和材质的变化)时的泛化能力变得困难。一个可行的解决方案是在合成生成的图像上评估模型,例如ImageNet-C、ImageNet-9或Stylized-ImageNet。
然而,这些数据集依赖于特定的合成损坏、背景和纹理;此外,它们的变化有限,缺乏真实的图像质量。

ImageNet-D与其他合成图像数据集的对比示例
这些模型变得如此强大,以至于在这些合成图像数据集中实现了极高的准确性,这也带来了额外的挑战。
ImageNet-D
ImageNet-D是一个通过扩散模型生成的新基准,解决了这些局限性,通过具有挑战性的图像将模型推向极限,并揭示模型鲁棒性的关键缺陷。
- 它由4,835张“困难图像”组成。
- ImageNet-D涵盖了ImageNet和ObjectNet之间的113个重叠类别。
- 该数据集包含547种干扰变化,包括广泛的背景(3,764种)、纹理(498种)和材质(573种),使其比之前的基准更加多样化。通过系统地改变这些因素,ImageNet-D全面评估了模型是否能够真正“看到”图像表面特征之外的内容。
从“真实世界数据的复杂性”转向像ImageNet-D这样的合成数据集可能看起来违反直觉,但它解决了评估神经网络鲁棒性时的关键局限性。
为什么合成数据集具有优势?
- 需要系统性控制:真实世界的数据本质上是不可控的。如果你想测试神经网络对背景、纹理或材质变化的响应,很难系统地创建或找到包含所有所需组合的真实世界数据。
- 合成数据提供控制性和可扩展性:ImageNet-D利用扩散模型生成合成图像,克服了真实世界数据的局限性。这种方法使研究人员能够系统地控制并高效扩展数据集,探索比仅使用真实图像更广泛的变化范围。通过扩散模型,ImageNet-D可以生成比现有数据集更多样化的背景、纹理和材质的图像。
- 专注于“困难”示例:ImageNet-D使用困难图像挖掘过程,选择性地保留导致多个视觉模型失败的图像。通过关注当前模型的弱点,ImageNet-D提供了更具信息量的评估。
- 通过人工验证进行质量控制:虽然是合成的,但ImageNet-D并未牺牲质量。通过严格的质量控制流程,包括人工标注者,确保生成的图像是有效的、单一类别的且高质量的。
扩散模型的图像生成

ImageNet - D 的创建框架
ImageNet-D的创建框架涉及几个关键步骤,利用Stable Diffusion和困难图像挖掘策略。生成过程公式为:Image(C,N) = Stable Diffusion(Prompt(C, N)),其中C是对象类别,N表示背景、材质和纹理等干扰因素。

用于创建合成图像的提示词格式
- 通过在扩散模型的提示词中将每个物体与所有干扰因素进行配对来生成图像,这些干扰因素使用了来自 Broden 数据集的 468 种背景、47 种纹理和 32 种材质。
- 每张图像都以其提示词类别 C 作为分类的真实标签进行标注。
- 如果模型预测的标签与真实标签 C 不匹配,则该图像被视为分类错误。
困难图像挖掘与共享感知失败
ImageNet-D的困难图像挖掘策略旨在识别和选择最具挑战性的图像,以评估神经网络的鲁棒性。其目标是创建一个测试集,将视觉模型推向极限,暴露它们的弱点和失败点。
- 共享感知失败:核心概念是“共享失败”,即当一张图像导致多个模型错误预测对象标签时发生。其原理是,导致不同模型共享失败的图像可能本质上更具挑战性,对评估鲁棒性更具信息量。
- 代理模型:为了识别这些困难图像,使用一组预先建立的视觉模型作为“代理模型”。这些模型充当代理,估计图像对其他潜在未知“目标模型”的难度。
挖掘过程
- 如前文所述,使用扩散模型生成大量合成图像。
- 在生成的图像上运行每个替代模型,并记录其预测结果。
- 找出多个替代模型未能正确预测物体标签的图像。这些图像被标记为潜在的 “难例”。
- ImageNet - D 测试集就是利用这些替代模型的共同错误构建而成。最终的 ImageNet - D 是通过 4 个替代模型的共同错误创建的。
其结果是一个精心设计的过程,通过选择能够暴露多个视觉模型共同弱点的合成图像,来创建一个具有挑战性且信息丰富的基准测试。
质量控制:人工参与
人工参与的组件对于验证ImageNet-D数据集的质量和准确性至关重要,确保图像被正确标注并适合评估神经网络的鲁棒性。
虽然扩散模型和难例图像挖掘能够生成并选择具有挑战性的图像,但人工标注对于完善数据集同样必不可少。人工标注确保 ImageNet - D 图像有效、属于单类别且质量较高。由于 ImageNet - D 包含各种可能不常见的物体和干扰因素组合,标注标准会考虑主要物体的外观和功能。
679 名合格的亚马逊土耳其机器人(Mechanical Turk)工人参与了 1540 项标注任务,在从 ImageNet - D 中抽取的图像上达成了 91.09% 的一致性。工人需要考虑以下问题:
- 你能在图像中识别出目标物体([真实类别])吗?
- 图像中的物体可以用作目标物体([真实类别])吗?
为保持高质量的标注,在每个标注任务中都加入了哨兵样本。这些样本包括:
- 正哨兵样本:明确属于目标类别的图像,且被多个模型正确分类。
- 负哨兵样本:不属于目标类别的图像。
- 一致性哨兵样本:随机重复出现的图像,用于检查工人回答的一致性。
未通过哨兵样本检查的工人回复将被丢弃。
如何使用和解释结果
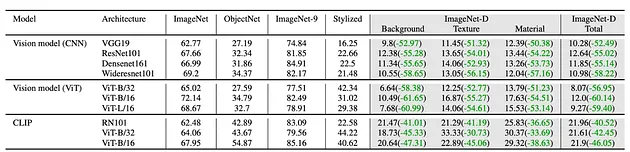
在ImageNet-D上测试模型后,如何解释结果并获取有关模型优势和劣势的宝贵见解?
- 较低的准确性表明缺乏鲁棒性:如果你的模型在ImageNet-D上的表现明显低于ImageNet等标准基准,则表明它在面对背景、纹理和材质变化时难以泛化。这意味着模型可能依赖于表面特征,而不是真正“理解”对象。
- 与其他模型进行比较:单一的准确性分数信息有限。为了评估模型的鲁棒性,将其在ImageNet-D上的表现与其他模型进行比较。这将帮助你了解其相对地位,并突出其表现优异或落后的领域。
- 分析失败案例:不要只看整体准确性,还要分析模型失败的特定图像。是否存在某些背景始终导致错误分类?模型是否容易被不寻常的纹理或材质迷惑?通过分析这些失败案例,你可以识别模型的具体弱点,并针对性地改进。
下一步如果你有兴趣探索该数据集,我已将其解析为FiftyOne格式并上传到Hugging Face。通过几行代码,你可以下载并开始探索数据集。
结论
通过结合扩散模型的合成图像生成、系统性的困难图像挖掘和严格的人工验证,ImageNet-D提供了一个比以往数据集更全面、更具挑战性的基准。
ImageNet-D测试的结果可以揭示模型对视觉概念的真正理解,而不仅仅是表面级别的模式匹配。
随着视觉模型的进步,评估其局限性的可靠方法变得越来越重要。ImageNet-D帮助识别这些局限性,并为开发更鲁棒的模型提供了途径,这些模型能够更好地处理真实世界中的外观、背景和上下文变化。对于计算机视觉的研究人员和从业者来说,ImageNet-D不仅仅是一个基准,它是一个宝贵的工具,用于理解和改进人工神经网络如何“看”和解释视觉世界。
数据集链接:https://github.com/chenshuang-zhang/imagenet_d