近年来,随着大模型的快速发展和广泛应用,其安全问题引发了社会各界的广泛关注。例如,近期发生的「全球首例利用 ChatGPT 策划的恐袭事件」再次敲响了警钟,凸显了大模型安全问题的紧迫性和重要性。
为应对这一挑战,来自中美英德等 8 个国家 25 家高校和科研机构的 44 位 AI 安全领域学者联合发布了一篇系统性技术综述论文。该论文的第一作者是复旦大学马兴军老师,通信作者是复旦大学姜育刚老师,领域内众多知名学者共同参与。

- 论文标题:Safety at Scale: A Comprehensive Survey of Large Model Safety
- 论文地址:https://arxiv.org/abs/2502.05206
- GitHub 主页:https://github.com/xingjunm/Awesome-Large-Model-Safety
这篇综述论文全面调研了近年来大模型安全相关的 390 篇研究工作,并采用简单直接的三级目录结构对内容进行了系统梳理(如图 3 所示):一级目录聚焦模型类型,二级目录区分攻击与防御类型,三级目录细化技术路线。
研究覆盖了视觉基础模型、大语言模型、视觉-语言预训练模型、视觉-语言模型、文生图扩散模型和智能体等 6 种主流大模型,以及对抗攻击、后门攻击、数据投毒、越狱攻击、提示注入、能量延迟攻击、成员推理攻击、模型抽取攻击、数据抽取攻击和智能体攻击等 10 种攻击类型。

论文总结了 4 个重要研究趋势(参考下图 1 和 2):
1. 研究规模显著增长
过去 4 年,大模型安全研究论文数量成倍增长,2024 年相关研究已突破 200 篇,充分体现了学术界和产业界对该领域的高度关注。
2. 攻防研究比例失衡
在现有研究中,约 60% 的工作聚焦于攻击方法,而防御相关研究仅占 40%。这种攻防研究的不平衡状态凸显了当前防御技术的不足,亟需更多资源投入以提升大模型的安全性。
3. 重点攻击目标
大语言模型、文生图扩散模型以及视觉基础模型(包括预训练 ViT 和 SAM)是目前最受攻击者关注的三类模型。这些模型因其广泛的应用场景和高影响力,成为安全研究的核心焦点。
4. 主流攻击类型
对抗攻击、后门和投毒攻击以及越狱攻击是目前被研究最多的三大攻击类型。这些攻击手段因其高成功率和潜在危害性,成为大模型安全领域的主要挑战。
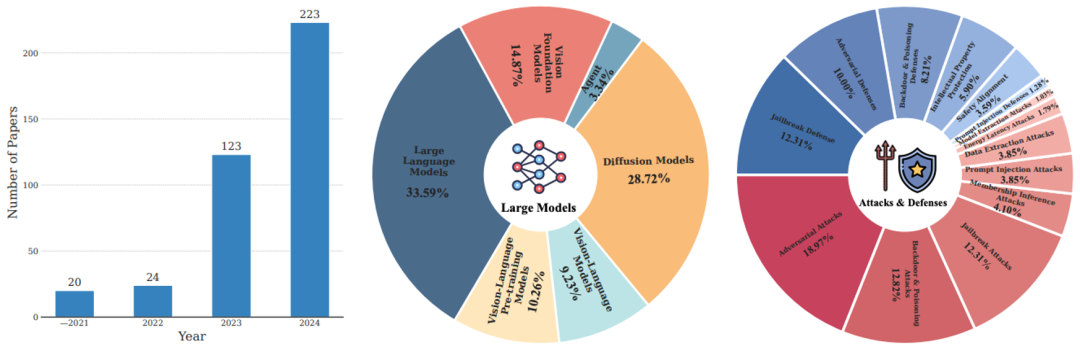
图 1. (左)过去四年发表的大模型安全研究论文数量;(中)各类大模型的研究分布;(右)各类攻击 / 防御的研究分布。

图 2. (左)不同模型上研究论文数量的季度变化趋势;(中)各类大模型与对应攻防研究之间的比例对应关系;(右)各类攻防研究论文年度发表数量的变化趋势(从高到低上下排序)。
除了介绍针对各类模型的攻击与防御方法,论文还归纳了研究常用的数据集和评估基准,为初学者快速了解领域进展和实验设置提供了参考。论文的组织结构清晰,内容详实,不仅为学术界和产业界提供了全面的研究指南,也为未来大模型安全研究指明了方向。
最后,论文总结了大模型安全领域的主要挑战,并呼吁学术界与国际社会协同合作,共同应对这些难题:
1. 根本脆弱性理解不足
领域需要增加对大模型根本脆弱性的理解。比如大语言模型的脆弱性根源是什么,不同模态间的脆弱性是否会相互传播?文生图和文生视频类大模型语言能力的缺乏是否会让它们更难对齐?此外,大模型是否真的会记忆原始训练数据或者以何种方式、多大程度记忆训练数据?
2. 安全评测的局限性
当前评估方法存在显著不足。单一参考攻击成功率无法全面衡量模型安全性,基于静态数据集的基准评测难以应对各类攻击。尽管对抗性评测不可或缺,但在实际环境中,其全面性、准确性和动态性仍需提升。
3. 防御机制亟待加强
现有防御措施存在明显短板,当前防御体系缺乏主动机制和有效检测手段。安全对齐技术并不是万能的,在面对更先进的攻击时仍可被绕过。随着具身智能发展和通用智能的接近,领域亟需更具系统性、实用性和前瞻性的防御方案。
4. 呼吁全球合作
为应对日益多样化的挑战,倡议发展以防御为导向的大模型安全研究,开发更强大的安全防御工具。呼吁模型开源、呼吁商业模型提供专用安全 API、呼吁建立开源安全平台。呼吁全球合作,只有通过学术界、产业界和国际社会的共同努力,才能构建更安全可信的人工智能生态系统。