面对着网络上各种各样关于神经网络的内容,很多想学习神经网络的人都无从下手,包括作者自己;面对各种乱七八糟的概念,名词,很多人都被这些东西蒙住了眼睛。
所以,今天我们就抛开各种高大上的概念,从本质出发来学习什么网络;我们今天不讨论CNN,RNN,Transformer,LSTM等各种神经网络架构;只讨论什么是神经网络。

神经网络
对神经网络有过了解的人应该都知道,神经网络就是仿生学的一种实现,使用的是数学模型模拟人类的大脑神经系统;具体的可以看一下上一篇文章——从一个简单的神经网络模型开始。
所以,什么是神经网络?
由简单神经元构成的系统就是神经网络;可以说一个神经元就是一个最简单的神经网络模型,只不过这个神经网络仅仅只有一层,且只有一个神经元;而由多个神经元组成的多层神经网络系统就是一个复杂的神经网络模型。
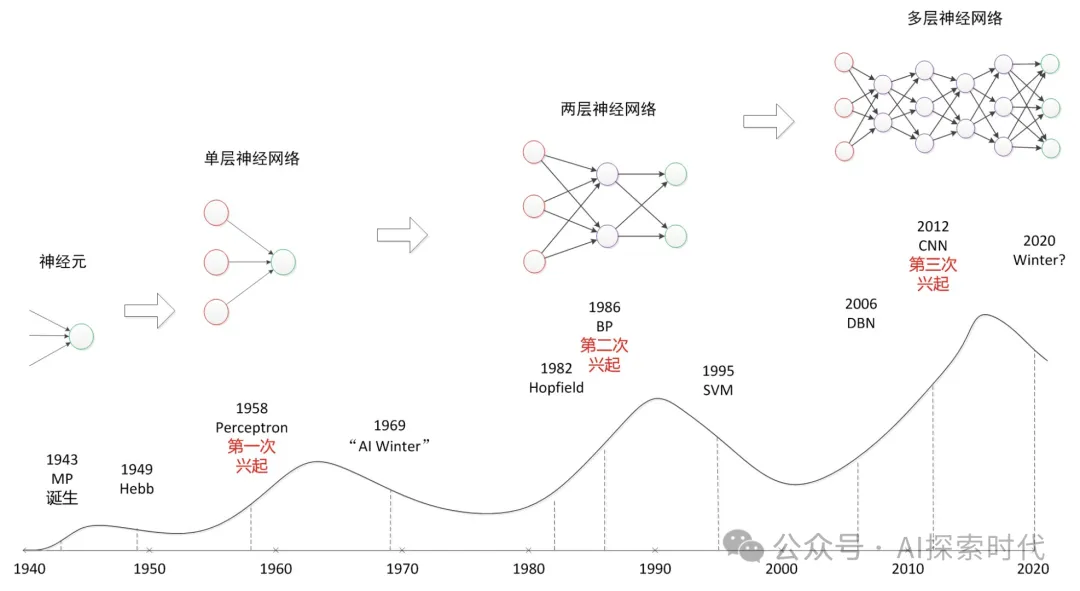
虽然从实际出发,一个神经元的神经网络没什么实际意义;但其却是理解神经网络的基础。
神经网络最基础的形态就是单层神经网络,也被叫做感知器;而二层以上的神经网络叫做多层感知器或深层神经网络。
多层神经网络的形态基本如下所示,根据不同的任务类型可以适当增加更多的中间层。
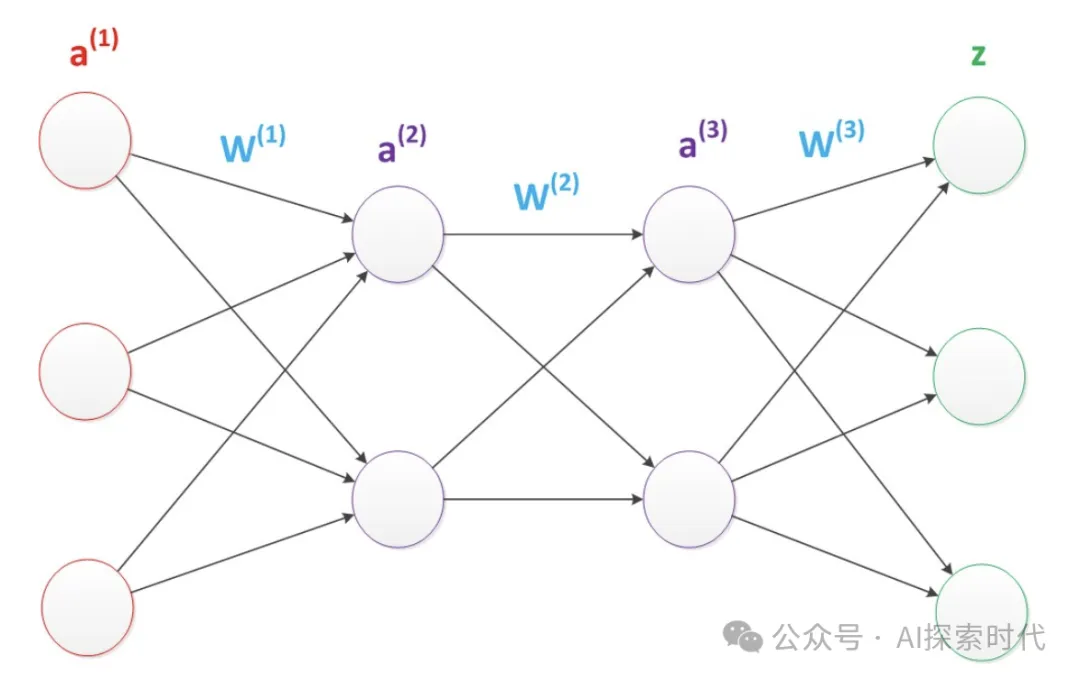
当然这些只是神经网络的理论基础,那么要想实现一个能运行的神经网络,需要哪些必要功能点呢?
事实上,实现一个神经网络大概需要以下几个功能点:
- 数据集准备
- 神经网络设计
- 损失计算
- 优化函数
- 反向传播(BP)算法
数据集准备
不论是自然语言处理(NLP)还是计算机视觉(CV)处理,都离不开训练数据;而由于神经网络中的主要数据类型是向量(矩阵),因此不论是图像,视频,还是文字都需要把数据转化为神经网络能够处理的格式,也就是向量类型。
由此也诞生了一些数据向量化的技术,比如文字处理的词袋模型,one-hot编码等;以及图像向量化的技术。
神经网络设计
以pytorch为例,实现一个神经网络只需要继承nn.Module类即可;而根据不同的任务类型,开发人员可以自己根据需要实现能够完成具体任务的神经网络模型;基础代码如下所示:
import torch.nn
# 自定义神经网络
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
# 用来完成一些初始化功能
def __forward(self, x):
"""
神经网络实现
:param x:
:return:
"""
# 比如实现一个全链接层
x = nn.Linear(x)
# pass损失计算
简单来说损失计算是神经网络自主学习的基础,损失计算的目的就是计算神经网络的输出(预测值)和真实值之间的差值,损失差越大说明神经网络的效果越差。
因此,在神经网络训练中,需要根据损失差来对神经网络的参数进行优化,这也是神经网络训练的本质。
常见的损失计算函数有交叉熵计算,均方误差等。
优化函数
优化函数简单理解就是用来优化神经网络参数的一种方式,由于未经过训练的神经网络参数都是随机的;因此在对神经网络训练时,需要根据损失结果调整神经网络的参数值,以使神经网络达到最好的效果。
模型训练的本质就是不断优化模型参数的过程。
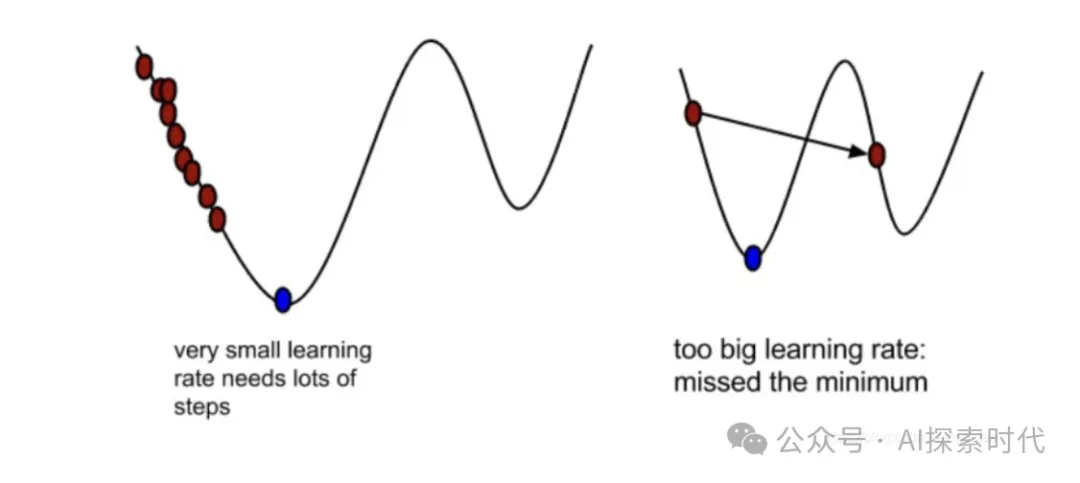
而常见的优化算是就是梯度下降,简单来说就如下图所示,优化算法的最优解就是图中蓝色标识的部分;但对神经网络来说,它并不知道哪里是最优解,因此就需要一个点一个点的试,以求把损失降到最小,而这个过程就叫做梯度下降。
举例来说,假设x的初始值为2,这时它的损失值也就是y=4;这时误差就比较大,因此优化函数就优化一下让x=3,这时损失值y=3;这就说明神经网络的优化函数是有用的。
所以,对梯度下降不了解的可以看之前的文章——神经网络之损失函数与优化函数——梯度下降;简单理解梯度下降就是高中数学中的求导,求变化率最小的点(极值),当然实际应用中的梯度下降要复杂的多。
反向传播
反向传播算法也叫做BP算法,目的是根据结果去调整神经网络的参数值;而具体方式就是通过损失计算和优化函数来实现;通过反向传播来调整模型参数,通过优化函数来优化神经网络的梯度。
如下代码所示就是神经网络的训练基本流程,通过不断循环来使神经网络达到最优。
for idx, (input, target) in enumerate(data_loader):
# 梯度归零 optimizer就是优化函数
optimizer.zero_grad()
output = model(input) # 调用模型 获取预测值
loss = F.nll_loss(output, target) # 得到损失
loss.backward() # 反向传播
optimizer.step() # 更新梯度而由于神经网络的基础数据格式是向量,而表现形式是矩阵;因此神经网络中涉及大量的矩阵运算。以及,神经网络本质上就是一个数学模型,因此,神经网络中也涉及到大量的数学运算,如求和,平方,求导等等。
而这就是实现一个基础神经网络所需要的基本步骤,而哪些类似于RNN,CNN,Transformer等神经网络架构的神经网络模型;只是在基础神经网络的基础之上,为解决具体问题以及和具体的应用领域相结合,而专门设计和优化的模型。
简单理解RNN,CNN,Transformer模型就是在神经网络的基础之上,如损失计算,优化等;做了一些骚操作,这些操作能够更好的处理自然语言,图像等问题。
从哲学的角度来说就是,一般和特殊的关系;普通的神经网络就是一般的神经网络,而RNN,CNN等就是特殊的神经网络。比如,Transformer神经网络架构就是用来处理序列到序列到任务。