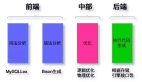
在 MySQL 中,数据排序主要通过 ORDER BY 子句来实现。MySQL 使用多种优化技术和算法来高效地执行排序操作,具体实现取决于查询的复杂性、表的大小、可用的索引以及系统资源。这篇文章,我们来聊一聊 MySQL 几种常见的数据排序方式及其实现细节。

1. 使用索引优化排序
(1) 索引覆盖排序
当查询中包含 ORDER BY 和 WHERE 子句,并且排序的列已经被适当的索引覆盖时,MySQL 可以利用索引的顺序来避免额外的排序操作。这种情况下,数据可以直接按索引顺序检索,无需额外的排序步骤,从而提高查询效率。
示例:
如果在 employees 表的 last_name 和 first_name 上有复合索引,MySQL 会直接使用该索引来返回排序后的结果。
(2) 索引扫描顺序
当 ORDER BY 使用的列已经有索引,且查询的其他条件允许按索引顺序扫描数据,MySQL 可以避免额外的排序操作。例如,使用 PRIMARY KEY 或 UNIQUE 索引进行排序。
2. 内部排序算法
当无法通过索引优化排序时,MySQL 会使用内部排序算法。具体算法可能因 MySQL 的版本和存储引擎的不同而有所变化,常见的包括:
(1) 快速排序(Quick Sort)
一种高效的分治排序算法,适用于大多数情况下的快速排序需求。
(2) 合并排序(Merge Sort)
特别适用于对已经部分排序的数据进行处理,或需要稳定排序时使用。
(3) 针对特定情况的优化
MySQL 可能根据数据的特性选择最合适的排序算法,以提高性能。
3. 临时文件与内存排序
(1) 内存排序
MySQL 尽可能将在内存中完成排序操作以提高性能。sort_buffer_size 参数控制分配给每个连接的排序缓冲区大小。如果排序所需的内存小于 sort_buffer_size,则排序在内存中完成。
(2) 临时文件排序
如果排序所需的内存超过 sort_buffer_size,MySQL 会将部分数据写入磁盘上的临时文件(通常在 /tmp 目录下),然后在磁盘上完成排序。这会增加额外的 I/O 操作,影响性能。
4. 并行排序
在支持多线程的 MySQL 版本和适当的配置下,排序操作可以并行化处理,以利用多核 CPU 的优势,提高排序效率。
5. 查询优化与执行计划
MySQL 的查询优化器会在执行查询前生成一个最优的执行计划,决定是否使用索引进行排序,或者选择内部排序算法。优化器会评估查询的成本,包括排序所需的资源和时间,选择最有效的排序方式。
示例:使用 EXPLAIN 分析排序
通过 EXPLAIN 命令,可以查看查询执行计划,了解是否使用了索引进行排序。
输出结果中,如果 Using filesort 出现在 Extra 列中,表示 MySQL 使用了内部排序算法而未能利用索引优化排序。反之,则可能利用了索引。
6. 限制排序范围(LIMIT 子句的优化)
在带有 LIMIT 的排序查询中,MySQL 可以优化排序操作,只排序需要的记录数量,而不是整个结果集,从而减少排序所需的资源和时间。
示例:
MySQL 可以通过优先查找最近雇佣的 10 名员工,减少排序的工作量。
7. 其他优化技术
(1) 多列排序
对多列进行排序时,MySQL 会根据查询中指定的列顺序依次进行排序,优先排序前面的列,再排序后面的列。
(2) 字符集与排序规则
不同的字符集和排序规则(collation)可能影响排序的行为和性能。某些字符集可能需要更多的计算资源来比较和排序字符串。
8. 总结
本文,我们分析了 MySQL中几种常见的数据排序方式及其实现细节, MySQL在实现数据排序时,会综合利用索引优化、内存与临时文件排序、并行处理以及查询优化等多种技术和算法,为不同的使用场景提供高效、可靠的排序能力。
为了优化排序性能,我们通常建议:
- 适当为 ORDER BY 使用的列创建索引。
- 调整 sort_buffer_size 以适应排序需求。
- 通过分析执行计划(使用 EXPLAIN)了解查询的排序行为,并进行必要的优化。