












直观上,我们如何预测图像中的边界框?第一个最明显的技术是滑动窗口。我们定义一个任意大小的窗口,并在图像中“滑动”它。在每一步中,我们分类窗口是否包含我们感兴趣的对象。这就是我们所想的,对吧?那么,锚框将是它的“深度学习”版本。它更快,也更精确。
我们不只是滑动一个窗口,而是同时滑动一组不同大小和形状的窗口。有些是小的用于小物体,有些是大的用于大物体,有些是高而瘦的用于人,有些是短而宽的用于公交车。

这些预定义的“窗口”就是锚框。它们就像你放在图像上的一堆模板。我们不需要到处搜索;我们只需检查每个模板(锚框)是否适合(或接近适合)一个物体。然后,我们的模型学会调整这些模板(锚框)以完美匹配它找到的物体。
一、定义
锚框是预定义的各种大小和宽高比的边界框,作为目标检测的参考点。模型不是从头开始预测框,而是调整这些锚框以更好地适应实际物体,从而提高检测的准确性和效率。
1. 锚框与边界框
首先,我们取一个锚框,并系统地将其放置在整个图像上,类似于滑动窗口方法。

然而,注意到这些锚框中没有一个完美匹配图像中的实际物体。由于我们只使用一种形状和大小的锚框,它无法捕捉到不同尺寸和宽高比的物体。因此,仅靠这种方法不足以进行准确的目标检测。
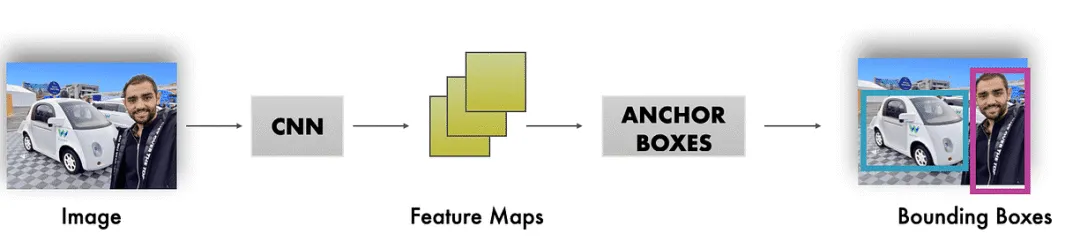
架构看起来更像这样;锚框应用于特征图,然后它们被细化为边界框
2. 关于锚框
- 锚框应用于特征图,而不是直接应用于图像。
- 锚框帮助生成边界框,但它们本身不是最终的边界框。
二、什么是特征图?
特征图是由卷积神经网络(CNN)创建的图像的处理版本。它们在不同细节层次上捕捉重要模式,如边缘、纹理和物体形状。锚框不是放置在原始图像上,而是放置在特征图上,使模型能够更有效地进行预测。
三、为什么锚框应用于特征图而不是图像?
1. 计算效率
将锚框直接应用于图像意味着在每个可能的位置放置数千甚至数百万个锚框,导致巨大的计算成本。
相反,特征图比原始图像小得多,因为卷积层在下采样图像的同时保留了重要信息。
示例:
- 假设我们有一个512×512的图像。在每个像素上放置锚框意味着评估262,144个位置(512×512)。
- 如果特征图下采样到32×32,我们现在只需要评估1,024个位置,使计算速度提高256倍。
2. 更丰富的特征表示
特征图包含由CNN提取的高级信息,如边缘、纹理和物体部分,这有助于更准确地检测物体。
如果我们将锚框直接放置在原始图像上,它们将仅依赖于像素强度,这缺乏目标检测所需的更深层次理解。
3. 尺度不变性(有效检测小和大物体)
目标检测中的一个巨大挑战是物体有不同的尺寸。有些物体可能小而远,而有些物体可能大而近。如果我们将锚框直接放置在图像上,它们将具有相同的尺度,使得检测不同尺寸的物体变得困难。如果我们将锚框直接放置在图像上,它们将具有固定的大小,并且不会调整以适应不同物体的大小。
示例:
想象我们正在尝试检测图像中的汽车:
- 远处的小汽车可能是30×30像素。
- 靠近摄像头的大汽车可能是300×300像素。
如果我们只使用一个固定大小的锚框(例如100×100像素),它将无法正确匹配小汽车和大汽车:
- 100×100的框对于小汽车来说太大,可能包括背景。
- 100×100的框对于大汽车来说太小,无法覆盖整个物体。
当图像通过CNN时,它会在不同层次创建多个特征图:
- 早期层捕捉小细节(例如边缘、角落)。
- 深层捕捉更大的模式(例如物体的形状)。
通过在特征图上放置锚框,模型可以自动调整以检测:
- 使用精细特征图(早期层)检测小物体
- 使用抽象特征图(深层)检测大物体
(1) 早期层 — 检测小物体
- CNN的早期层捕捉精细细节,如边缘、纹理和小模式。
- 这些层保留了更多的空间信息(即图像的精细细节)。
- 因此,它们擅长检测小物体。
- 小锚框放置在这些层上以检测图像中的小物体。
示例:
想象我们正在检测图像中的汽车。远处的小汽车可能只有30×30像素。
- CNN的早期层仍然具有高分辨率,这意味着像这样的小汽车仍然可以被检测到。
- 在这一层使用一个小锚框(例如16×16像素)以匹配物体大小。
(2) 深层 — 检测大物体
- 随着图像深入CNN,特征图变得更小,但它们代表更复杂的特征(如物体的整体形状而不是精细细节)。
- 由于这些层看到更大的模式,它们更擅长检测大物体。
- 较大的锚框放置在这些深层以检测大物体。
示例:
前景中的大汽车可能是300×300像素。
- CNN的深层将有一个较小的特征图,代表大尺度模式。
- 在这一层使用一个大锚框(例如128×128或256×256像素)以检测较大的物体。
(3) 多尺度锚框 — 覆盖所有尺寸
我们不在特征图的不同层上只使用一种大小的锚框,而是应用多种大小的锚框。这样,我们可以在同一图像中检测小物体和大物体。
多尺度锚框示例:
在CNN的不同层,我们可能放置以下大小的锚框:
- 16×16像素用于小物体
- 32×32像素用于中等大小的物体
- 128×128像素用于大物体
(4) 两阶段检测器中的更快区域提议
在像Faster R-CNN这样的模型中,区域提议网络(RPN)仅在特征图上应用锚框,生成较少但高质量的对象提议。
这减少了在后续阶段需要进一步细化的区域数量,提高了速度和效率。
示例:
不是在原始图像中评估100,000个可能区域,RPN可能会从特征图生成2,000个高置信度的提议,从而加速检测流程。
四、锚框是如何生成的?
虽然锚框应用于特征图,但我们仍然需要决定它们的形状、大小和宽高比。关键问题包括:
- 所有锚框都应该是垂直矩形,还是应该有一些是正方形?
- 最小和最大的锚框大小应该是什么?
- 我们如何确保检测到小而远的物体和大而近的物体?
为了捕捉不同尺度和形状的物体,我们使用一组多样化的锚框。这些框需要仔细选择以与数据集中常见的物体对齐。
五、如何选择锚框?
选择锚框涉及手动设计和数据驱动优化的结合:
手动选择:
- 基于数据集中物体的先验知识,我们定义一些常见的锚框形状和大小。
- 例如,如果检测行人,我们可能会使用高而窄的框。如果检测汽车,我们可能会使用更宽的框。
使用K-Means聚类:
- 我们不是手动选择所有锚框,而是可以使用K-Means等聚类算法分析数据集。
- 该算法将相似形状和大小的物体分组,帮助我们找到最常见的边界框尺寸。
- 通过选择K个锚框模板,我们确保模型在不同物体大小上表现良好。
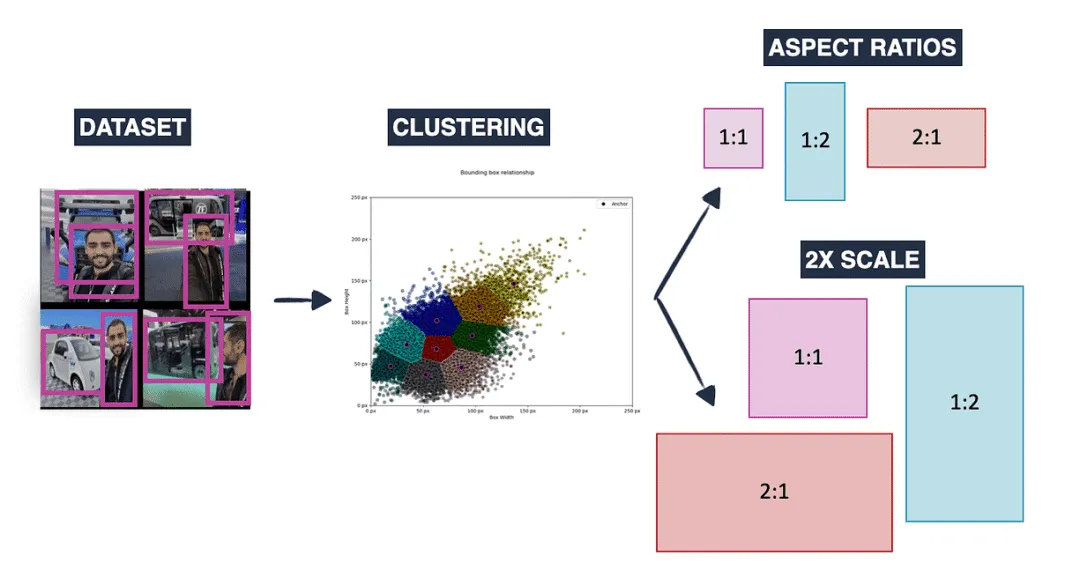
六、在目标检测中生成锚框
一旦确定了锚框的大小和宽高比,我们生成多个不同大小和变化的锚框。这些变化包括:
- 不同大小(例如(16,32), (32,32), (32,16))
- 不同宽高比(例如1:1, 1:2, 2:1)
- 不同尺度(例如1x, 2x, 3x),这些尺度放大或缩小框
这导致了一组大量的锚框,确保可以有效地检测各种形状和大小的物体。
七、在推理过程中如何生成锚框?
生成锚框的确切方法取决于所使用的目标检测算法。
示例:Faster R-CNN和区域提议网络(RPN)的作用
在Faster R-CNN中,区域提议网络(RPN)负责生成潜在的对象位置。
RPN如何与锚框一起工作:
(1) 特征提取
- 输入图像通过卷积神经网络(CNN)提取特征图。
(2) 将锚框应用于特征图区域
- 在特征图的每个位置上,放置多个不同大小和宽高比的锚框。
- 这些锚框作为检测对象的起点。
(3) 锚框细化(回归+分类)
- RPN预测调整(回归)以细化锚框,使其与实际对象对齐。
- 它还分类每个锚框是否包含对象。
- 只有最有希望的框(称为区域提议)被传递到下一步。
八、锚框变化示例
假设我们定义了一个16×16大小的锚框,并应用:
- 两种宽高比:1:1, 1:2, 和2:1
- 两种尺度:1x和2x
这导致每个区域有6个锚框:
- 16×16 → 1:1比例的方形框,尺度1
- 16×32 → 1:2比例的高框,尺度1
- 32×16 → 2:1比例的宽框,尺度1
- 32×32 → 1:1比例的方形框,尺度2
- 32×64 → 1:2比例的高框,尺度2
- 64×32 → 2:1比例的宽框,尺度2
这确保我们覆盖多种物体形状(方形、宽、高)和多种物体大小(小到大)。
- 小物体(例如32×32)
- 中等物体(例如128×128)
- 大物体(例如512×512)
通过使用多样化的锚框,模型可以准确检测小而远的物体和大而近的物体。
九、从锚框到边界框
锚框不是最终的边界框;它们只是预定义的参考形状,用于帮助模型预测实际物体位置。为了将锚框转换为最终的边界框,模型根据图像中的物体调整(或“回归”)它们。让我们通过一个示例逐步分解这个过程。
步骤1:在特征图上生成锚框
- 图像首先通过CNN传递,提取不同层的特征图。
- 在每个特征图上,每个空间位置放置多个不同大小和宽高比的锚框。
- 每个锚框作为物体可能位置的起点。
示例:
假设我们有一个10×10的特征图,在每个位置上放置3个不同大小的锚框:
- 小框:32×32像素
- 中框:64×64像素
- 大框:128×128像素
由于我们有100个空间位置(10×10特征图)和每个位置3个锚框,我们最终得到300个锚框。
步骤2:预测物体得分
评估每个锚框以确定是否包含物体。
- 分类头为每个锚框分配一个概率得分。
- 如果得分高,意味着框可能包含物体。
- 如果得分低,则忽略。
示例:
- 模型预测在特征图(5,5)位置的64×64锚框有80%的概率包含汽车。
- 该位置的其他锚框被忽略,因为它们的概率较低。
步骤3:调整锚框(边界框回归)
即使锚框接近物体,它也可能没有完美对齐。因此,模型调整(或“回归”)锚框坐标以更好地适应物体。
模型为每个锚框预测四个调整(偏移):
- Δx — 水平移动中心的距离。
- Δy — 垂直移动中心的距离。
- Δw — 调整宽度的距离。
- Δh — 调整高度的距离。
新的边界框坐标计算如下:
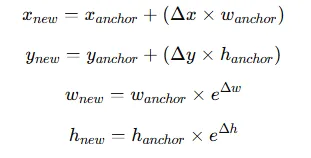
示例:
- 原始锚框在(5,5)位置,大小为64×64像素。
- 模型预测Δx = 0.1, Δy = -0.2, Δw = 0.05, Δh = -0.1。
- 应用这些调整后,锚框稍微移动并调整大小以更准确地匹配汽车。
步骤4:去除冗余框(非最大抑制)
许多锚框可能会预测同一个物体,略有变化。
模型应用非最大抑制(NMS)去除冗余框,只保留最好的一个。
选择置信度最高的边界框。
示例:
- 有5个重叠的边界框围绕汽车,具有不同的置信度得分(80%, 75%, 60%等)。
- 模型保留置信度最高的框,去除其他框。
最终结果
经过所有这些步骤,我们得到一个最终边界框,紧密地围绕检测到的物体。
示例总结:
- 在特征图上放置了一个64×64的锚框。
- 模型以80%的置信度检测到一辆汽车。
- 模型调整了锚框以正确匹配汽车。
- 使用非最大抑制(NMS)去除了其他重叠框。
- 最终的边界框准确地围绕图像中的汽车。
【参考资料】
终于理解目标检测中的锚框(2D和3D):https://www.thinkautonomous.ai/blog/anchor-boxes/




























