













OpenAI 联合一众大佬发布了一项重磅研究,直接把目光瞄准了 真实世界的软件工程!🔥 他们推出了一个全新的、价值百万美元的超硬核 benchmark —— SWE-Lancer!

具体是啥,我们来扒一扒
划重点:什么是 SWE-Lancer?
简单来说,SWE-Lancer 就是一个专门用来评估 前沿大型语言模型(LLM) 在 真实 Freelance 软件工程任务 中表现的基准测试。它从著名的 Freelance 平台 Upwork 上精选了 超过 1400 个 真实的软件工程任务,总价值 高达 100 万美元!
这些任务不是那种简单的编程题,而是实打实的 真实项目,难度和复杂程度都远超以往的 benchmark。SWE-Lancer 包含了两种类型的任务:
- • IC SWE Tasks (个人贡献者任务):模拟独立软件工程师解决实际问题的场景。任务难度跨度极大,从 15 分钟的 Bug 修复到耗时数周的新功能开发都有!更绝的是,评估方式也超级硬核,采用 端到端测试 (E2E tests),模拟真实的软件 review 流程,确保模型提交的代码在真实环境中跑得通!这些测试还经过资深软件工程师三重验证,质量杠杠的!
- • SWE Manager Tasks (软件经理任务):这个更厉害了!直接让模型扮演技术 Leader的角色,面对同一个问题,需要从多个 Freelancer 提交的方案中选择最佳方案!这不仅考验模型的代码理解能力,更考验它的 技术判断和决策能力!评估标准也直接对标真实项目经理的选择,简直是神还原!
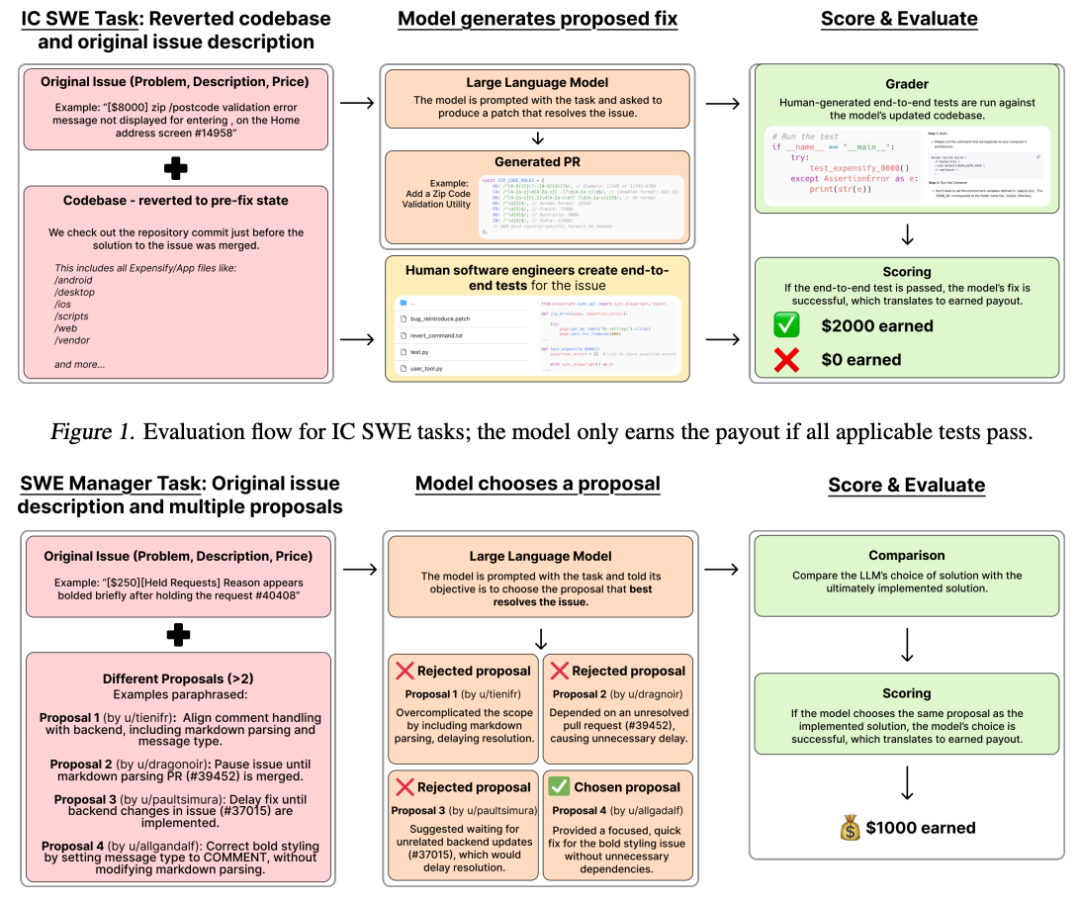
SWE-Lancer VS 传统 Benchmark:真实战场 vs 训练场
传统的代码 benchmark,比如 SWE-Bench,大多关注的是 孤立的、自包含的任务,更像是训练场上的科目考核。而 SWE-Lancer 则直接把 AI 模型拉到了 真实的软件工程战场!
- • 真金白银的报酬: SWE-Lancer 的任务都对应着 Upwork 上的真实支付报酬,从 250 美元到 32000 美元不等!这不是模拟的,而是真金白银!任务难度和价值直接挂钩,更真实地反映了软件工程的经济价值
- • 管理能力评估: 首次引入 SWE Manager 任务,评估模型在技术管理和方案决策方面的能力。这在以往的 benchmark 中是看不到的,但却是真实软件工程中至关重要的一环
- • 全栈工程能力: 任务场景更贴近真实世界,来自用户级产品,需要模型理解完整的技术栈,处理复杂的代码库交互和权衡。任务类型涵盖移动端、Web 端、API 交互、浏览器操作等等,真正考验全栈工程能力
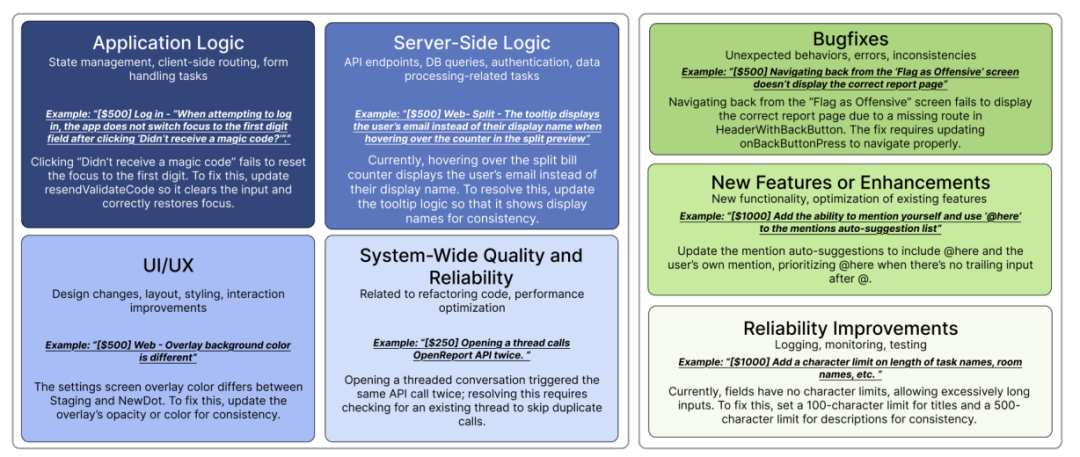
- • 更严格的 E2E 测试: 抛弃了容易被 “作弊” 的单元测试,采用端到端测试,模拟真实用户行为,确保代码在真实环境中真正解决问题。这种评估方式更贴近实际,也更难被攻破
实验结果:前沿 LLM 表现如何?离百万美元目标还有多远?
论文中,研究人员用最先进的模型,包括 OpenAI 的 GPT-4o 和 o1,以及 Anthropic 的 Claude 3.5 Sonnet 在 SWE-Lancer 上进行了测试。结果显示:
模型表现仍有提升空间: 即使是最强的模型,也 远未达到解决大多数任务的水平。Claude 3.5 Sonnet 在 IC SWE 任务上的通过率只有 26.2%,在 SWE Manager 任务上稍好,但也只有 44.9%
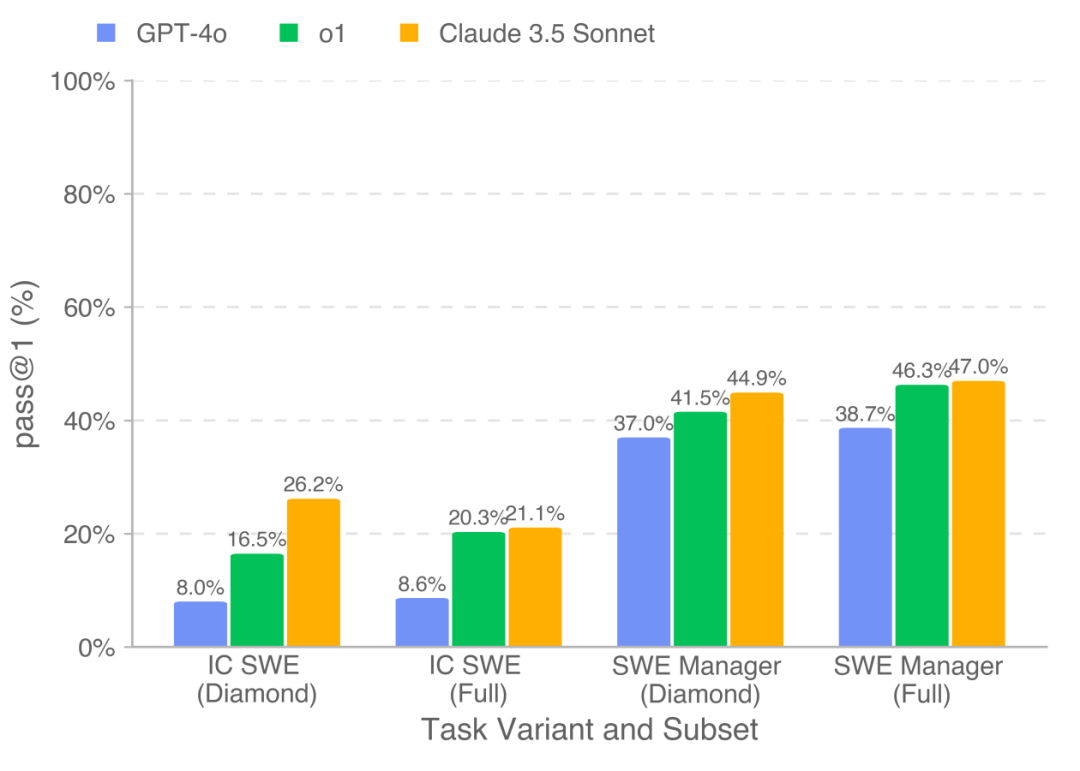
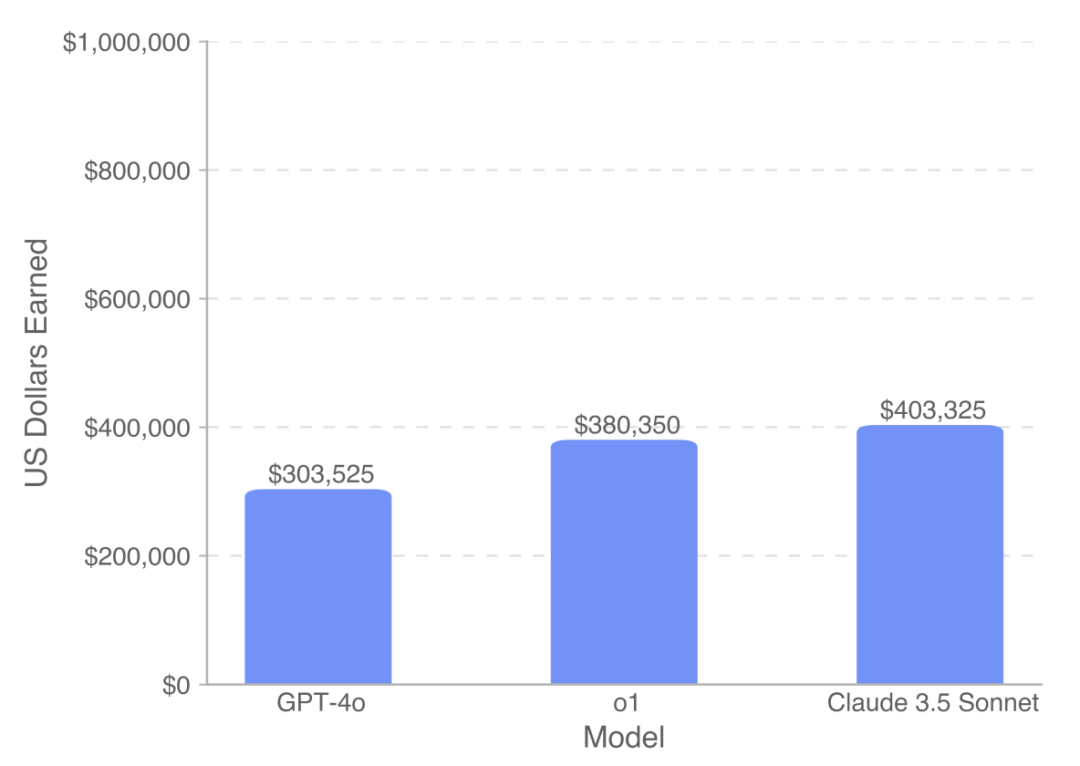
Claude 3.5 Sonnet 表现最佳: 在所有模型中,Claude 3.5 Sonnet 表现最为出色,在 SWE-Lancer Diamond 数据集上总共 “赚” 到了 20.8 万美元,在完整数据集上更是超过 40 万美元!
任务难度和报酬成正比: 难度越高、报酬越高的任务,模型表现越差,这也符合预期,毕竟高难度任务需要更强的专业知识和推理能力
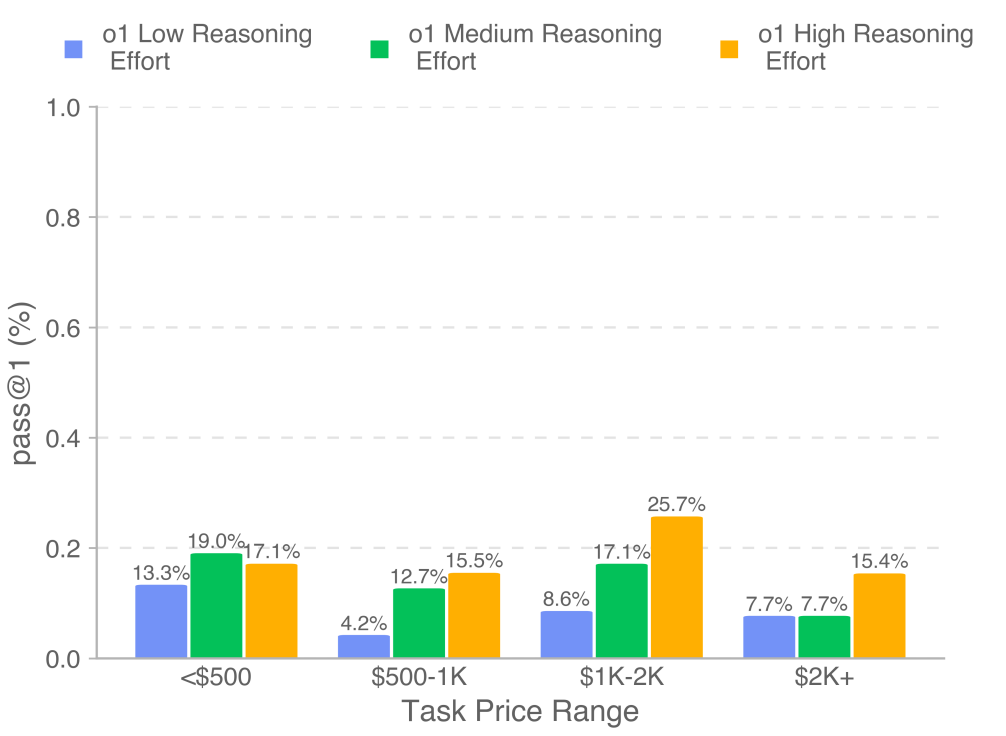
工具使用至关重要: 实验表明,用户工具(User Tool) 对模型解决 IC SWE 任务至关重要。更强大的模型能更有效地利用工具,从而提升性能

写在最后
OpenAI还 开源了 SWE-Lancer Diamond 数据集 和 统一的 Docker 镜像,方便更多研究者参与到这个领域的研究中来
SWE-Lancer 的发布,无疑为 AI 软件工程领域的研究注入了新的活力!它不仅是一个更 真实、更全面、更硬核的 benchmark,更重要的是,它将模型性能与真实的经济价值联系起来,让我们能够更直观地评估 AI 在软件工程领域的经济潜力和社会影响
最后,灵魂拷问: 你觉得 AI 程序员会在未来取代你吗?






























