













DeepSeek 新论文来了!相关消息刚刚发布到 𝕏 就吸引了大量用户点赞、转发、评论三连。
据介绍,DeepSeek 的这篇新论文提出了一种新的注意力机制 ——NSA。这是一个用于超快长上下文训练和推断的本地可训练的稀疏注意力机制,并且还具有与硬件对齐的特点。

新研究发布两个小时,就有近三十万的浏览量。现在看来,DeepSeek 发布成果,比 OpenAI 关注度都高。

论文标题:Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention
论文链接:https://arxiv.org/abs/2502.11089
值得一提的是,幻方科技、DeepSeek 创始人梁文锋也是论文的作者之一。这成了众多网友讨论的话题。

接下来,让我们看下梁文锋亲自参与的研究,讲了什么内容。
论文概览
长上下文建模是下一代大型语言模型(LLM)的关键能力,这一需求源于多样化的实际应用,包括深度推理、仓库级代码生成以及多轮自动智能体系统等。
最近大模型的突破 —— 如 OpenAI 的 o 系列模型、DeepSeek-R1 和 Gemini 1.5 Pro—— 已经能使得模型能够处理整个代码库、长文档、在数千个 token 上保持连贯的多轮对话,并在长距离依赖关系中进行复杂推理。然而,随着序列长度的增加,普通注意力机制的高复杂性成为关键的延迟瓶颈。理论估计表明,在使用 softmax 架构进行 64k 长度上下文的解码时,注意力计算占总延迟的 70-80%,这凸显了对更高效注意力机制的迫切需求。
实现高效长上下文建模的自然方法是利用 softmax 注意力的固有稀疏性,通过选择性计算关键 query-key 对,可以显著减少计算开销,同时保持性能。最近这一路线的进展包括多种策略:KV 缓存淘汰方法、块状 KV 缓存选择方法以及基于采样、聚类或哈希的选择方法。尽管这些策略前景广阔,现有的稀疏注意力方法在实际部署中往往表现不佳。许多方法未能实现与其理论增益相媲美的加速;此外,大多数方法主要关注推理阶段,缺乏有效的训练时支持以充分利用注意力的稀疏模式。
为了克服这些限制,部署有效的稀疏注意力必须应对两个关键挑战:
1、硬件对齐的推理加速:将理论计算减少转化为实际速度提升,需要在预填充和解码阶段设计硬件友好的算法,以缓解内存访问和硬件调度瓶颈;
2、训练感知的算法设计:通过可训练的操作符实现端到端计算,以降低训练成本,同时保持模型性能。
这些要求对于实际应用实现快速长上下文推理或训练至关重要。在考虑这两方面时,现有方法仍显不足。
为了实现更有效和高效的稀疏注意力,DeepSeek 研究人员提出了一种原生可训练的稀疏注意力架构 NSA,它集成了分层 token 建模。
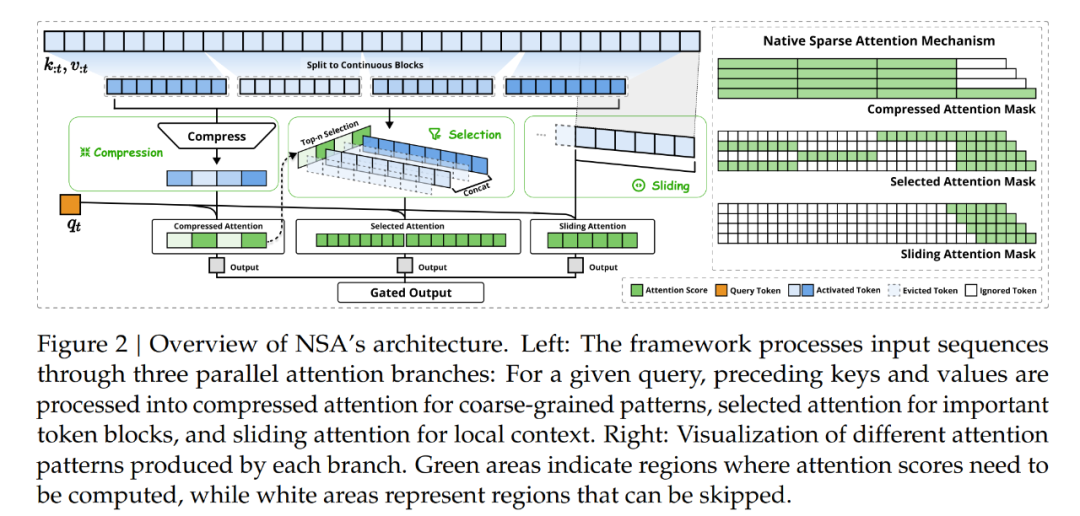
如图 2 所示,NSA 通过将键和值组织成时间块(temporal blocks)并通过三条注意力路径处理它们来减少每查询计算量:压缩的粗粒度 token、选择性保留的细粒度 token 以及用于局部上下文信息的滑动窗口。随后,作者实现了专门的核以最大化其实际效率。
NSA 引入了两个核心创新以对应于上述关键需求:
1、硬件对齐的系统:优化块状稀疏注意力以利用 Tensor Core 和内存访问,确保算术强度平衡;
2、训练感知的设计:通过高效算法和反向操作符实现稳定的端到端训练。这一优化使 NSA 能够支持高效部署和端到端训练。
研究通过对现实世界语言语料库的综合实验来评估 NSA。在具有 260B token 的 27B 参数 Transformer 骨干上进行预训练,作者评估了 NSA 在通用语言评估、长上下文评估和链式推理评估中的表现。作者还进一步比较了在 A100 GPU 上内核速度与优化 Triton 实现的比较。实验结果表明,NSA 实现了与 Full Attention 基线相当或更优的性能,同时优于现有的稀疏注意力方法。
此外,与 Full Attention 相比,NSA 在解码、前向和后向阶段提供了明显的加速,且加速比随着序列长度的增加而增加。这些结果验证了分层稀疏注意力设计有效地平衡了模型能力和计算效率。
方法概览
本文的技术方法涵盖算法设计和内核优化。作者首先介绍了方法背景,然后介绍了 NSA 的总体框架以及关键算法组件,最后详细介绍了针对硬件优化的内核设计,以最大限度地提高实际效率。
背景
注意力机制在语言建模中被广泛使用,其中每个查询 token q_𝑡计算与所有前面键 k_:𝑡的相关性分数,以生成值 v_:𝑡的加权和。从形式上来说,对于长度为𝑡的输入序列,注意力操作定义如下:

其中 Attn 表示注意力函数。
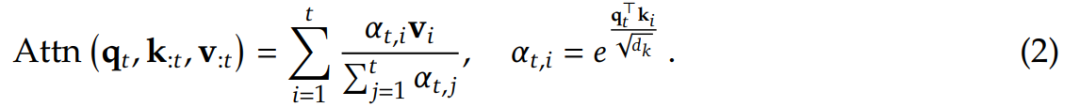
这里,𝛼_𝑡,𝑖 表示 q_𝑡 和 k_𝑖 之间的注意力权重,𝑑_𝑘是键的特征维度。随着序列长度的增加,注意力计算在总计算成本中变得越来越占主导地位,对长上下文处理提出了重大挑战。
算术强度(Arithmetic Intensity)是计算操作与内存访问的比率,本质上决定了硬件的算法优化。每个 GPU 都有一个由其峰值计算能力和内存带宽决定的临界算术强度,以这两个硬件限制的比率计算。对于计算任务,高于此临界阈值的算术强度将构成计算限制(受限于 GPU FLOPS),而低于此阈值的算术强度将构成内存限制(受限于内存带宽)。
具体来说,对于因果自注意力机制,在训练和预填充阶段,批量矩阵乘法和注意力计算表现出高算术强度,使得这些阶段在现代加速器上计算受限。相反,自回归解码会受到内存带宽的限制,因为它每次前向传递都会生成一个 token,同时需要加载整个键值缓存,从而导致算术强度较低。这样就出现了不同的优化目标,即减少训练和预填充期间的计算成本,同时减少解码期间的内存访问。
总体框架
为了充分利用具有自然稀疏模式的注意力机制的潜力,作者提出将 (1) 式中原始的键 - 值对替换成更加紧凑和信息密集的表征键 - 值对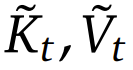 。具体而言,可将优化的注意力输出的形式定义成:
。具体而言,可将优化的注意力输出的形式定义成:
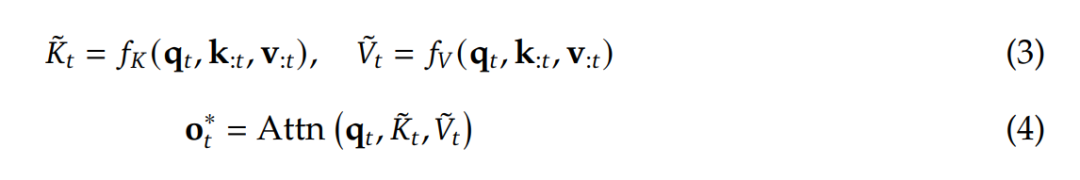
其中 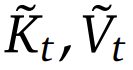 是基于当前查询 q_𝑡 和上下文记忆 k_:𝑡 , v_:𝑡 动态构建的。通过设计不同的映射策略,可以得到
是基于当前查询 q_𝑡 和上下文记忆 k_:𝑡 , v_:𝑡 动态构建的。通过设计不同的映射策略,可以得到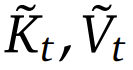 的不同类别,然后可将它们按以下方式组合起来
的不同类别,然后可将它们按以下方式组合起来

如图 2 所示,NSA 有三种映射策略 C = {cmp, slc, win},分别表示键和值的压缩、选取和滑动窗口。𝑔^𝑐_𝑡 ∈ [0, 1] 是对应于策略 c 的门控分数,可通过 MLP 和 sigmoid 激活从输入特征中得出。令 𝑁_𝑡 表示重新映射的键 / 值的总数

通过使 𝑁_𝑡 ≪ 𝑡,可保持较高的稀疏率。
接下来,DeepSeek 还介绍了重新映射策略的具体设计,涵盖 token 压缩、token 选取和滑动窗口。详细的算法设计见原论文。下面来看看 NSA 为何具有 FlashAttention 相当的速度。
核设计
为了在训练和预填充期间实现 FlashAttention 级别的加速,作者基于 Triton 实现了硬件对齐的稀疏注意力内核。
由于多头注意力(MHA)会占用大量内存且解码效率低下,因此该团队选择专注于遵循 SOTA LLM 的共享 KV 缓存架构,如 GQA 和 MQA。
虽然压缩和滑动窗口注意计算与现有的 FlashAttention-2 内核很容易兼容,但他们却引入了专门用于稀疏选择注意的内核设计。如果这时候遵循 FlashAttention 的做法,将时间连续的查询块加载到 SRAM 中,则会导致内存访问效率低下,因为块内的查询可能需要不相交的 KV 块。
为了解决这个问题,这里的关键优化在于不同的查询分组策略:对于查询序列上的每个位置,将 GQA 组内的所有查询头(它们共享相同的稀疏 KV 块)加载到 SRAM 中。图 3 说明了其前向传递实现。

该设计能够 (1) 通过分组共享消除冗余的 KV 传输,以及 (2) 跨 GPU 流式多处理器平衡计算工作负载,由此实现了近乎最佳的算术强度。
NSA 的实验表现
作者从三个角度对新提出的 NSA 进行了评估:一般基准性能、长上下文基准性能和思维链推理性能。
一般基准性能
该团队在大量基准上对比了 NSA 与 Full Attention 的表现。结果见下表 1。
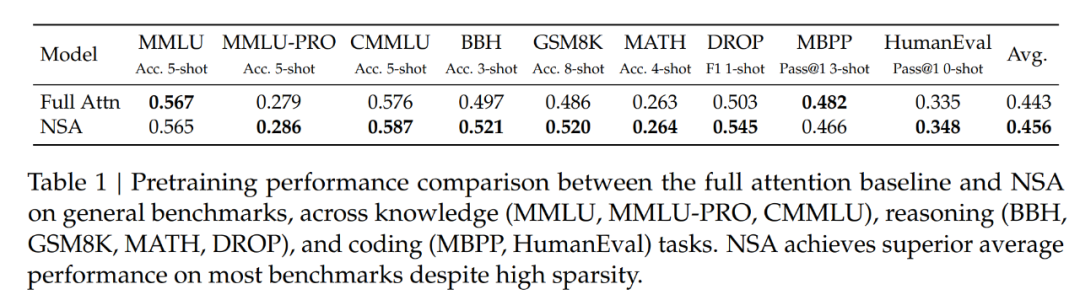
可以看到,尽管 NSA 比较稀疏,但它实现了卓越的整体性能,在 9 个指标中的 7 个上都优于包括 Full Attention 在内的所有基线。
这表明,尽管 NSA 可能无法充分利用其在较短序列上的效率优势,但它依然表现出了强劲的性能。值得注意的是,NSA 在推理相关基准测试中表现出了显著的提升(DROP:+0.042,GSM8K:+0.034),这表明 DeepSeek 的预训练有助于模型发展出专门的注意力机制。通过过滤掉不相关的注意力路径中的噪音,这种稀疏注意力预训练机制可迫使模型专注于最重要的信息,有可能提高性能。在不同评估中的一致表现也证明了 NSA 作为通用架构的稳健性。
长上下文基准性能
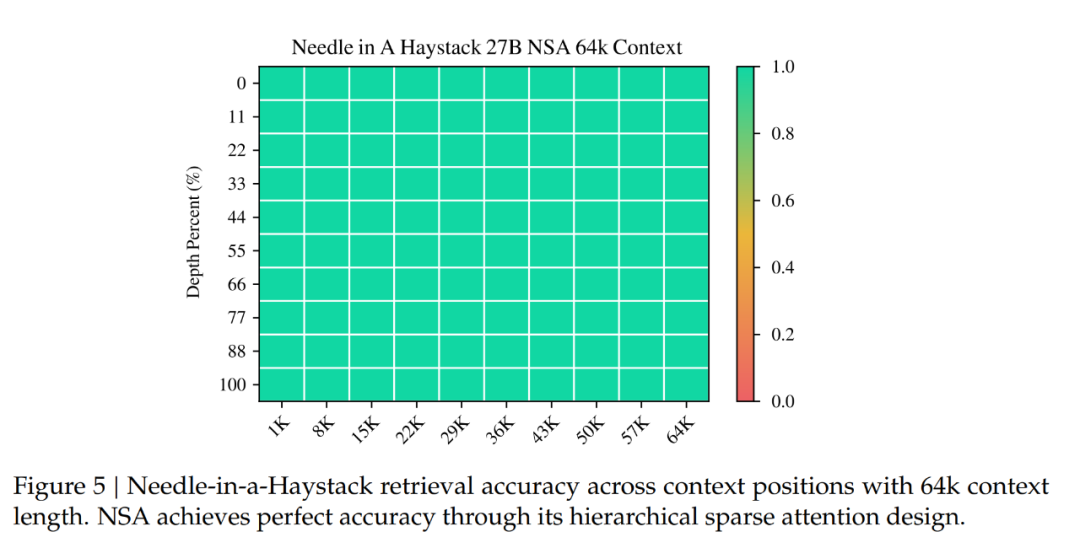
下图 5 展示了 NSA 在 64k 上下文的大海捞针(needle-in-a-haystack) 测试中的结果,它在所有位置上都实现了完美的检索准确率。
这一性能源于 DeepSeek 团队的分层稀疏注意力设计,该设计结合压缩 token 来实现高效的全局上下文扫描,以及结合选择 token 来实现精确的局部信息检索。粗粒度压缩以较低的计算成本识别相关的上下文块,而对选定 token 的 token 级注意力可确保关键细粒度信息的保留。这种设计使得 NSA 能够同时保持全局意识和局部精度。
作者还在 LongBench 上对 NSA 进行了评估,并与 SOTA 稀疏注意力方法和 Full Attention 基线进行了比较。为了确保一致的稀疏性,他们将所有稀疏注意力基线中每个查询激活的 token 设置为 2560 个 tokens,这对应于 NSA 在处理 32k 序列长度时激活的 token 的平均数量。按照 StreamLLM,此 token 预算包括前 128 个 tokens 和 512 个本地 tokens。
作者从 LongBench 中排除了某些子集,因为它们在所有模型中的得分都较低,可能无法提供有意义的比较。结果如下表 2 所示,NSA 获得了最高平均分数 0.469,优于所有基线,其中比 Full Attention 高出 0.032,比 Exact-Top 高出 0.046。
这一改进源于两个关键创新,分别是(1)原生的稀疏注意力设计,能够在预训练期间对稀疏模式进行端到端优化,促进稀疏注意力模块与其他模型组件之间的同步适应;(2)分层稀疏注意力机制实现了局部和全局信息处理之间的平衡。
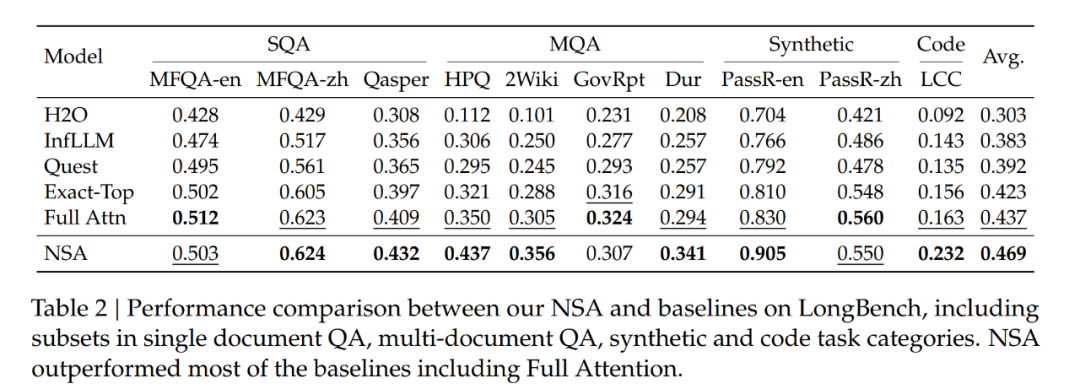
值得注意的是,NSA 在需要对长上下文进行复杂推理的任务上表现出色,在两项多跳 QA 任务(HPQ 和 2Wiki)上比 Full Attention 实现了 + 0.087 和 +0.051 的改进,在代码理解方面超过了基线(LCC 上实现 + 0.069 的改进),并在段落检索方面优于其他方法(PassR-en 上实现 + 0.075 的改进)。
这些结果验证了 NSA 处理各种长上下文任务中的能力,其原生预训练的稀疏注意力在学习任务最优模式方面提供了额外的助益。
思维链推理性能评估
为了评估 NSA 与前沿下游训练范式的兼容性,作者研究了其通过后训练获得思维链数学推理能力的能力。
鉴于强化学习在较小模型上的有效性有限,作者从 DeepSeek-R1 进行知识蒸馏,用 100 亿个 32k 长度的数学推理轨迹进行监督微调(SFT)。
这产生了两个可比较的模型:Full Attention-R(全注意力基线)和 NSA-R(NSA 的稀疏变体)。
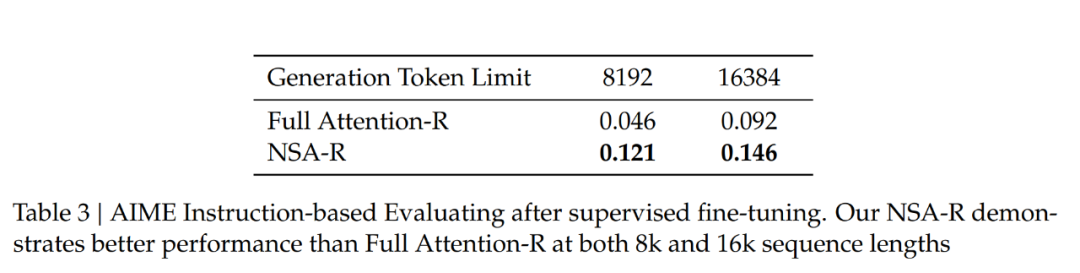
然后,作者在具有挑战性的美国数学邀请赛(AIME 24)基准上评估这两个模型。使用采样温度为 0.7 和 top-𝑝值为 0.95 的配置,为每个问题生成 16 个回答,并计算平均得分。为了验证推理深度的影响,作者在两种生成上下文限制下进行实验:8k 和 16k token,测量扩展的推理链是否提高了准确性。模型预测的示例比较见附录 A。
如表 3 所示,在 8k 上下文设置下,NSA-R 的准确性显著高于 Full Attention-R(+0.075),这一优势在 16k 上下文设置下仍然保持(+0.054)。
这些结果验证了原生稀疏注意力的两个关键优势:
(1)预训练的稀疏注意力模式能够高效捕捉对复杂数学推导至关重要的长距离逻辑依赖关系;
(2)该架构的硬件对齐设计保持了足够的上下文密度,以支持不断增长的推理深度,而不会出现灾难性遗忘。在不同上下文长度下的一致优势证实了稀疏注意力在原生集成到训练流程中时,对于高级推理任务的可行性。
效率分析
作者在一个 8-GPU A100 系统上评估了 NSA 相对于 Full Attention 的计算效率。
训练速度
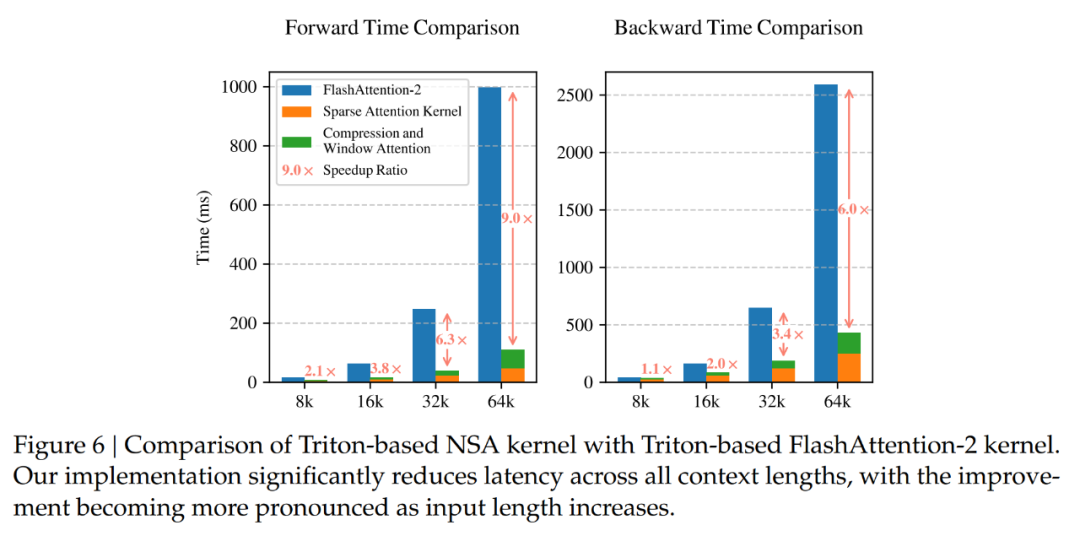
为了确保在相同后端下进行公平的速度比较,作者将基于 Triton 的 NSA 注意力和 Full Attention 实现与基于 Triton 的 FlashAttention-2 进行对比。如图 6 所示,随着上下文长度的增加,NSA 实现了越来越大的加速,在 64k 上下文长度下实现了 9.0 倍的前向加速和 6.0 倍的反向加速。
值得注意的是,序列越长,速度优势就越明显。这种加速源于 DeepSeek 的硬件对齐算法设计,其能最大限度地提高稀疏注意力架构的效率:(1) 分块式内存访问模式通过合并加载最大限度地利用了 Tensor Core;(2) 内核中精细的循环调度消除了冗余的 KV 传输。
解码速度
注意力机制的解码速度主要由内存访问瓶颈决定,这与 KV 缓存加载量密切相关。
在每一步解码过程中,NSA 最多只需要加载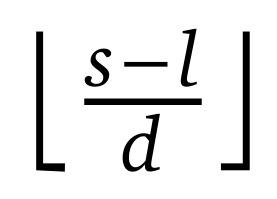 个压缩 token、𝑛𝑙′个选定的 token 以及𝑤个邻近 token,其中𝑠是缓存的序列长度。如表 4 所示,随着解码长度的增加,该方法在延迟方面表现出显著的减少,在 64k 上下文长度下实现了高达 11.6 倍的加速。
个压缩 token、𝑛𝑙′个选定的 token 以及𝑤个邻近 token,其中𝑠是缓存的序列长度。如表 4 所示,随着解码长度的增加,该方法在延迟方面表现出显著的减少,在 64k 上下文长度下实现了高达 11.6 倍的加速。
这种内存访问效率的优势在序列长度增加时也会进一步放大。

关于此研究的更多内容,大家可以查看原论文。





























