最近,我需要研究图像相似性搜索,我想知道基于架构训练方法的嵌入是否存在差异。在本文中,我将使用Flickr数据集[6]比较EfficientNet[1]、ViT[2]、DINO-v2[3]、CLIP[4]和BLIP-2[5]的视觉嵌入在图像相似性搜索中的表现。我将主要使用Huggingface和Faiss库进行实现。首先,我将简要介绍每个深度学习模型。接下来,我将展示代码实现和比较结果。

一、EfficientNet、ViT、DINO-v2、CLIP和BLIP-2的简要介绍
在本节中,我将介绍用于实验的几个深度学习模型。请注意,我将使用“嵌入”和“特征”等词,它们的含义相同。我只是根据论文的描述来使用它们。让我们深入了解它们!
1. EfficientNet
EfficientNet[1]是一种卷积神经网络,专注于在保持计算效率的同时实现高精度。它属于监督学习。作者深入研究了通道数(宽度)、总层数(深度)和输入分辨率,以解决模型大小、精度和计算效率之间的权衡问题。与已经引入的计算机视觉模型(如ResNet)相比,它在2019年取得了最先进的结果。

EfficientNet根据模型大小分为B0到B7几个变体,如下所示。模型越大,精度越高。

在本文中,我将使用EfficientNet-B7进行实验。提取的嵌入是最后一个隐藏层的输出,因为深层比浅层具有更多的语义信息。
2. Vision Transformer (ViT)
Vision Transformer[2]是由Google开发的第一篇成功将Transformer架构应用于计算机视觉领域的论文。它同样属于监督学习。它将输入图像划分为多个补丁,并将它们输入到Transformer编码器中。这些补丁相当于自然语言处理中的标记。对于分类任务,ViT引入了一个称为类标记的标记,它在最后一个注意力层的输出中包含整个图像的表示。
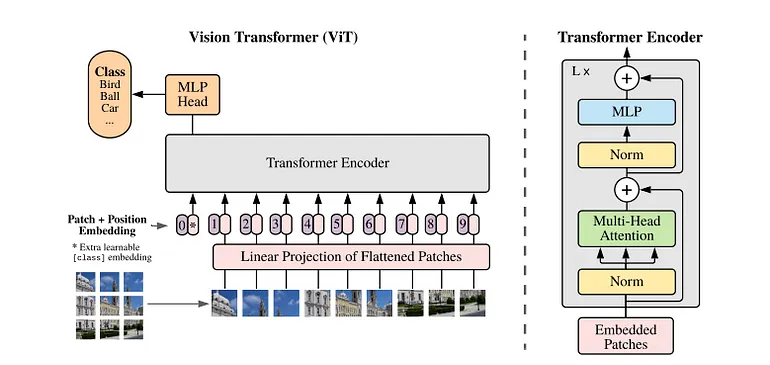
与NLP Transformer类似,它需要在大数据集上进行预训练,并对下游任务进行微调。与CNN相比,它的一个优势是可以通过自注意力机制利用图像的全局信息。与EfficientNet一样,模型越大,能力越强。

在本文中,我将使用ViT-Large。提取的嵌入是类标记的输出,因为它包含整个图像的语义信息。
3. DINO-v2
DINO-v2[3]是由Meta开发的基础模型,用于生成计算机视觉中的通用视觉特征。作者将自监督方法应用于ViT架构,以理解图像和像素级别的特征;因此,DINO-v2可以执行任何计算机视觉任务,如分类或分割。在架构方面,DINO-v2基于前身DINO,即“无标签知识蒸馏”的缩写。

DINO有两个网络:学生和教师。它利用协同蒸馏,其中学生和教师网络具有相同的架构,并且在训练期间在两个方向上进行蒸馏,从教师到学生以及从学生到教师。注意,学生到教师的蒸馏使用学生网络输出的平均值。
对于DINO-v2,作者更新了训练方法,添加了一些损失和正则化。此外,他们还策划了一个高质量的数据集,以获得更好的图像特征。
在实验中,我们将使用类标记的输出,因为它们像ViT一样包含整个图像的语义信息。
4. CLIP
CLIP是由OpenAI开发的改变游戏规则的多模态模型之一[4]。它属于弱监督学习,基于Transformer架构。由于其独特的架构,它能够进行零样本图像分类。

CLIP架构包含文本和图像编码器。它通过对比损失对齐文本和图像特征,从而获得多模态能力。因此,它在文本和图像特征之间共享相同的特征空间,并且可以通过找到最相似的文本特征来实现零样本图像分类。
CLIP编码器基于Transformer。因此,我们将使用图像编码器中类标记的输出,类似于ViT。
5. BLIP-2
BLIP-2[5]是由SalesForce在2023年开发的开源多模态模型。它属于监督学习,基于Transformer架构。它专注于利用预训练的大型模型(如FlanT5和CLIP)来实现高效的训练(因为在典型预算下从头开始训练大型模型很困难)。由于预训练的大型语言和视觉模型的训练方式不同,作者引入了Q-Former来对齐预训练模型之间的特征空间。

BLIP-2包括两个阶段。第一阶段训练Q-Former,以使用图像-文本匹配、图像-文本对比损失和基于图像的文本生成等损失来对齐来自预训练图像编码器的文本特征和图像特征。第二阶段再次训练Q-Former,以将其特征空间与大型语言模型(如FlanT5)对齐。因此,Q-Former可以理解来自文本和图像源的特征。
顾名思义,Q-Former架构基于Transformer。我们将使用Q-Former的输出作为特征提取层。
二、EfficientNet、ViT、DINO-v2、CLIP和BLIP-2在图像相似性搜索中的嵌入比较
在本节中,我们将比较EfficientNet、ViT、DINO-v2、CLIP和BLIP-2在图像相似性搜索中的结果。这些模型具有不同的架构和训练损失。它们之间会有什么不同?让我们从环境设置开始。
1. 环境设置
我使用了Python 3.10的conda环境。我在Ubuntu 20.04上进行了实验,使用cuda 11.0、16 GB GPU和16 GB RAM。
接下来,我们需要通过conda和pip安装以下库。
准备工作已经完成!现在,让我们实现代码。我们将使用Faiss库[7]来测量图像相似性搜索中的图像相似性。Faiss是一个基于近似最近邻搜索算法的高效相似性搜索库。此外,我们将使用Flickr30k数据集[6]进行实验。在直接进入图像相似性搜索之前,我们将探索如何从每个模型中提取嵌入(特征)。
2. 从每个模型中提取特征
在本实验中,我将使用Huggingface的transformer库来提取嵌入。与原始的Pytorch实现相比,我们可以轻松提取隐藏状态。本节代码检查输入和输出维度,因此我们将在CPU上运行它们。
(1) EfficientNet
EfficientNet的特征提取代码如下所示。
首先,我们需要准备输入。预定义的EfficientNet图像处理器会自动将输入形状处理为(batch_size, 3, 600, 600)。经过模型后,我们可以获得带有隐藏状态的输出。最后一个隐藏状态的维度为(batch_size, 640, 19, 19),因此我们对获得的嵌入应用降维平均处理。
(2) ViT
对于ViT的特征提取,提取代码如下所示。
同样,预定义的ViT图像处理器会自动将输入形状处理为(batch_size, 3, 224, 224)。最后一个隐藏状态的维度为(batch_size, 197, 1024),我们只需要类标记,因此提取第二个维度(197)的第一个索引。
(3) DINO-v2
DINO-v2基于ViT,因此基础代码几乎相同。区别在于我们加载DINO-v2的图像处理器和模型。提取代码如下所示。
基本上,我们使用相同的图像处理器。预定义的ViT图像处理器会自动将输入形状处理为(batch_size, 3, 224, 224)。最后一个隐藏状态的维度为(batch_size, 197, 1024),我们只需要类标记,因此提取第二个维度(197)的第一个索引。
(4) CLIP
CLIP也基于ViT,因此过程相同。Huggingface的transformers库已经为CLIP提供了特征提取方法,因此实现更加简单。
我们使用相同的图像处理器。预定义的ViT图像处理器会自动将输入形状处理为(batch_size, 3, 224, 224)。get_image_features方法可以提取给定图像的嵌入,输出维度为(batch_size, 512)。它与ViT和DINO-v2不同。
(5) BLIP-2
我们可以从ViT和Q-Former的输出中提取图像嵌入。在这种情况下,Q-Former的输出可以包含来自图像和文本视角的语义,因此我们将使用它。
我们使用BLIP-2处理器,它可以处理图像和文本输入。它会自动将图像输入形状处理为(batch_size, 3, 224, 224)。我们可以使用get_qformer_features提取Q-Former的输出,输出维度为(batch_size, 32, 768)。我们通过对输出取平均值来降维,嵌入维度将为(batch_size, 768)。
现在我们已经了解了如何从每个模型中提取嵌入。接下来,让我们检查使用Faiss进行图像相似性搜索的实现。
3. 图像相似性搜索
我们可以使用Faiss接口轻松实现图像相似性搜索,只需几行代码。我们假设我们有一个名为features的变量。过程如下:
- 将输入特征类型转换为numpy.float32。
- 实例化Faiss向量存储并为其注册输入特征。
- 通过调用search方法搜索向量。
我们可以选择如何测量向量之间的距离,例如欧几里得距离或余弦相似度。在本文中,我们使用余弦相似度。伪代码如下所示。
现在,比较图像相似性搜索结果的所有先决条件已经完成。让我们从下一节开始检查具体结果。
4. 图像相似性搜索结果的比较
在本节中,我将比较使用五个模型进行图像相似性搜索的结果。对于数据集,我使用了从Flickr30k中随机挑选的10k张图像。我为每个模型实现了一个自定义管道,以实现批量特征提取。在本节末尾,我将附上我用于此实验的笔记本。我选择了以下图像来比较结果。

从Flickr30k数据集中挑选的图像
“3637013.jpg”的结果如下所示:

对“3637013.jpg”进行的图像相似性搜索
这个案例相对容易,因此所有模型都能挑选出语义相似的图像。“3662865.jpg”的结果如下所示:
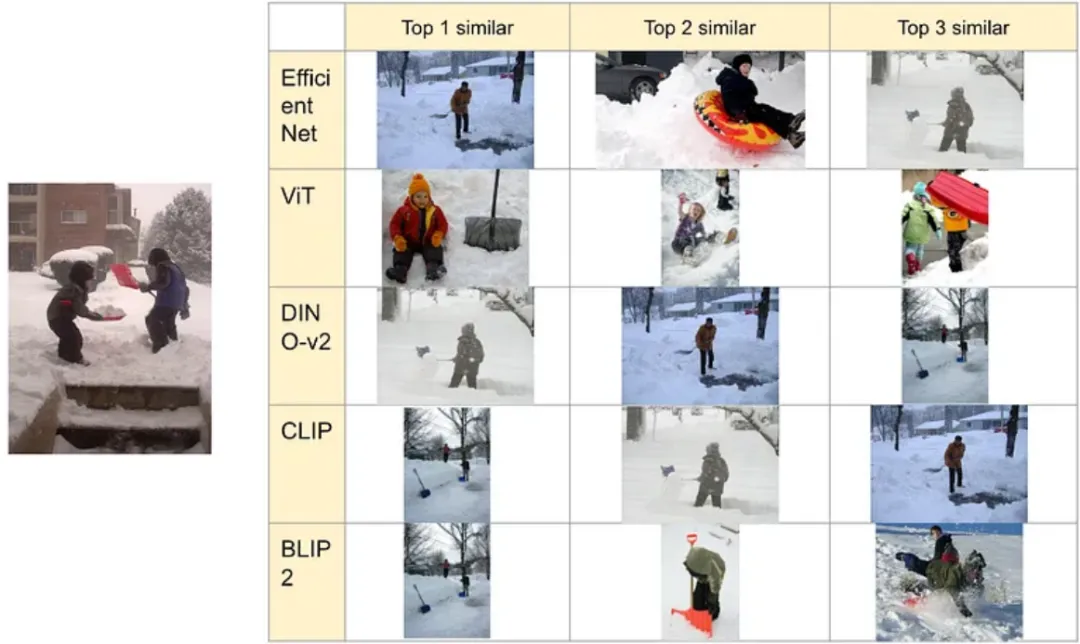
对“3662865.jpg”进行的图像相似性搜索
在这种情况下,DINO-v2和CLIP能够捕捉到“铲雪”的语义,但其他模型有时只能捕捉到“雪”。
“440375442.jpg”的结果如下所示:

对“440375442.jpg”进行的图像相似性搜索
EfficientNet和ViT可能将工作服误解为手术服,因此它们无法捕捉目标图像的语义。DINO-v2能够理解“垃圾和穿工作服的人”的语义,CLIP专注于穿工作服的人,而BLIP2专注于垃圾。我认为DINO-v2、CLIP和BLIP2能够捕捉语义。
“1377428277.jpg”的结果如下所示:

对“1377428277.jpg”进行的图像相似性搜索
这张图像的语义是:“街上有很多人正在享受某个节日或街头表演。”EfficientNet和ViT专注于雨伞,因此它们无法捕捉语义。另一方面,DINO专注于婴儿车,表现稍逊一筹。CLIP试图捕捉节日和街头的部分,但也稍逊一筹。BLIP2能够捕捉街头表演和婴儿车。
“57193495.jpg”的结果如下所示:

对“57193495.jpg”进行的图像相似性搜索
在这种情况下,EfficientNet、ViT和CLIP有时能够捕捉到“穿着戏服并涂白脸的女人”的语义。然而,它们相对不足。相比之下,DINO-v2和BLIP2能够捕捉到服装或角色扮演的语义。
最后一张图像“1393947190.jpg”的搜索结果如下所示:

对“1393947190.jpg”进行的图像相似性搜索
结果因架构(CNN和Transformer)而异。虽然EfficientNet可能专注于图像的白色和棕色,但其他模型能够捕捉到“正在卷丝的人”的语义。CLIP可能专注于传统手工艺品,但其他模型能够捕捉语义。
总结一下,我们有以下观察结果:
- EfficientNet(CNN架构)不擅长捕捉超出像素信息的语义。
- Vision Transformer比CNN更好,但仍然更关注像素信息而不是图像的含义。
- DINO-v2能够捕捉图像的语义,并且倾向于关注前景物体。
- CLIP能够捕捉语义,但有时可能会受到图像中可读的语言信息的强烈影响。
- BLIP2能够捕捉语义,是其他模型中表现最好的。
我认为,为了获得更好的图像相似性搜索结果,我们基本上应该使用DINO-v2或BLIP2。至于使用上的区别,当我们专注于图像中的物体时,应该使用DINO-v2。而当我们专注于超出像素信息的语义(如情境)时,应该使用BLIP2。
完整代码:https://gist.github.com/tanukon/00d689478ee3f7d2abd0366f1352cf9d#file-embedding_comparison-ipynb