













用代码训练大模型思考,其他方面的推理能力也能提升。
DeepSeek团队最新研究,利用300多万个实例,将代码转换成思考过程,构建出数据集CODEI/O,对Qwen、Llama等模型进行了训练。
结果,在各种类型的推理任务当中,模型性能都取得了全面提升,包括在非代码类的推理任务上,也展现出了良好的迁移能力。
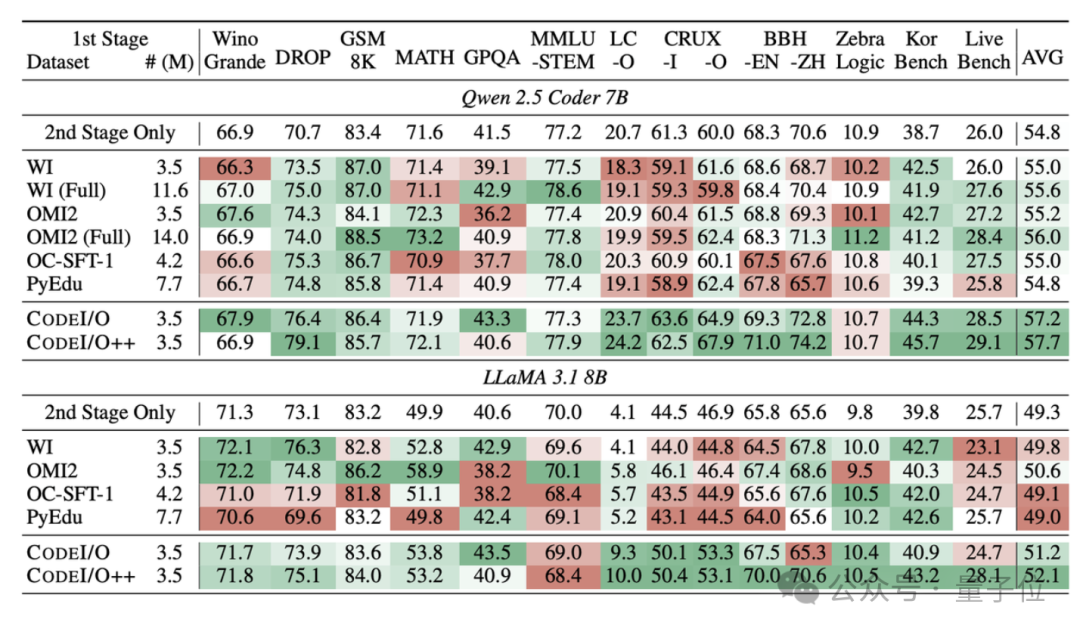
研究团队认为,在代码当中暗含了不同类型场景的思考过程,于是想要把这种思考过程“提取”出来训练推理模型。
他们生成了大量的训练数据运行这些代码,然后把代码、输入/输出对以及功能描述输入DeepSeek-V2.5,从而合成自然语言形式的推理过程。
在此基础上,团队还引入了验证和修订机制,形成了更高质量的CODEI/O++。

从代码中构建思维链
首先,作者从CodeMix、PyEdu-R等数据集中收集了80多万份代码文件,涵盖多种编程语言(以Python为主),任务类型多样,并且蕴含了丰富的推理模式。
但是,由于原始代码文件通常缺乏结构化,包含不相关的元素,难以以自包含的方式执行,作者使用DeepSeek-V2.5模型对其进行预处理,将其转换为统一的格式。
转换过程中的工作主要包括把核心逻辑功能提取到函数中,添加总结整体逻辑的主入口函数,明确定义主入口函数的输入/输出,创建独立的基于规则的输入生成器函数,以及基于主入口函数生成简明的问题陈述作为查询等等。

接下来,在转换后的每个函数上,使用输入生成器采样多个输入,并通过执行代码获得相应的输出,从而收集输入-输出对。
这一过程中,部分代码出现了超时、复杂度过高、不可执行或结果不确定等情况,这部分代码被作者跳过,最终生下了40多万份代码文档,产生了350万个样本实例。
然后,作者利用DeepSeek-V2.5,将代码、输入输出对、功能描述等信息合成为自然语言思维链(CoT),构建训练样本。
对于每一个输入-输出对,作者首先构建一个输入提示。这个提示由几个部分拼装而成:
- 函数定义:即之前结构化和标准化后的Python函数代码。
- 文本描述:用自然语言概括函数的功能和目的。
- 参考代码:与函数定义类似,但可能包含一些额外的上下文信息或注释。
- 输入或输出:根据是输入预测还是输出预测任务,提示中会包含具体的输入或期望的输出。

将构建好的提示输入给DeepSeek-V2.5模型,模型会根据提示生成一段自然语言文本作为响应。
这段文本就是作者想要的推理过程——它需要解释如何从给定的输入推导出输出,或者在给定输出的情况下如何构造出满足条件的输入。
通过这种方式收集的数据集,就是CODEI/O。

在CODEI/O的基础上,作者进一步利用了代码的可执行特性,合成了数据质量更高的CODEI/O++。
作者首先对CODEI/O中生成的所有响应通过重新执行代码进行正确性验证。对于验证为不正确的响应,作者将执行反馈追加为第二轮输入信息,并要求模型重新生成一个响应。
执行反馈包括输出预测的正误、输入预测基于错误输入的执行输出,以及代码执行失败的错误信息等。
在第二轮生成后,再次检查新响应的正确性。
无论第二轮结果如何,最终的响应都由四个部分按顺序构成:第一轮响应、第一轮反馈、第二轮响应和第二轮反馈。
对于第一轮就正确的响应,第一轮反馈简单标记为“Success”,且没有第二轮内容。
与CODEI/O一样,所有修订后的响应都会被保留。通过引入基于执行反馈的多轮修正所构建的增强型数据集就是CODEI/O++。

数据集构建完成后,作者采用了两阶段训练策略对相关模型进行训练。
第一阶段先用CODEI/O或CODEI/O++来训练推理能力,然后再用通用指令数据集进行微调,教会模型遵循自然语言指令、执行各种任务。
模型推理能力全面提升
为了评估CODEI/O或CODEI/O++的效果,作者一共找来了四个模型来进行测试,分别是Qwen 2.5-7B-Coder、Deepseek v2-Lite-Coder、Llama 3.1-8B和Gemma 2-27B。
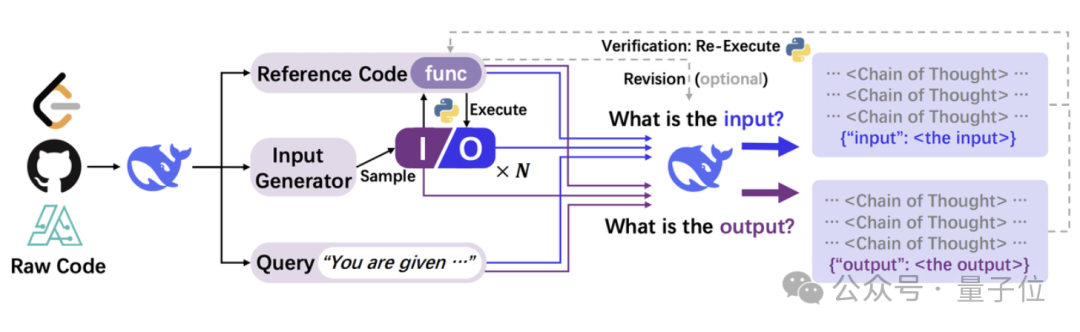
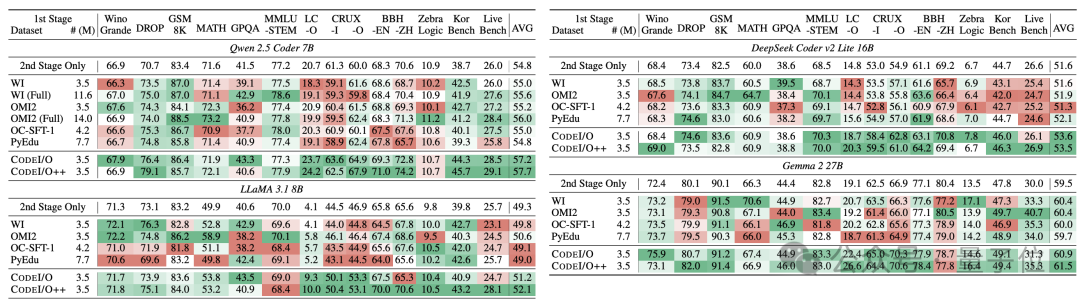
测试过程中,作者共选用了10余个数据集,测试了模型常识、数学、代码、物理、工程等领域的表现,具体数据集如下表:

CODEI/O训练之后,Qwen-Coder在代码理解任务上取得了突破性进展,并且在阅读理解和推理任务(如DROP)上也有明显提升,这表明通过代码训练获得的推理能力确实迁移到了其他领域。
DeepSeek-Coder在CODEI/O的训练下也展现出了均衡的进步,在各个维度上都实现了稳定的改进。
Qwen-Coder和DeepSeek-Coder的表现说明,即使是已经在代码领域有专门训练的模型,也能从这种结构化的推理训练中获益。
Llama在LeetCode-O上的性能提升了将近150%,说明即使是参数量较小的模型,通过合适的训练方法也能在特定任务上获得较大提升。
而Gemma作为测试中最大的模型,展示了CODEI/O方法在大规模模型上的适用性,在多个关键领域取得了进步。
相比于数据量更大的WebInstruct(WI),CODEI/O整体上取得了更好的效果;而相对于专门为某种任务设计的OpenMathInstruct2(OMI2)、PyEdu等方式,CODEI/O体现了更强的通用性。
作者简介
本文第一作者是来自上海交大的硕士生Junlong Li,目前在DeepSeek实习。
同时他还在香港科技大学助理教授何俊贤的指导下进行研究工作,何俊贤亦是本文的通讯作者。
此外参与了DeepSeek V2、V3以及R1研发的DeepSeek核心研究员、中山大学校友郭达雅也参与了这一项目。
论文地址:https://arxiv.org/abs/2502.07316
GitHub:https://github.com/hkust-nlp/CodeIO
数据集:https://huggingface.co/datasets/hkust-nlp/CodeIO-PyEdu-Reasoning





























