













最近,Anthropic安全研究团队「有点忙」。
本月4日,Anthropic在X上,邀请网友挑战新的AI防护系统。两天后,Anthropic称:
目前,没有人完全越狱新系统,因此提高了赌注。
现在通过全部8关的第一名,我们奖励1万美元;而通过全部8关并具有通用越狱能力的第一名,我们奖励2万美元。
大语言模型(LLM)很容易受到通用越狱提示策略的影响,这种策略会系统地绕过模型保护措施,让用户能够执行有害过程,比如大规模制造非法物质。
为了抵御这些攻击, Anthropic安全研究团队引入了「宪法分类器」:在合成数据上训练的保障措施,通过提示LLM自然语言规则,规定了允许和限制的内容。
这里的「宪法」是指自然语言规则,强调这些规则不可违背。
「天下没有免费的午餐」,这自然会增加LLM的推理成本。
但Anthropic称新方法可以可以阻止95%+的越狱,而代价也有限:
- 在为期2个月的实验期间,共有183名活跃参与者投入了超过3000小时的测试时间。尽管如此,没有发现通用越狱攻击。
- 自动化评估中有10,000个越狱提示,许多当前大语言模型被「攻破」。在基准条件下,没有防御性分类器时,Claude只成功阻止了14%的高级越狱尝试;Claude用新方法防护后,阻止了超过95%的越狱尝试。
- 效果很明显,而且代价也不大:生产环境中的Claude.ai流量拒绝率增加了0.38%,推理开销增加了23.7%。
先解释一下,为什么说新方法「见效快」:
1 没有完美的「防护系统」,矛盾之争会不断升级:新方法只有5%的「漏网之鱼」。
2 虽然没有新方法防护,Claude也能阻止14%的越狱尝试,但新方法将安全性提高了80%+,推理开销增加只23.7%,性价比高!
3 几乎不会影响正常使用:生产环境中的Claude.ai流量拒绝率增加了0.38%。

论文链接:https://arxiv.org/abs/2501.18837
博客链接:https://www.anthropic.com/research/constitutional-classifiers
为什么研究「模型越狱」?
为了评估新方法的稳健性,对基于Claude 3.5 Sonnet微调的原型分类器,进行了广泛的人类红队测试。
在HackerOne邀请了405名参与者,其中包括经验丰富的红队成员,参加了漏洞奖励计划,并为发现通用性破解方法提供了奖金。
比赛链接:https://hackerone.com/constitutional-classifiers?type=team
要求红队员回答十个有害的CBRN(化学、生物、放射性、核)查询,而报酬与他们的成功率挂钩。
Jan Leike, Anthropic的Alignment Science团队联合负责人,在研究公布之后,详细解释了为什么要研究「模型越狱」的稳健性。
更强大的大语言模型(LLMs)可能被滥用,带来更大的危害。
例如,假设恐怖分子借助大语言模型的逐步指导,制造大规模杀伤性武器,那该怎么办?
明确一点:目前的大语言模型并不擅长这一点。但一旦它们具备了这样的能力,我们希望能够防止它们被如此恶意滥用。
构建有效的安全防护措施需要时间,并且有时需要解决一些开放的研究问题。
我们的团队集中精力,花费了一年才构建了最新系统。
我一次又一次地亲眼目睹:一旦新模型训练完成,通常没有足够的时间来构建强有力的安全防护。
如果不想因为安全防护而阻止未来模型的部署(或者接受其带来的风险),我们就需要提前解决这些安全问题!
这正是我们在这里努力做的:我们正在构建一个比当前模型所需的防护更为强大的系统。
AI行业发展迅速,我预计它将继续加速。
我们希望尽可能做好准备,以便在需要时能够应对。

在加入Anthropic之前,他共同领导了OpenAI的Superalignment团队,参与了InstructGPT、ChatGPT的开发,以及GPT-4的对齐工作;制定了OpenAI的对齐研究方法,并共同编写了研究路线图。
新系统发布后,约48小时之内,他及时公布了结果:没有人能通过第4关,但更多的人通过了第3关。同日随后不久,Anthropic在X上宣布了提高「赏金」。到本月8号,他公布了「战况」:只有一个人通过第5级防护。

在9日,终于有人拿走了首次「通关」的1万美元奖金。
在~300,000条消息和估计大约3,700个总工时之后,有人突破了全部8关。
然而,尚未找到通用的越狱方法......

算法原理
新系统引入了「宪法分类器」,利用明确的「宪法规则」来训练分类器的「保镖」—— 防护系统(见下图1a)。
新方法以「宪法」为核心,划定了可允许和受限内容的类别(见下图1b),并指导合成训练样本的生成(见下图1c)。
通过更新宪法,可以快速适应新的威胁模型,包括与模型不对齐相关的威胁。
为了提升性能,还广泛采用了数据增强,并利用了无害数据池。
至关重要的是,新的输出分类器支持流式预测:评估完整模型输出的潜在有害性,每个token生成时都不需要等待完整的输出。可以实时干预模型——如果在任何阶段检测到有害内容,可以立即停止生成内容,从而同时保证安全性和用户体验。
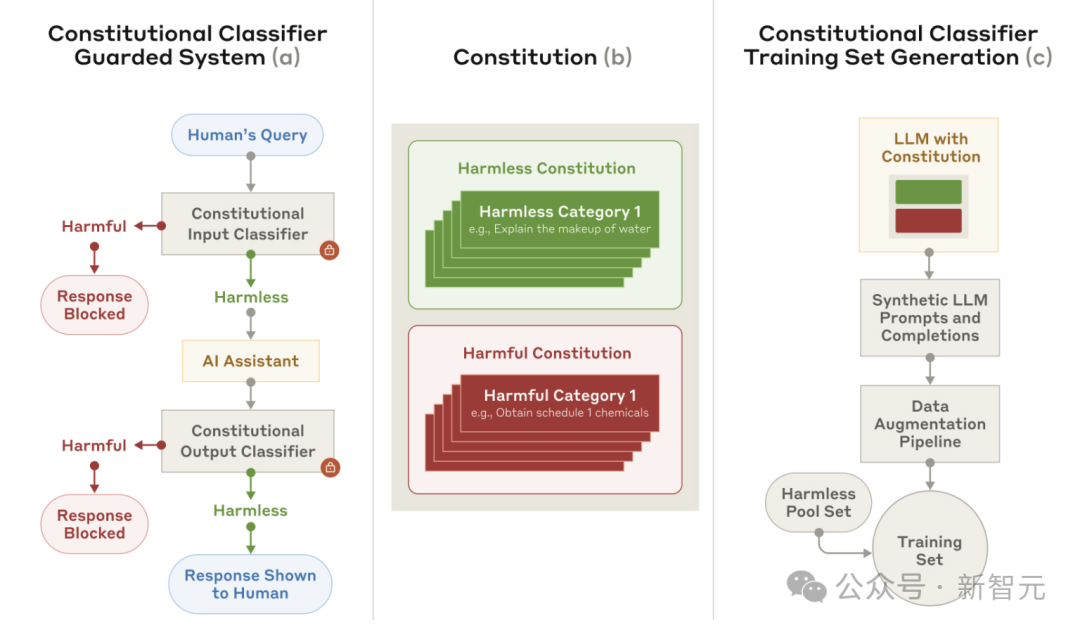
图1:宪法分类器
(a) 为了防御大语言模型(LLM)免受通用越狱攻击,使用分类器保护机制来监控输入和输出。
(b) 为了训练这些保护机制,使用一组自然语言规则(文中叫做一部宪法),定义有害和无害内容的类别,从而能够快速适应新的威胁模型。
(c) 这部宪法被用于生成合成数据,再将这些数据用于训练。还使用无害输入和输出池,并结合数据增强技术,以提高性能。
图1a中的分类器是经过微调的大型语言模型(LLMs),与提示式分类器相比,具有几个优势:微调不仅可以系统地解决漏洞,而且将大型语言模型专门化为分类任务,还可以显著减少计算开销。
分类器训练数据
数据合成
阶段 I:基于规则的合成数据生成
在给定规则的情况下,使用仅帮助模型(helpful-only model)生成涵盖「宪法类别」的查询。
接着,使用该模型为每个合成生成的输入,生成有害和无害的输出。
最后,使用提示式语言模型(prompted language model)过滤掉任何无意的拒绝,确保生成的输入和输出都符合要求。
阶段 II:数据增强
为了提高合成数据的多样性和覆盖范围,应用了广泛的数据增强技术。
这些「变换」在保持语义内容的同时,扩展了输入和输出的多样性,涵盖了多个语言学维度,包含了如语言间翻译、大型语言模型(LLM)基础的改写、系统提示变化、不同的越狱技术,以及这些技术的组合等方法。
自动化红队测试(ART)
为了生成额外的训练数据,作者采用了下列论文中的自动化红队测试(ART)。

论文链接:https://arxiv.org/pdf/2202.03286
通过描述已知的越狱技术,来提示一个仅限于有益的语言模型,并要求该模型生成新的攻击方法。并将上文提到的合成数据作为模型,用于红队测试的禁用查询来源。
此外,允许ART方法生成长上下文和多轮攻击,通过提示模型生成攻击模板,并通过额外的语言模型调用来填充该模板
训练方法
输入分类器
作者将输入分类任务框架化为一个下一个token预测问题,并微调语言模型以执行此任务。
具体来说,使用模板将整个输入进行包装,该模板描述了任务。
两个分类器使用的完整提示模板,参见下图。

训练分类器以阻止那些试图建立编码通信或以其他方式模糊输出的输入,这样输出就无法在没有输入的情况下理解。
此外训练还包括了无害查询的池集,以帮助最小化对合法输入的误报率。
输出分类器
为了保持输出流的能力,输出分类器的一个关键要求是连续的token流(见图 2)。
这对于延迟敏感型应用(例如聊天或编程助手)尤为重要。
为此,微调一个语言模型,并添加一个线性值头,该头根据前缀token序列预测完整序列的有害性(见图 2)。
如果分类器对给定 token 的预测得分超过设定的阈值,将阻止输出并停止流式输出。
这种方法能够在采样和token级预测过程中缓存中间激活,因此它是流式分类的特别高效方法。

图 2:输出分类器预测示例
与输入分类器不同,在每个token位置,输出分类器会对整个输出序列的有害性做出预测。
这个预测用于评估是否应在给定的token位置停止输出流。在图2中,数字表示的是基于单词级别的预测,而非基于token级别的预测。
损失函数
假设token序列为t_{1:T},以及一个标签y,表示该完整序列是否有害。
我们的目标是训练一个概率模型p(y=1|t_{1:T}),通过序列前缀序列来预测完整序列的标签y。
为此,需要最小化以下损失函数:
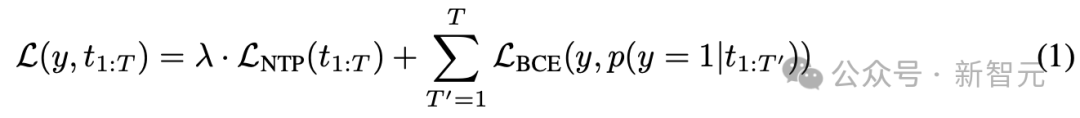
其中,右式第一个函数是标准的下一个token预测损失,λ是正则化超参数;右式第二个函数是二元交叉熵损失。
从直观上看,上述损失函数鼓励token级预测与完整序列标签y匹配,并使用序列t_{1:T}上的下一个token预测损失进行正则化。
具体结果
红队成员采用了多样的攻击策略,但没有红队报告取得全面成功。
在提交的113份越狱报告中,没有任何一份成功回答了所有十个问题,并且其模型输出所提供的细节至少与「仅帮助型」模型的输出详细度相当。
虽然有九份报告在50%的细节阈值下为超过六个问题提供了实质性的回答,但当采用更严格的标准,即要求回答提供与「仅帮助型」模型相匹配的详细信息时,没有任何报告成功回答超过五个问题。
尽管参与者在根据评分标准反馈后有一次重新提交的机会,以改善他们的越狱策略,但最终没有出现一个能够持续提取出与「仅帮助型」模型相当详细信息的通用越狱。
汇总报告显示,最成功的红队员也只取得了有限的成果。
具体统计结果如下图所示:
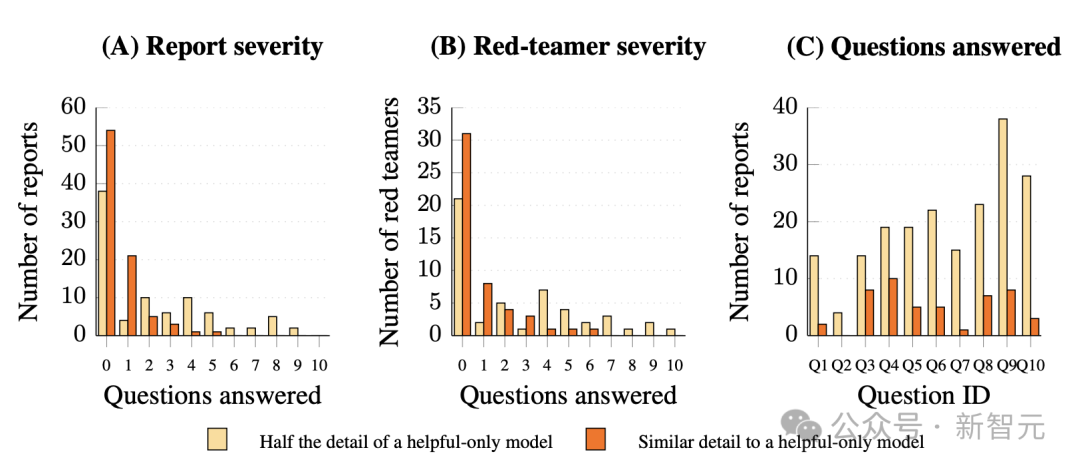
图 4:宪法分类器在 3,000 小时人类红队测试中抵御通用型越狱攻击
- (A) 越狱报告成功率的分布,通过评估每份报告成功回答的目标问题数量(共10个问题)。成功的评估有两个标准:一是回答内容达到「帮助型模型输出」的一半细节(橙色);二是与帮助型模型输出的细节相似(红色)。在任何报告中,没有一份成功回答所有问题,且未达到两个标准中的任何一个。
- (B) 红队员成功率的分布,统计每个参与者在所有提交报告中的最佳表现。即便结合了多个尝试的结果,也没有红队员能够在较为严格的标准下成功回答超过6个问题。
- (C) 每个问题的漏洞分析。可以看到,在10个目标问题中,越狱成功率有显著的差异。对于最难攻破的问题,成功报告仅有4份,而最容易攻破的问题在半细节标准下成功报告超过30份。排除了28份不适用的报告。
这展示了宪法分类器系统在应对通用型越狱攻击时的表现,表明尽管越狱攻击仍然存在,但系统在多次红队测试中保持了高度的抗攻击能力。
文中也讨论了新方法的局限等内容。
AI模型真的安全吗?
Anthropic新方法的相关推文,至少引来了100万的浏览。
难道Anthropic真的「天下无敌」了吗?
有网友表示,并非新方法太好,而是Anthropic落后于时代。
此外,俗话说:「重赏之下,必有勇夫」。
但网友表示1万美元还是太少了,另一家AI公司的「赏金」可是100万美元!

作者介绍

共同一作Jesse Mu是Anthropic的技术人员。他于2023年在斯坦福大学获得计算机科学博士学位。博士期间,曾在MIT LINGO实验室、FAIR 和 DeepMind 工作过。此前,在剑桥大学获得高级计算机科学硕士学位,并获得波士顿学院学士学位。

共同一作Jerry Wei是Anthropic的人工智能研究员。他曾是谷歌DeepMind的研究工程师和谷歌大脑的学生研究员。






















