













如今,DeepSeek团队成员的一举一动,都颇受圈内关注。
近日,来自DeepSeek、上海交通大学、香港科技大学的研究人员推出的全新力作CODEI/O,就获得了Ai2大牛Nathan Lambert的力荐!

论文地址:https://arxiv.org/abs/2502.07316
项目主页:https://codei-o.github.io/
Lambert表示,非常高兴能看到DeepSeek团队成员撰写的更多论文,而不仅仅是有趣的技术报告。(顺便还调侃了一句自己真的想他们了)
这篇论文的主题,是通过一种CodeI/O的方法,利用代码输入/输出,来提炼LLM的推理模式。
值得注意的是,这篇论文是一作Junlong Li在DeepSeek实习期间完成的研究。
一经发布,网友们就立马开始了仔细研究。毕竟,现在在研究人员心目中,DeepSeek已经是一个GOAT team。

有人总结道,除了主线论文之外,DeepSeek作者还发表了许多论文,比如Prover 1.0、 ESFT、Fire-Flyer AI-HPC、DreamCraft 3D等等,虽然都是实习生的工作,但十分具有启发性。

LLM推理缺陷,靠代码打破
推理,是LLM的一项核心能力。以往的研究主要关注的是数学或代码等狭窄领域的提升,但在很多推理任务上,LLM依然面临挑战。
原因就在于,训练数据稀疏且零散。
对此,研究团队提出了一种全新方法——CODEI/O!
CODEI/O通过将代码转换为输入/输出预测格式,从而系统性地提炼出蕴含在代码上下文中的多种推理模式。
研究团队提出将原始代码文件转换成可执行的函数,并设计一个更直接的任务:给定一个函数及其相应的文本查询,模型需要以自然语言的CoT推理形式预测给定输入的执行输出或给定输出的可行输入。
这种方法将核心推理流程从代码特定的语法中解脱出来,同时保留逻辑的严谨性。通过收集和转换来自不同来源的函数,生成的数据包含了各种基础推理技能,如逻辑流程编排、状态空间探索、递归分解和决策。
实验结果表明,CODEI/O在符号推理、科学推理、逻辑推理、数学与数值推理以及常识推理等任务上均实现了一致的性能提升。
下图1概述了CODEI/O的训练数据构建流程。该流程从收集原始代码文件开始,到组装完整的训练数据集结束。
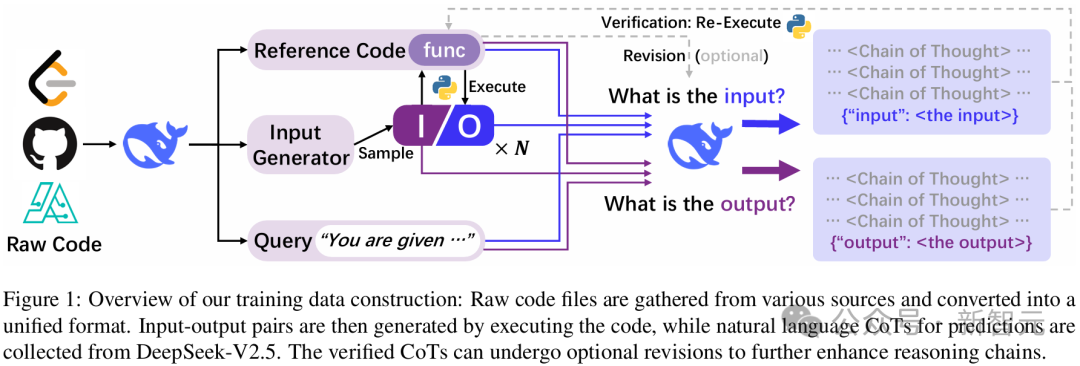
分解CODEI/O架构
收集原始代码文件
CODEI/O的有效性在于选择多样化的原始代码来源,以涵盖广泛的推理模式。
主要的代码来源包括:
- CodeMix:从内部代码预训练语料库中检索的大量原始Python代码文件集合,经过筛选去除过于简单或过于复杂的文件。
- PyEdu-R(推理):Python-Edu的一个子集,侧重于复杂的推理任务,如STEM、系统建模或逻辑谜题,并排除以纯算法为中心的文件。
- 其他高质量代码文件:来自各种小型、信誉良好的来源,包括综合算法存储库、具有挑战性的数学问题和知名的在线编码平台。
合并这些来源后,总共产生了大约810.5K个代码文件。

构造的LeetCode-O基准测试中的一个示例
转换为统一格式
收集到的原始代码文件往往结构混乱,含有冗余内容,并且难以独立执行。
使用DeepSeek-V2.5对原始代码文件进行预处理,将其提炼成统一的格式,强调主要的逻辑功能,使其可执行,以便收集输入-输出对。
研究团队通过清理和重构代码,将核心逻辑功能提取到函数中,排除不必要的元素,然后添加一个主要入口点函数,总结代码的整体逻辑。
该函数可以调用其他函数或导入外部库,并且必须具有非空的参数(输入)以及返回有意义的输出。所有输入和输出都需要是JSON可序列化的,以方便进一步处理。
过程中需明确定义主要入口点函数的输入和输出,包括数据类型、约束(例如,输出范围)或更复杂的要求(例如,字典中的键)等信息。
然后创建一个独立的、基于规则的Python输入生成器函数,而不是直接生成测试用例。此生成器返回遵循主要入口点函数要求的非平凡输入。在约束条件下应用随机性,实现可扩展的数据生成。
最后,根据主要入口点函数生成一个简洁的问题陈述,作为描述代码预期功能的查询。

如何将原始代码文件转换为所需同一格式的示例
收集输入和输出对
在将收集的原始代码文件转换为统一格式后,使用输入生成器为每个函数抽样多个输入,并通过执行代码获得相应的输出。
为了确保输出是确定性的,会跳过所有包含随机性的函数。在执行这些代码期间,研究团队还会对运行时和输入/输出对象的复杂性施加一系列限制。
在过滤掉不可执行的代码、超过运行时限制的样本以及超过所需复杂性的输入-输出对后,获得了从454.9K个原始代码文件派生的3.5M个实例。输入和输出预测实例的分布大致平衡,各占 50%。
构建输入输出预测样本
收集输入-输出对以及转换后的函数后,需要将它们组合成可训练的格式。
研究团队采用的有监督微调过程,每个训练样本都需要一个提示和一个响应。由于目标是输入-输出预测任务,研究团队使用设计的模板将函数、查询、参考代码以及特定的输入或输出组合起来构建提示。
理想情况下,响应应该是一个自然语言的CoT,用于推理如何得出正确的输出或可行的输入。
研究团队主要通过以下两种方式构建所需的CoT响应。
· 直接提示(CODEI/O)
使用DeepSeek-V2.5合成所有需要的响应,因为它具有顶级的性能,但成本极低。此处生成的数据集称为 CODEI/O。
下图2展示了CODEI/O数据集中输入和输出预测的2个示例,在这两种情况下,模型都需要以自然语言的思维链 (CoT)形式给出推理过程。

· 充分利用代码(CODEI/O++)
对于预测不正确的响应,将反馈作为第二轮输入消息追加,并要求DeepSeek-V2.5重新生成另一个响应。将所有四个组件连接起来:第一轮响应+第一轮反馈+第二轮响应+第二轮反馈。研究人员将通过这种方式收集的数据集称为CODEI/O++。

CODEI/O++中的一个完整训练样本
一个框架,弥合代码推理与自然语言鸿沟
如下表1所示,主要展示了Qwen 2.5 7B Coder 、Deepseek v2 Lite Coder、LLaMA 3.1 8B、Gemma 2 27B模型的评估结果。
CODEI/O在各项基准测试中,模型的性能均实现了提升,其表现优于单阶段基线模型和其他数据集(即使是更大规模的数据集)。
不过,竞争数据集,比如OpenMathInstruct2在数学特定任务上表现出色,但在其他任务上有会出现退步(混合绿色和红色单元格)。
CODEI/O展现出的是,持续改进的趋势(绿色单元格)。
尽管其仅使用以代码为中心的数据,在提升代码推理能力同时,还增强了所有其他任务的表现。
研究人员还观察到,与单阶段基线相比,使用原始代码文件(PythonEdu)进行训练,只能带来微小的改进,有时甚至会产生负面影响。
与CODEI/O相比表现明显不足,这表明从这种结构性较差的数据中学习是次优的。
这进一步强调了性能提升,不仅仅取决于数据规模,更重要的是经过深思熟虑设计的训练任务。
这些任务包含了广义思维链中多样化、结构化的推理模式。
此外,CODEI/O++系统性地超越了CODEI/O,在不影响单个任务性能的情况下提高了平均分数。
这突显了基于执行反馈的多轮修订,可以提升数据质量并增强跨领域推理能力。
最重要的是,CODEI/O和CODEI/O++都展现出了跨模型规模和架构的普遍有效性。
这进一步验证了实验的训练方法(预测代码输入和输出),使模型能够在不牺牲专业基准性能的情况下,在各种推理任务中表现出色。

为了进一步研究,新方法中不同关键方面的影响,研究人员进行了多组分析实验。
所有实验均使用Qwen 2.5 Coder 7B模型进行,且报告的结果均为经过第二阶段通用指令微调后获得的结果。
消融实验
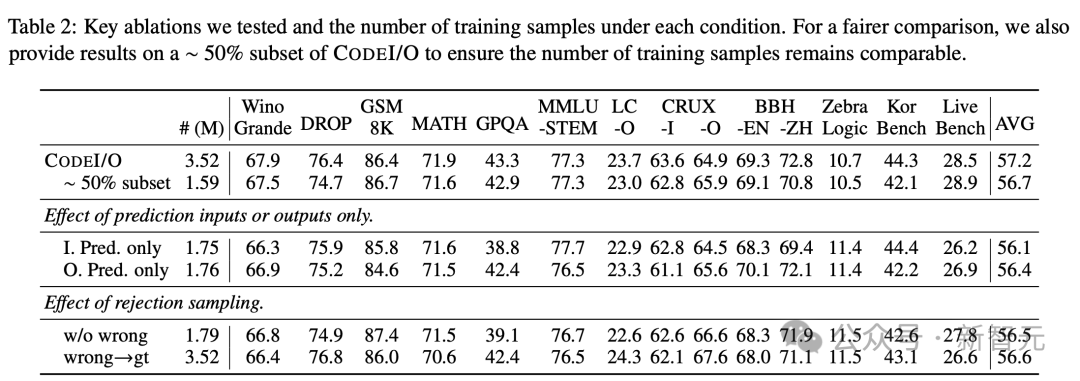
研究团队首先对数据构建过程进行了两项关键的消融研究,结果如下表2所示。
输入/输出预测
作者通过分别训练,来研究输入和输出预测。
结果显示,总体得分相似,但输入预测在KorBench上表现出色,同时略微影响了GPQA的表现;而输出预测在BBH等符号推理任务上显示出更大的优势。CRUXEval-I和-O分别偏向于输入和输出预测。
拒绝采样
他们还探索了使用拒绝采样来过滤不正确响应的方法,这导致50%的训练数据被删除。然而,这造成了普遍的性能下降,表明可能损失了数据的多样性。
作者还尝试通过代码执行将所有不正确的响应,替换为正确答案(不包含思维链)。
这种方法在LeetCode-O和CRUXEval-O等设计用于衡量输出预测准确性的基准测试上,确实带来了改进,但在其他方面降低了分数,导致平均性能下降。
当将这两种方法与训练在样本数量相当的CODEI/O约50%子集上进行比较时,它们仍然没有显示出优势。
因此,为了保持性能平衡,研究人员在主要实验中保留了所有不正确的响应,不做任何修改。
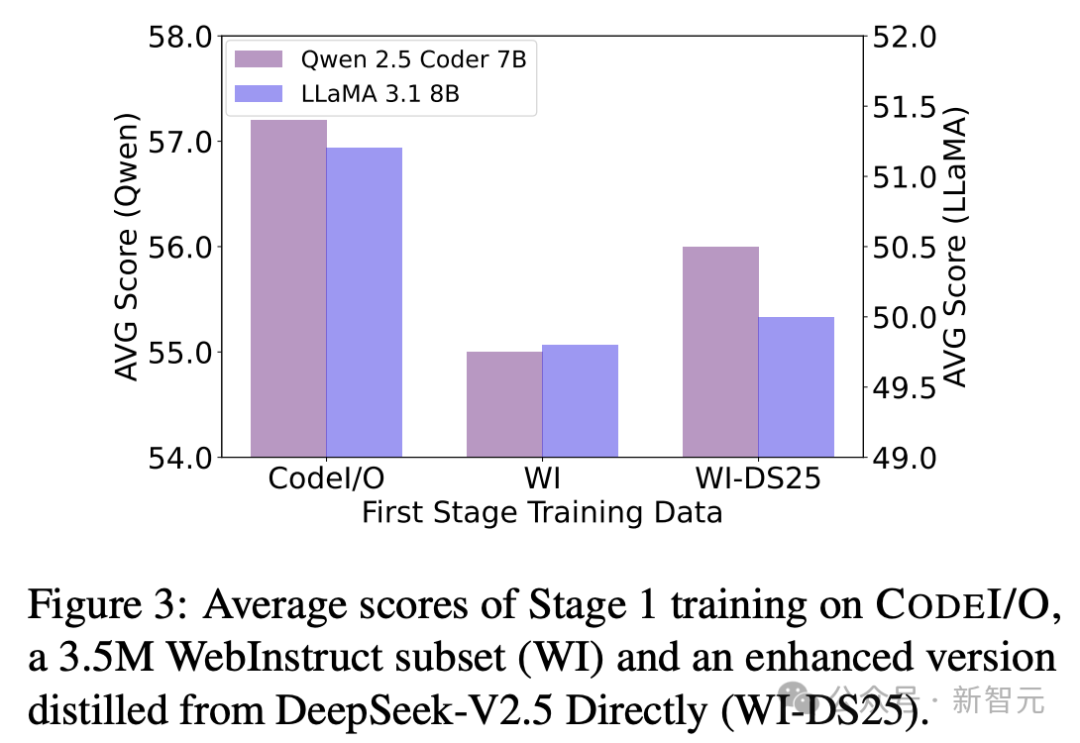
不同合成模型的效果
为了研究不同综合模型的效果,作者使用DeepSeek-V2.5重新生成了350万条WebInstruct数据集的响应,创建了一个更新的数据集,称为WebInstruct-DS25。
如图3所示,虽然WebInstruct-DS25在Qwen 2.5 Coder 7B和LLaMA 3.1 8B上,表现优于原始数据集,但仍然不及CODEI/O。
这突显了代码中多样化推理模式的价值,以及训练中任务选择的重要性。
总的来说,这个比较表明,预测代码的输入和输出能够提升推理能力,而不仅仅是从高级模型中进行知识蒸馏。
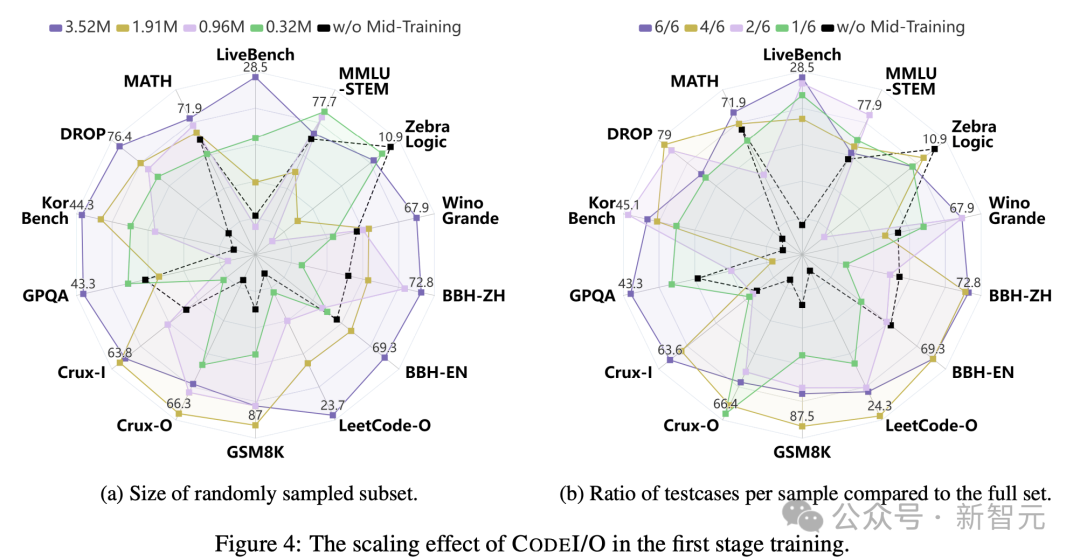
CODEI/O的Scaling效应
研究人员还评估了CODEI/O在不同训练数据量下的表现。
通过随机抽样训练实例,图4a揭示了一个明显的趋势:增加训练样本数量,通常会导致各项基准测试的性能提升。
具体来说,使用最少量的数据在大多数基准测试中表现相对较弱,因为模型缺乏足够的训练来有效泛化。
相比之下,在完整数据集上训练时,CODEI/O实现了最全面和稳健的性能。
中等数量的数据产生的结果介于这两个极端之间,随着训练样本的增加表现出逐步改善。这突显了CODEI/O在提升推理能力方面的可扩展性和有效性。
此外,他们还在输入-输出对的维度上进行了数据scaling,方法是固定并使用所有唯一的原始代码样本,但改变每个样本的输入-输出预测实例数量。
图4b显示了,使用的I/O对相对于完整集合的比例。
虽然scaling效应不如训练样本明显,但仍可以观察到明显的益处,特别是在从1/6增加到6/6时。
这表明,某些推理模型需要多个测试用例,才能完全捕获和学习其复杂的逻辑流程。
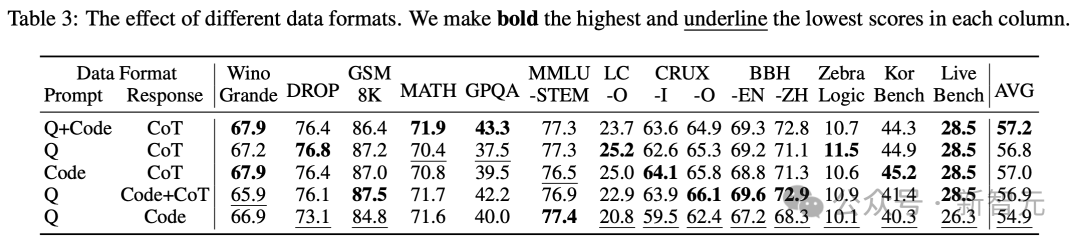
不同的数据格式
这一部分,主要研究了如何在训练样本中最佳安排查询、参考代码和思维链(CoT)。
如表3所示,将查询和参考代码放在提示中,而将思维链放在响应中,可以在各项基准测试中实现最高的平均分数和最平衡的性能。
其他格式的结果显示出,略低但相当的性能,最差的结果出现在查询放在提示中,而参考代码放在响应中的情况。
这类似于标准的代码生成任务,但训练样本要少得多。
这突显了思维链和测试用例的规模对于学习可迁移推理能力的重要性。
多轮迭代
基于CODEI/O(无修订)和CODEI/O++(单轮修订),研究人员将修订扩展到第二轮,通过对第一轮修订后仍然不正确的实例,重新生成预测来评估进一步的改进。
如下图7中,可视化了每一轮中响应类型的分布。
结果显示,大多数正确的响应都在初始轮中预测出来,约10%的错误响应在第一轮修订中得到纠正。
然而,第二轮产生的纠正显著减少,通过检查案例作者发现模型经常重复相同的错误CoT,而没有添加新的有用信息。
在整合多轮修订后,他们在图5中观察到从第0轮到第1轮有持续的改进,但从第1轮到第2轮的收益很小——对LLaMA 3.1 8B显示出轻微改进,但对Qwen 2.5 Coder 7B反而出现了性能下降。
因此,在主要的实验中,研究人员停留在了单轮修订,即CODEI/O++。

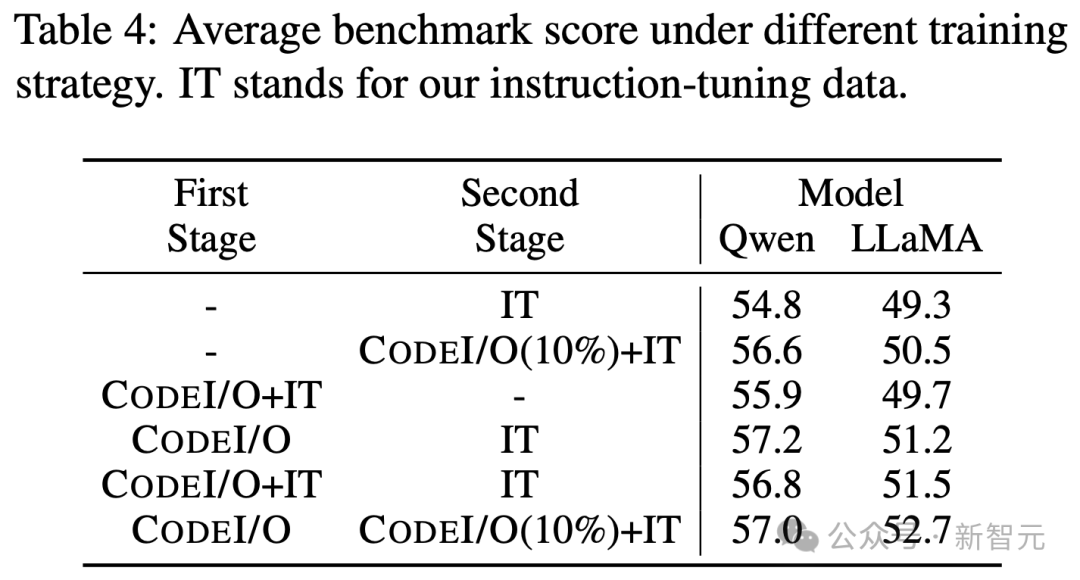
两阶段训练的必要性
最后,研究人员通过测试单阶段混合训练和不同数据混合的两阶段训练,强调了使用CODEI/O数据进行单独训练阶段的必要性。
如表4所示,所有两阶段变体模型的表现都优于单阶段训练。
同时,两阶段训练期间混合数据的效果在不同模型间有所不同。
对于Qwen 2.5 Coder 7B,最好的结果是将CODEI/O和指令微调数据完全分开,而LLaMA 3.1 8B在混合数据的情况下表现更好,无论是在第一阶段还是第二阶段。
论文作者
Junlong Li

Junlong Li是上交计算机科学专业的三年级硕士生,师从Hai Zhao教授。
此前,他于2022年在上交IEEE试点班获得计算机科学学士学位。
他曾在微软亚洲研究院(MSRA)NLC组担任研究实习生,在Lei Cui博士的指导下,参与了多个与Document AI相关的研究课题,包括网页理解和文档图像基础模型。
2023年5月至2024年2月期间,他与GAIR的Pengfei Liu教授紧密合作,主要研究LLMs的评估与对齐等方面的问题。
目前,他在Junxian He教授的指导下从事相关研究。
Daya Guo

Daya Guo在中山大学和微软亚洲研究院联合培养下攻读博士学位,并由Jian Yin教授和Ming Zhou博士共同指导。目前在DeepSeek担任研究员。
2014年到2018年,他在中山大学取得计算机科学学士学位。2017年到2023年,他曾在微软亚洲研究院担任研究实习生。
他的研究主要聚焦于自然语言处理和代码智能,旨在使计算机能够智能地处理、理解和生成自然语言与编程语言。长期研究目标是推动AGI的发展,从而彻底改变计算机与人类的交互方式,并提升其处理复杂任务的能力。
目前,他的研究方向包括:(1)大语言模型(Large Language Model);(2)代码智能(Code Intelligence)。
Runxin Xu(许润昕)

Runxin Xu是DeepSeek的研究科学家,曾深度参与DeepSeek系列模型的开发,包括DeepSeek-R1、DeepSeek V1/V2/V3、DeepSeek Math、DeepSeek Coder、DeepSeek MoE等。
此前,他在北京大学信息科学技术学院获得硕士学位,由Baobao Chang博士和Zhifang Sui博士指导,并在上海交通大学完成本科学业。
他的研究兴趣主要聚焦于AGI,致力于通过可扩展和高效的方法不断推进AI智能的边界。
Yu Wu(吴俣)

Yu Wu目前是DeepSeek技术人员,负责领导LLM对齐团队。
他曾深度参与了DeepSeek系列模型的开发,包括DeepSeek V1、V2、V3、R1、DeepSeek Coder和DeepSeek Math。
在此之前,他曾在微软亚洲研究院(MSRA)自然语言计算组任高级研究员。
他获得了北京航空航天大学的学士学位和博士学位,师从Ming Zhou和Zhoujun Li教授。
他本人的研究生涯取得了诸多成就,包括在ACL、EMNLP、NeurIPS、AAAI、IJCAI和ICML等顶级会议和期刊上发表了80多篇论文。
他还发布了多个具有影响力的开源模型,包括WavLM、VALL-E、DeepSeek Coder、DeepSeek V3和DeepSeek R1。
Junxian He(何俊贤)

Junxian He现任香港科技大学计算机科学与工程系助理教授(终身教职)。
他于2022年在卡内基梅隆大学语言技术研究所获得博士学位,由Graham Neubig和Taylor Berg-Kirkpatrick共同指导。他还于2017年获得上海交通大学电子工程学士学位。
此前,Junxian He还曾在Facebook AI研究院(2019年)和Salesforce研究院(2020年)工作过一段时间。































