













今天给大家分享几种常见的模型压缩技术。

在深度学习中,模型压缩是减少模型大小、降低计算复杂度,同时尽可能保持模型性能的一类技术。它在移动端、嵌入式设备和边缘计算等资源受限的环境中尤其重要。
修剪
修剪是通过去除神经网络中某些不重要的连接或神经元来减少模型的规模和计算需求。
修剪的目标是去除那些对网络性能影响较小的参数,从而达到减少模型复杂度的效果。
常见修剪策略
- 权重修剪
通过移除那些对网络输出贡献较小的权重来减少模型的大小。
这些权重可以通过设定一个阈值来判定:低于某个阈值的权重会被剪掉。 - 神经元修剪
修剪掉整个神经元或通道,这样的修剪方法可以进一步减少计算量,尤其是对于卷积神经网络(CNN)来说,移除不重要的特征图通道会显著降低计算复杂度。
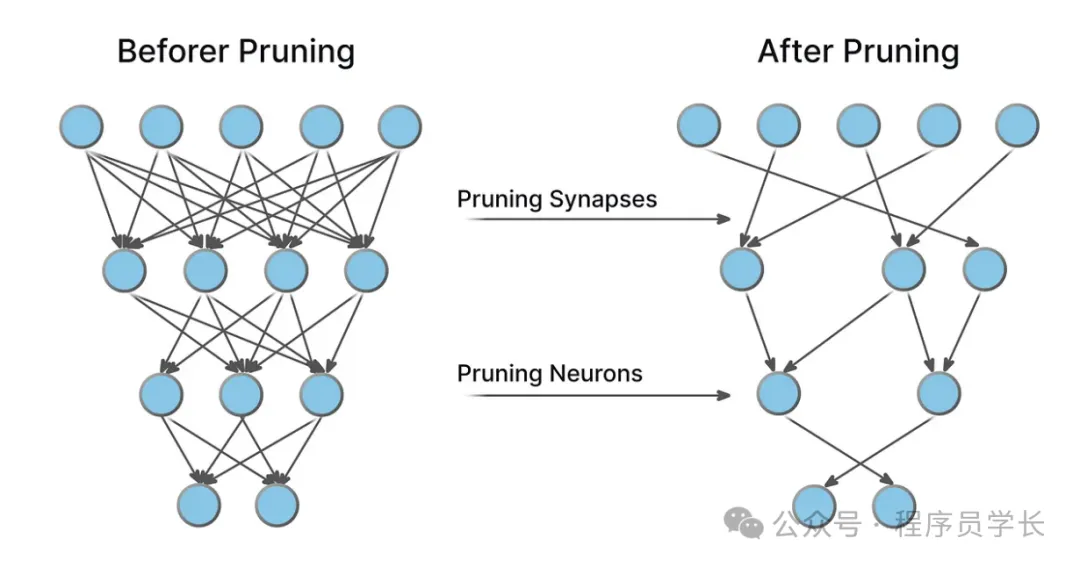
修剪的步骤通常是:
- 训练原始模型
- 计算每个权重的重要性或每个神经元的激活度
- 去除不重要的权重或神经元
- 重新训练,以恢复性能损失
优缺点
- 优点:减小模型尺寸,降低计算负担,提升推理速度,尤其适合硬件加速。
- 缺点:修剪过度可能导致模型性能下降。需要精心设计修剪方案,以在压缩和性能之间找到平衡。
量化
量化是将浮点数表示的参数(如权重和激活)转换为低精度数值表示(如整数)。
量化通常将模型从 32 位浮动点数转换为更低精度的数据类型,如16位、8位或更低,这样可以减少存储需求和加速推理过程。
- 权重量化
将模型中的浮点数权重转换为低精度整数。例如,将32位浮点数权重映射到8位整数,这样就能大幅减少模型的存储需求。 - 激活量化
对于激活值(神经网络各层的输出),也可以应用类似的量化策略。
常见的量化类型
- 后训练量化:在模型训练完成后进行量化,适用于已经训练好的模型。
- 量化感知训练:在训练过程中加入量化过程,从而使得模型能够适应低精度的计算。
量化不仅减小了模型大小,还可能加速模型的推理过程,尤其是在支持低精度计算的硬件上(如TPU、GPU等)。
优缺点
- 优点:大幅减少模型的存储需求,加速推理过程。尤其在嵌入式设备和移动端设备上具有显著的优势。
- 缺点:量化可能导致一定的精度损失
蒸馏
蒸馏是一种将大型、复杂模型的知识迁移到较小模型中的技术。
通常,蒸馏的过程是训练一个小模型(学生模型)以模仿一个较大的、预先训练好的模型(教师模型)的行为。
小模型通过学习教师模型的预测概率分布来获取知识,而不仅仅是传统的标签信息。
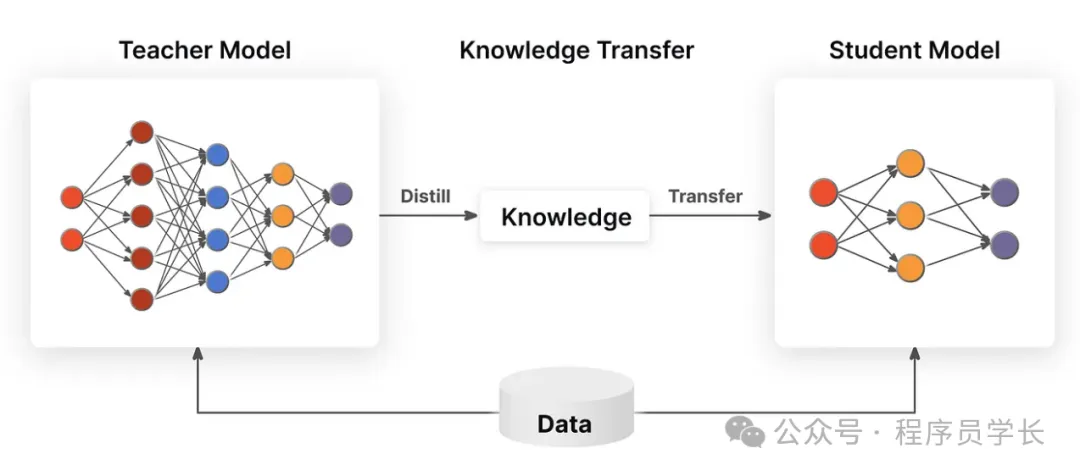
蒸馏的主要思想是:
- 教师模型输出的类别概率包含了更多的“软信息”,这些信息能够帮助学生模型更好地学习一些复杂的模式。
- 学生模型通过与教师模型输出的“软标签”进行学习,能够在不完全依赖硬标签的情况下获取更多的信息,进而提高其性能。
蒸馏的步骤通常是:
- 训练教师模型
首先,训练一个大型且高性能的教师模型,这通常是一个深度神经网络。 - 训练学生模型
然后,训练一个较小的学生模型,目标是通过最小化学生模型与教师模型在相同输入上的输出差异来进行训练。学生模型不仅学习硬标签(真实标签),还学习教师模型的“软标签”。
通过蒸馏,学生模型可以获得教师模型中蕴含的丰富知识,尤其是在教师模型能够捕获的复杂特征和模式方面,从而在保持较小规模的同时接近或达到教师模型的性能。
优缺点
- 优点:蒸馏可以显著提高小型模型的性能,使其在压缩后依然保持接近教师模型的精度,尤其在大型模型压缩时表现出色。
- 缺点:蒸馏的一个挑战是教师模型的选择和训练需要耗费大量的计算资源和时间。此外,蒸馏的效果可能会受到学生模型的限制,对于某些任务,学生模型的性能可能不容易达到教师模型的水平。































